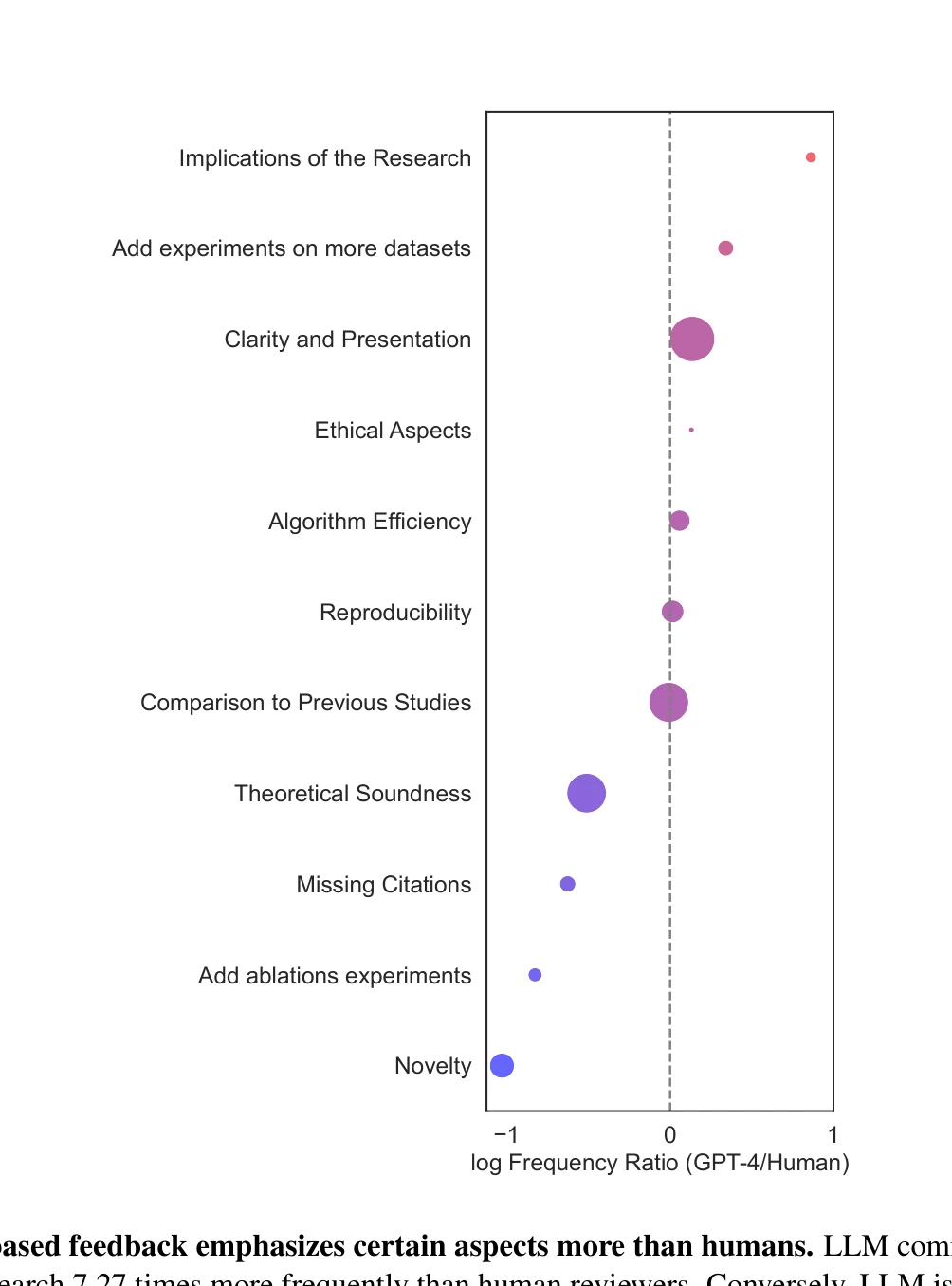
Essence
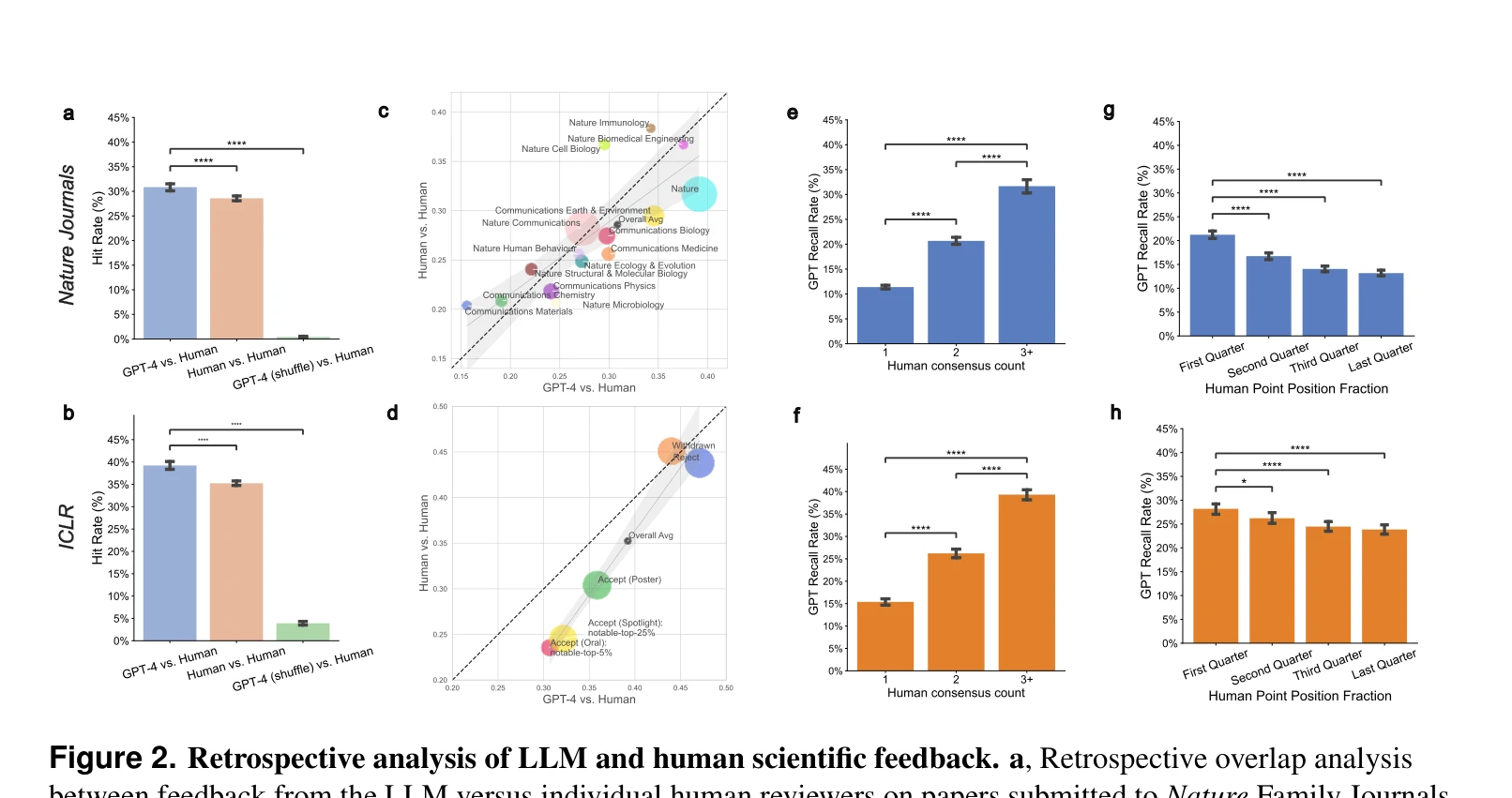
Figure 2. Retrospective analysis of LLM and human scientific feedback. a, Retrospective overlap analysis
본 논문은 GPT-4를 이용하여 과학 논문에 대한 피드백을 자동으로 생성할 수 있는지 체계적으로 분석하는 연구이다. Nature 저널 및 ICLR 학회의 3,096개 및 1,709개 논문을 대상으로 LLM과 인간 리뷰어의 피드백 겹침을 비교했으며, 308명의 연구자 대상 사용자 조사를 통해 LLM 피드백의 유용성을 평가했다.
