Essence
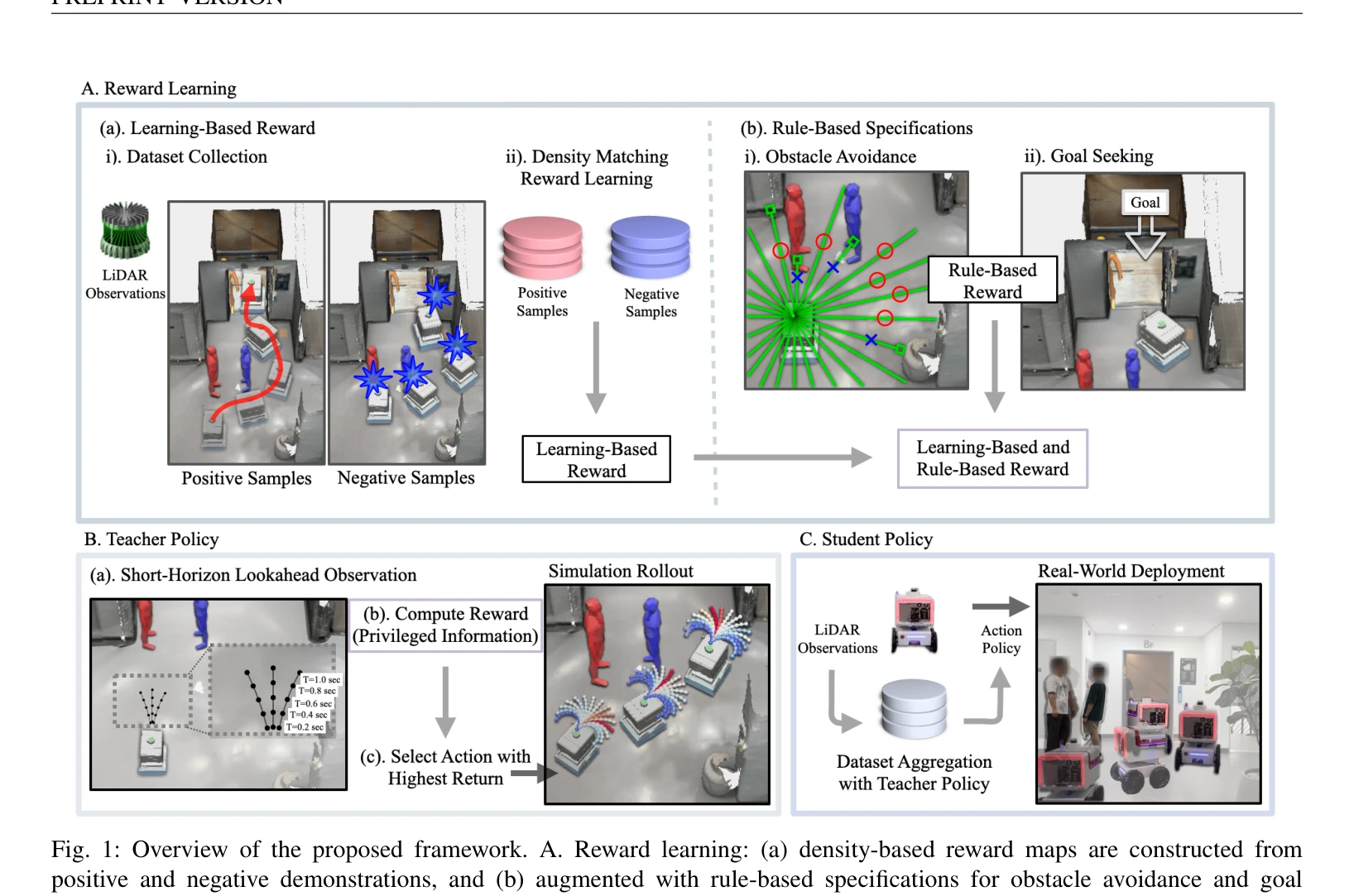
Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from
본 논문은 긍정적 및 부정적 시연과 규칙 기반 명세로부터 학습한 밀도 기반 보상을 결합하여 동적 인간 환경에서 안전성과 적응성의 균형을 맞춘 모바일 로봇 네비게이션 정책을 개발한다.
저자: Chanwoo Kim, Jihwan Yoon, Hyeonseong Kim, Taemoon Jeong, Changwoo Yoo, Seungbeen Lee, Soohwan Byeon, Hoon Chung, Matthew Pan, Jean Oh, Kyungjae Lee, Sungjoon Choi | 날짜: 2025-10-14 | URL: https://arxiv.org/abs/2510.12215 📄 PDF
Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from
본 논문은 긍정적 및 부정적 시연과 규칙 기반 명세로부터 학습한 밀도 기반 보상을 결합하여 동적 인간 환경에서 안전성과 적응성의 균형을 맞춘 모바일 로봇 네비게이션 정책을 개발한다.
Fig. 1: Overview of the proposed framework. A. Reward learning: (a) density-based reward maps are constructed from
총평: 본 논문은 데이터 기반 보상과 규칙 기반 안전 명제의 효과적인 통합을 통해 동적 인간 환경에서의 로봇 네비게이션을 다루는 실용적이고 신뢰할 수 있는 해결책을 제시하며, teacher-student 증류 및 불확실성 추정 기법을 포함한 방법론적 기여와 함께 실제 인간 참여자 실험으로 검증한 점에서 높은 가치를 갖는다.