Essence
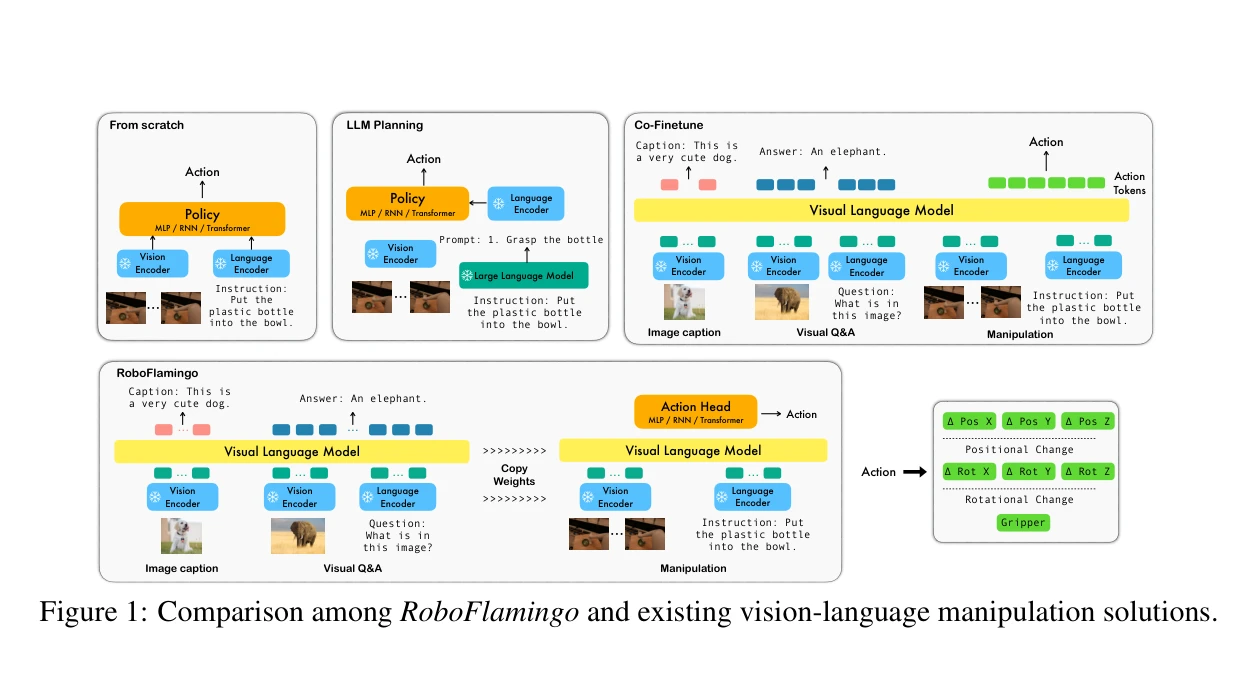
Figure 1: Comparison among RoboFlamingo and existing vision-language manipulation solutions.
RoboFlamingo는 공개 소스 VLM인 OpenFlamingo를 기반으로 하여 로봇 조작 정책을 구축하는 프레임워크로, 시각-언어 이해와 의사결정을 분리하고 최소한의 미세조정으로 높은 성능을 달성한다.
저자: Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, Tao Kong | 날짜: 2023-11-02 | URL: https://arxiv.org/abs/2311.01378 📄 PDF
Figure 1: Comparison among RoboFlamingo and existing vision-language manipulation solutions.
RoboFlamingo는 공개 소스 VLM인 OpenFlamingo를 기반으로 하여 로봇 조작 정책을 구축하는 프레임워크로, 시각-언어 이해와 의사결정을 분리하고 최소한의 미세조정으로 높은 성능을 달성한다.