Achievement

Figure 1. Characterizing the capability of LLM in providing helpful feedback to researchers. a, Pipeline for
LLM-인간 피드백 겹침: Nature 저널 평균 30.85%, ICLR 평균 39.23%로 인간 리뷰어 간 겹침(Nature 28.58%, ICLR 35.25%)과 유사함. 사용자 인식: 57.4%의 연구자가 GPT-4 피드백을 도움/매우 도움이 된다고 평가했으며, 82.4%는 일부 인간 리뷰어보다 더 유용하다고 판단. 약한 논문에 대한 성능: 거절된 ICLR 논문에서 겹침이 43.80%로 높아 LLM이 lower-quality 논문 식별에 더 효과적.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 5/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM이 과학 피드백 생성에서 실질적인 가치를 제공할 수 있음을 대규모 실증 데이터로 처음 보여준 중요한 기여이다. 인간 리뷰어와의 비교 분석이 체계적이고, 사용자 조사가 현실적 유용성을 강화하나, LLM의 방법론적 약점과 주제 편향에 대한 해결책이 제시되지 않아 실무 적용에는 제약이 있다.
같이 보면 좋은 논문
기반 연구
712의 SciCode 벤치마크는 184의 논문과 같이 LLM이 실제 연구 지원(피드백, 코딩 등) 역할을 평가하는 근거 자료가 된다.
기반 연구
RAG 기반 텍스트 생성의 이론적 기반을 제공하는 선행 연구이다.
다른 접근
184는 LLM이 논문 리뷰에 얼마나 유용한 피드백을 제공하는지에 대한 또다른 평가 논문으로, 1087과 상호보완적으로 읽을 수 있습니다.
다른 접근
LLM을 활용한 학술 논문 평가 및 피드백 생성 능력을 연구하는 유사한 접근 방식을 취한다.
다른 접근
LLM의 과학적 텍스트 평가 능력을 분석하는 관련 연구이다.
다른 접근
LLM이 학술 피어 리뷰에서 유용한 피드백을 줄 수 있는지 실증적으로 검증하여, 104번 논문의 보안 위험 논의와 상반되는 시각을 제시합니다.
다른 접근
LLM이 논문 및 연구 평가 과정에서 인간 심사자에 비해 질적 피드백을 어떻게 제공하는지를 비교 분석하여, 인간/AI 비교의 다변화된 시각을 준다.
다른 접근
AI 기반 학술 리뷰 시스템의 효용성을 평가하는 유사한 연구이다.
다른 접근
GPT 모델을 활용한 텍스트 평가 작업의 성능을 비교하는 유사한 연구이다.
다른 접근
AI가 생성한 리뷰가 실제 평가에 얼마나 적합한지, 다양한 평가 프레임워크를 통해 검증한다.
후속 연구
184 논문은 LLM이 논문 피드백 및 리뷰에 실질적 도움을 주는지 다각도로 검증해, 227에서 제안한 자동화 피드백 시스템의 실효성을 평가한다.
후속 연구
Peer Review as A Multi-Turn Dialogue 논문은 LLM 기반 리뷰를 다중턴 대화 관점으로 분석하여 실제 적용성 논의를 확장합니다.
후속 연구
LLM을 활용한 논문 리뷰 평가의 확장성과 활용에 대하여 규모 및 실제성 차원의 분석을 더한다.
후속 연구
LLM을 활용한 연구 논문 피드백 생성 시스템을 확장하는 관련 연구이다.
후속 연구
Can large language models provide useful feedback on research 논문은 실제 LLM의 리뷰 비판 및 피드백 능력에 관한 평가로, AAAR-1.0 벤치마크의 실제 평가 항목을 확장한다.
응용 사례
CoAuthor 논문은 실제 논문 집필 시 LLM의 협력적 피드백과 집필 지원 역량을 대규모 데이터로 분석해, 피어 리뷰 단계뿐 아니라 작성 과정상의 LLM 피드백 시사점을 제시한다.
반론/비판
104번 논문은 LLM이 피어 리뷰에서 보일 수 있는 위험과 취약성을 다루는 반대 관점입니다.
반론/비판
184번 논문은 LLM이 과학 문헌에 줄 수 있는 피드백의 한계와 활용결과를 평가하여, 530번 논문에서 제시한 QA 성능 개선 주장에 대한 비판적 시각을 제공합니다.