Blade: Benchmarking language model agents for data-driven science
저자: Ken Gu, Ruoxi Shang, Ren Jiang, Keying Kuang, Ren Lin | 날짜: 2024 | DOI: arXiv:2408.09667📄 PDF
Essence
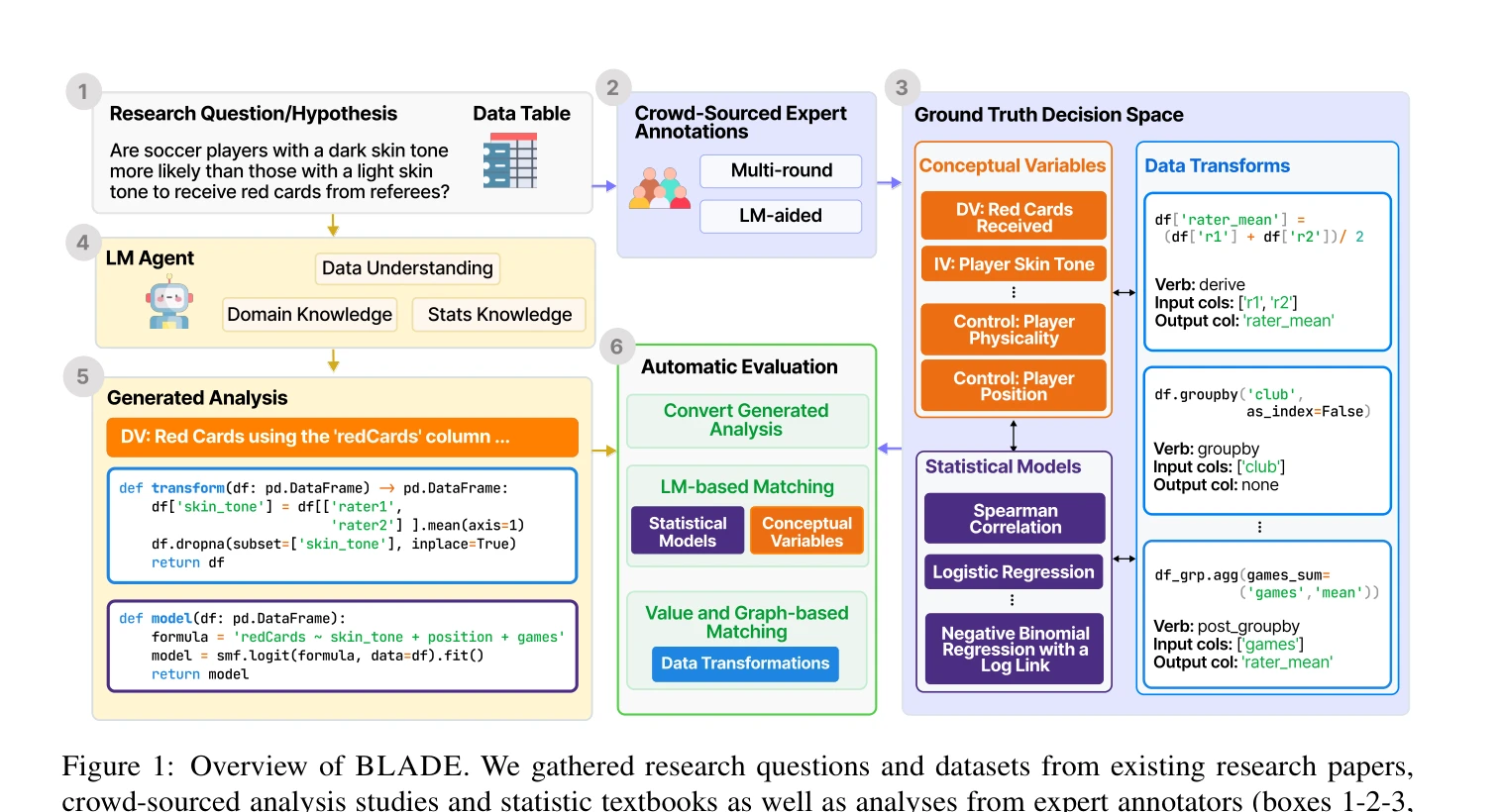
Figure 1: Overview of BLADE. We gathered research questions and datasets from existing research papers,
BLADE는 data-driven science를 수행하는 language model 기반 agents를 평가하기 위한 벤치마크이다. 12개의 데이터셋과 연구 질문에 대해 expert data scientists로부터 수집한 ground truth 분석을 기반으로, agents의 다면적인 분석 접근을 자동으로 평가한다.