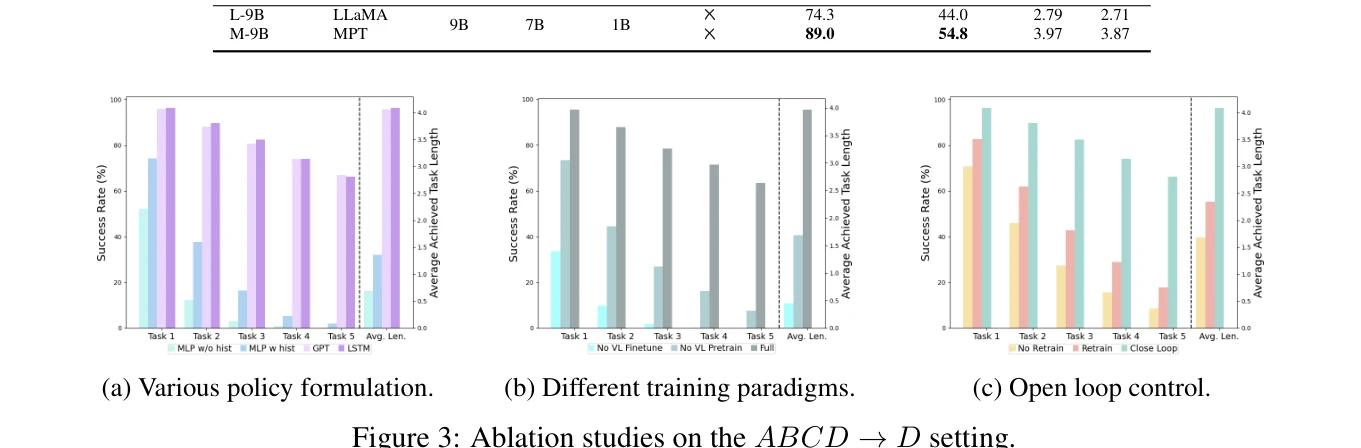
Figure 3: Ablation studies on the ABCD →D setting.
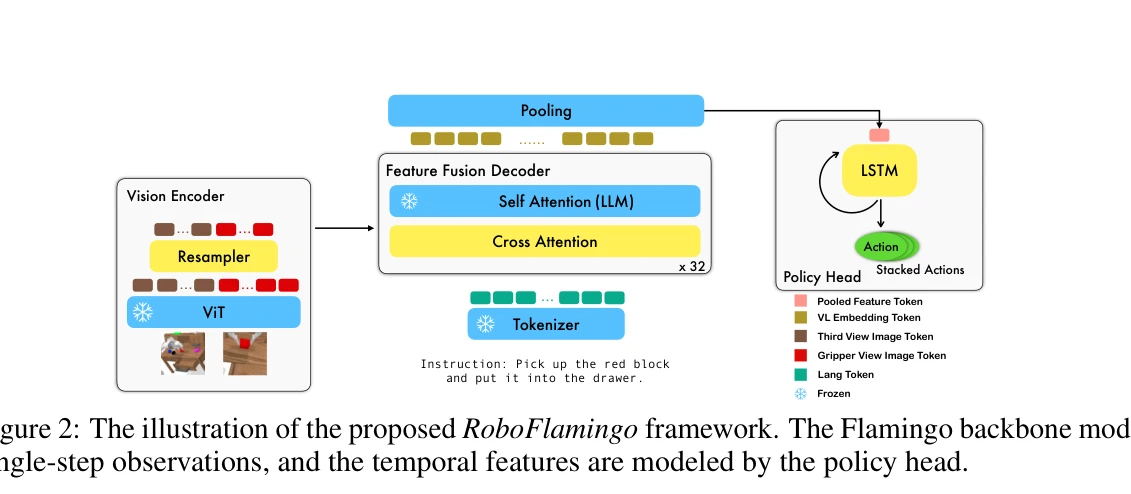
Figure 2: The illustration of the proposed RoboFlamingo framework. The Flamingo backbone models
총평: RoboFlamingo는 공개 소스 VLM을 활용하여 저비용이면서도 높은 성능의 로봇 조작 정책을 구현할 수 있는 효과적인 방법을 제시하며, 시각-언어 이해와 정책 학습의 분리라는 명확한 설계 철학으로 로봇 공학의 민주화에 기여한다.