저자: Xinghang Li, Peiyan Li, Long Qian, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao Ma, Xinlong Wang, Di Guo, Tao Kong, Hanbo Zhang, Huaping Liu | 날짜: 2024-12-18 | URL: https://arxiv.org/abs/2412.14058 📄 PDF
Essence
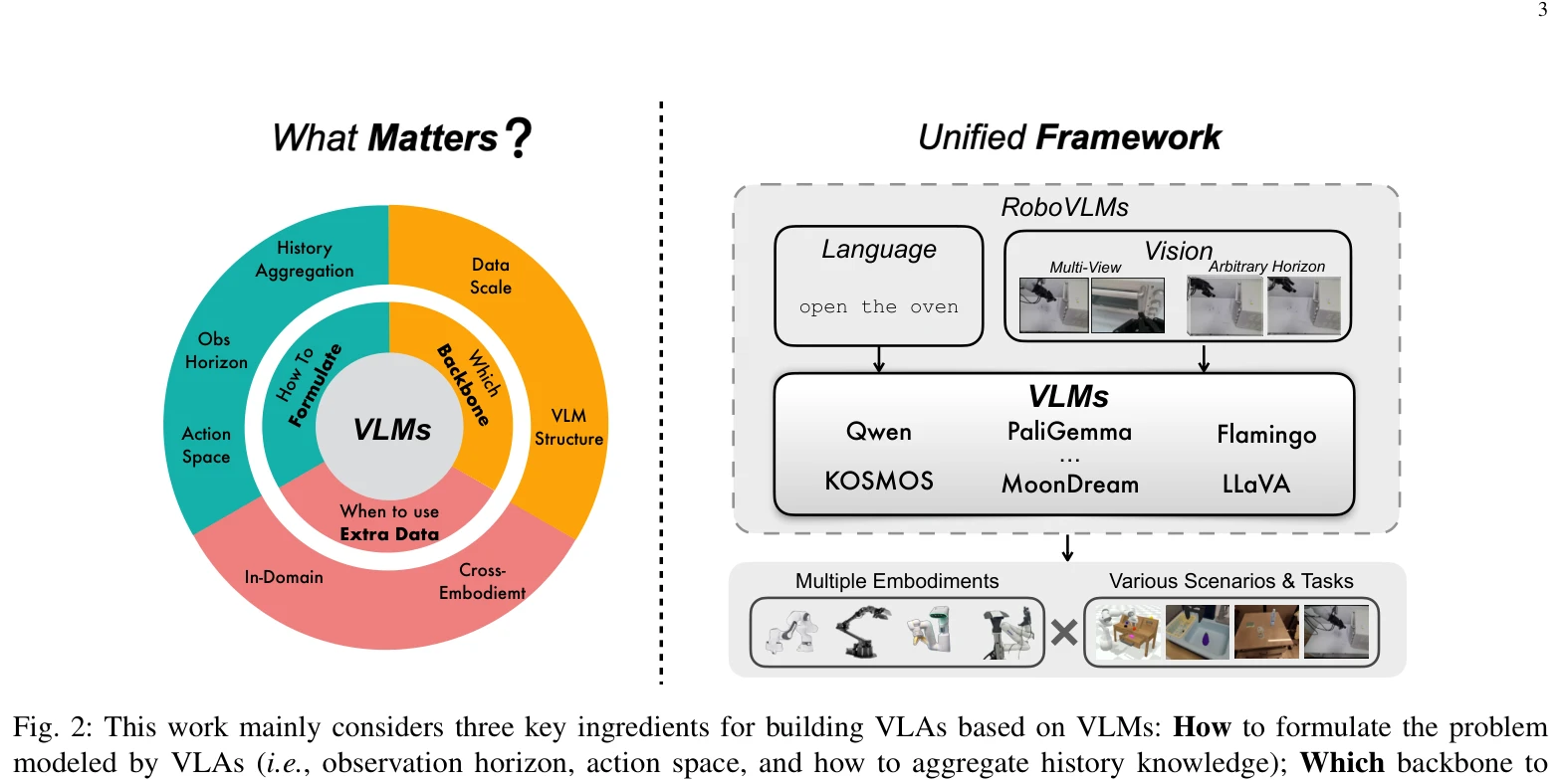
Fig. 2: This work mainly considers three key ingredients for building VLAs based on VLMs: How to formulate the problem
Vision-Language-Action (VLA) 모델 개발 시 VLM 백본 선택, 아키텍처 설계, 데이터 활용 시점이라는 세 가지 핵심 요소를 체계적으로 분석하고, 이를 통해 RoboVLMs 프레임워크를 제안하여 로봇 조작 작업에서 최고 성능을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: VLA 개발의 핵심 설계 요소를 체계적으로 분석한 중요한 메타 연구로, 광범위한 실증 실험을 통해 실질적인 가이드라인을 제시하고 확장 가능한 프레임워크를 제공함으로써 로봇 기초 모델 연구 커뮤니티에 상당한 기여를 할 것으로 예상된다.