Motivation
Known: 기존 data analysis 벤치마크들(MLAgentBench, DABench 등)은 단순한 계산 작업이나 ML 모델 정확도 향상에 초점을 맞추고 있으며, 자동 평가 메커니즘이 제한적이다. 데이터 기반 과학 분석은 외부 과학 지식, 통계 expertise, 데이터 의미론 이해를 통합한 복잡한 multi-step 작업을 요구한다.
Gap: 기존 벤치마크들은 open-ended 과학 분석 질문에 대해 agents를 평가하지 못하며, 특히 (1) 단일 ground truth 설정의 어려움, (2) 이질적인 분석 결정의 표현 방식의 다양성, (3) 다양한 정당한 접근법에 대한 자동 평가 기준의 부재 등을 해결하지 못한다.
Why: LM 기반 agents가 data-driven science를 지원할 수 있는 잠재력을 가지고 있지만, 이들의 성능을 신뢰성 있게 평가할 방법이 없어서 agents의 개선과 발전이 어렵다. 따라서 open-ended 분석 작업의 여러 정당한 접근법을 포용하면서도 자동으로 평가할 수 있는 벤치마크가 필수적이다.
Approach: BLADE는 다음과 같이 구성된다: (1) 기존 연구 논문, crowd-sourced analysis 연구, 통계 교과서로부터 12개의 research question과 dataset을 수집, (2) expert data analysts로부터 multiple independent analyses를 crowd-source하여 다양한 정당한 분석 접근법 수집, (3) conceptual variables, data transformations, statistical models의 세 가지 분석 결정 유형에 대해 ground truth 구축, (4) value/graph 기반 매칭 및 LM 기반 매칭을 포함한 자동 평가 방법 개발
Achievement
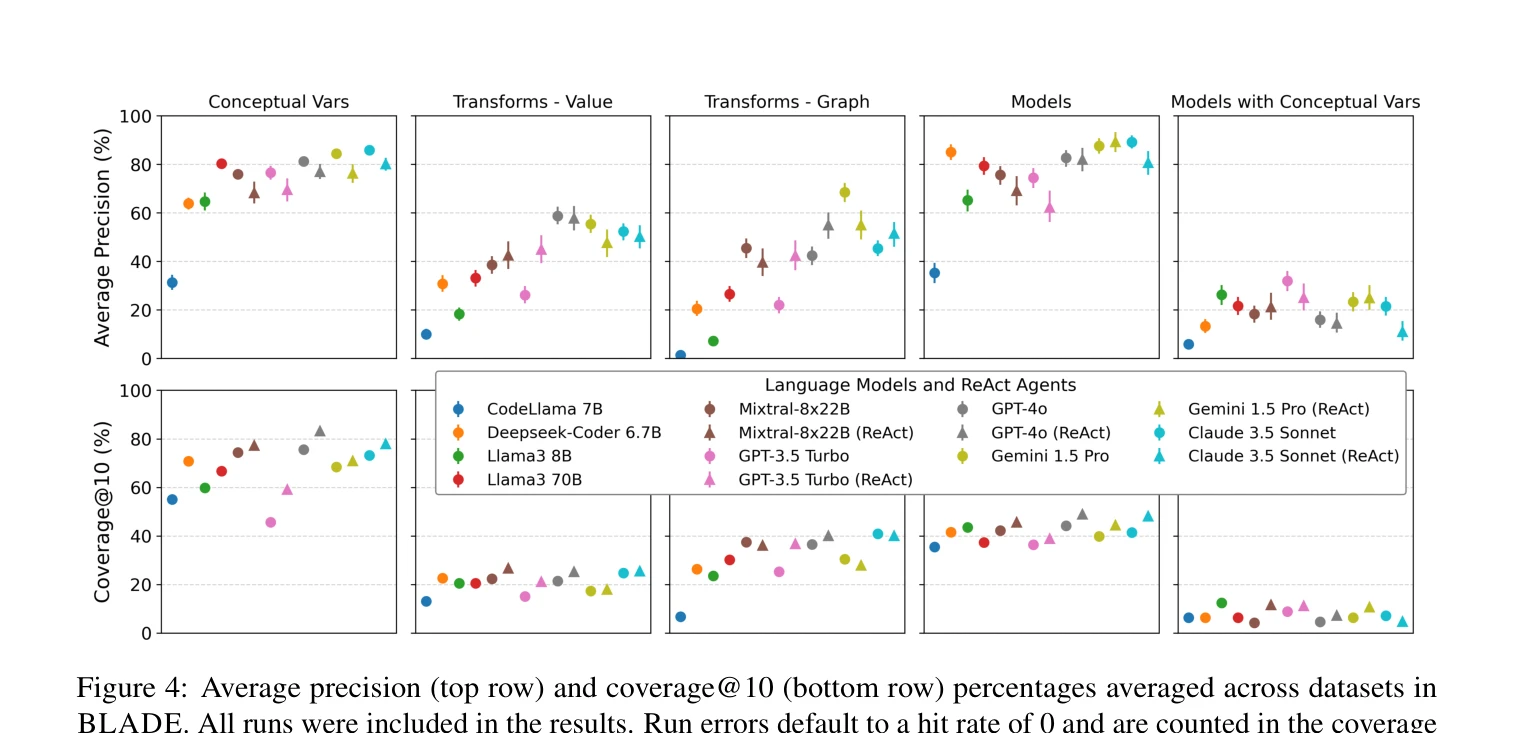
Figure 4: Average precision (top row) and coverage@10 (bottom row) percentages averaged across datasets in
BLADE 벤치마크 구축: 12개의 datasets, 188개의 multiple choice 및 536개의 ground truth 분석 결정으로 구성된 first-of-its-kind 벤치마크 완성. 자동 평가 프레임워크: 다양한 표현 형식의 분석을 매칭하기 위한 value/graph-based matching 및 LM-based matching 방법 개발. 종합 평가 결과: 다양한 LMs와 ReAct agent의 강점과 약점을 체계적으로 분석하여, LMs이 기본 분석에는 적합하지만 conceptual variable formulation (coverage 13% 이하)과 variable operationalization (coverage 27% 이하)에서 큰 한계를 보임을 입증.
