Essence
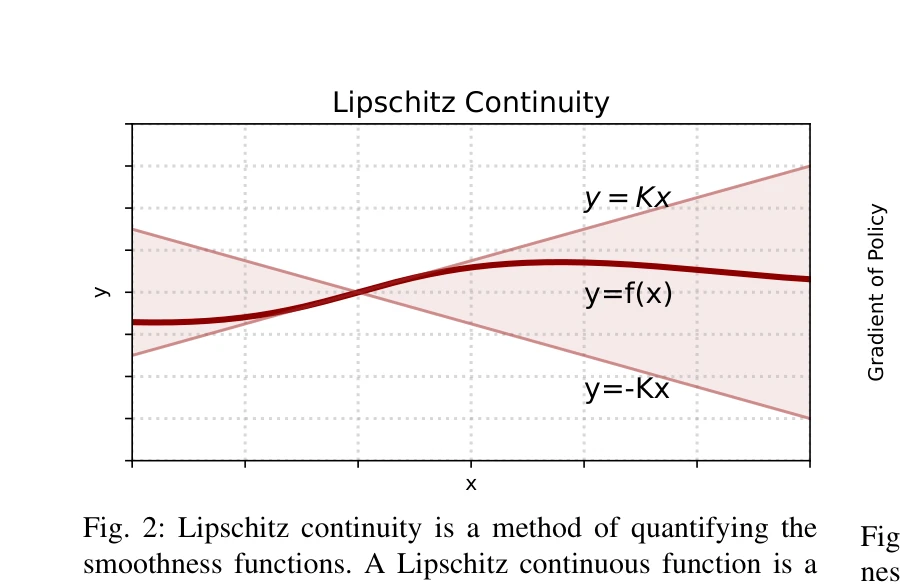
Fig. 2: Lipschitz continuity is a method of quantifying the
본 논문은 Reinforcement Learning으로 훈련한 humanoid robot의 locomotion policy에 Lipschitz 제약을 부여하여 smooth behavior를 자동으로 유도하는 Lipschitz-Constrained Policies (LCP) 방법을 제안한다.
저자: Zixuan Chen, Xialin He, Yen-Jen Wang, Qiayuan Liao, Yanjie Ze, Zhongyu Li, S. Shankar Sastry, Jiajun Wu, Koushil Sreenath, Saurabh Gupta, Xue Bin Peng | 날짜: 2024-10-15 | URL: https://arxiv.org/abs/2410.11825 📄 PDF
Fig. 2: Lipschitz continuity is a method of quantifying the
본 논문은 Reinforcement Learning으로 훈련한 humanoid robot의 locomotion policy에 Lipschitz 제약을 부여하여 smooth behavior를 자동으로 유도하는 Lipschitz-Constrained Policies (LCP) 방법을 제안한다.

Fig. 1: Lipschitz-constrained policies (LCP) provide a simple and general method for training policies to produce smooth
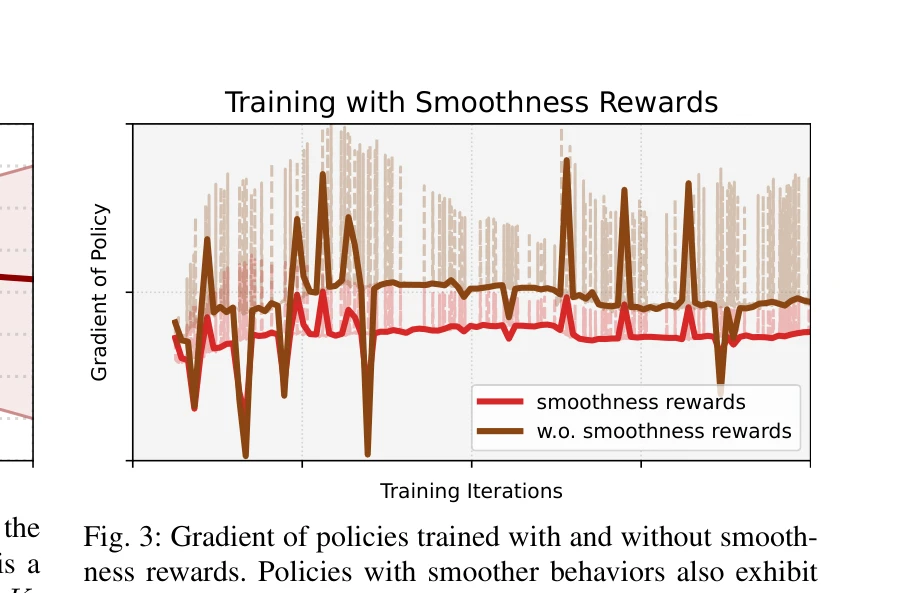
Fig. 3: Gradient of policies trained with and without smooth-
총평: Lipschitz constraint을 통한 smooth policy 학습은 이론적으로 명확하고 실용적이며, 기존의 복잡한 smoothing 기법들을 단순하고 미분 가능한 방식으로 대체하는 우수한 기여이다. 실제 humanoid robot에서의 검증과 재현성 있는 공개 코드 공개로 high impact을 기대할 수 있다.