How
Figure 1: Overview of BLADE. We gathered research questions and datasets from existing research papers,
• Crowd-sourced expert annotations를 통해 multiple valid analysis approaches를 반영한 포괄적인 ground truth 수집\n• 연구 질문에 대한 alternative decisions validation 및 unjustifiable decisions 포함으로 평가 기준의 건전성 확보\n• Conceptual variables, data transformations, statistical models를 개별적으로 표현하고 평가하기 위한 structured representation 설계\n• Value 기반 매칭(변수명, 수치), graph 기반 매칭(데이터 변환 구조), LM 기반 매칭(의미론적 동등성)을 결합한 다층 매칭 전략\n• ReAct agent를 통한 agents의 실제 성능 측정 및 baseline 제공
Originality
• 새로운 평가 관점: 기존의 단순 작업 기반 벤치마크와 달리 open-ended scientific analysis의 복잡한 decision-making을 evaluation 대상으로 삼음\n• 포괄적 ground truth 설계: crowd-sourced analysis에서 alternative decisions, negative examples까지 체계적으로 수집하여 다양한 정당한 접근법을 인정\n• 다층 자동 평가 메커니즘: 코드 수준(value/graph matching)부터 개념 수준(conceptual variable matching)까지 이질적인 분석 결정을 유연하게 비교\n• 실제 과학 데이터 활용: 교과서나 synthetic 데이터가 아닌 published research papers의 실제 데이터와 질문 사용
Limitation & Further Study
• Ground truth 수집의 스케일 제약: 12개 datasets만 포함되어 있어 benchmark의 generalizability와 coverage가 제한적일 수 있음\n• Expert annotation의 주관성: 어떤 분석 결정이 \"정당한(justifiable)\"인지에 대한 판단이 여전히 expert judgment에 의존\n• 평가 메트릭의 제한: Average precision과 coverage@10 중심의 평가로 agents의 분석 품질이나 scientific validity에 대한 더 깊은 통찰이 부족할 수 있음\n• LM agents의 성능 평가 다양성 부족: ReAct agent 외 다른 agent 아키텍처나 더 새로운 LM들(GPT-4o, Claude 3 등)에 대한 평가 부재\n• Data semantics 이해의 한계: benchmark가 agents의 domain-specific data 이해도를 충분히 테스트하지 못할 가능성\n\n후속 연구 방향:\n• 더 많은 domains와 datasets를 포함한 benchmark 확장\n• Agent의 분석 과정의 interpretability와 scientific validity에 대한 더 깊은 분석\n• 다양한 agent architectures와 최신 LMs에 대한 평가 추가\n• Human-in-the-loop evaluation을 통한 agents의 실제 과학적 가치 검증
총평: BLADE는 data-driven science에서 LM agents를 평가하기 위한 첫 번째 종합적이고 원칙적인 벤치마크로서, open-ended 분석 작업의 복잡성을 다층적 자동 평가 방법으로 처리한다는 점에서 의의가 크다. 실제 논문 데이터와 expert crowd-sourced annotations를 기반으로 한 견고한 ground truth 구축과 세밀한 decision-level evaluation은 agents의 실제 analytical capabilities를 파악하는 데 중요한 기여를 한다. 다만 12개 dataset의 제한적 규모와 ReAct 외 다양한 agent architectures의 부재는 향후 개선이 필요한 부분이다.