Essence
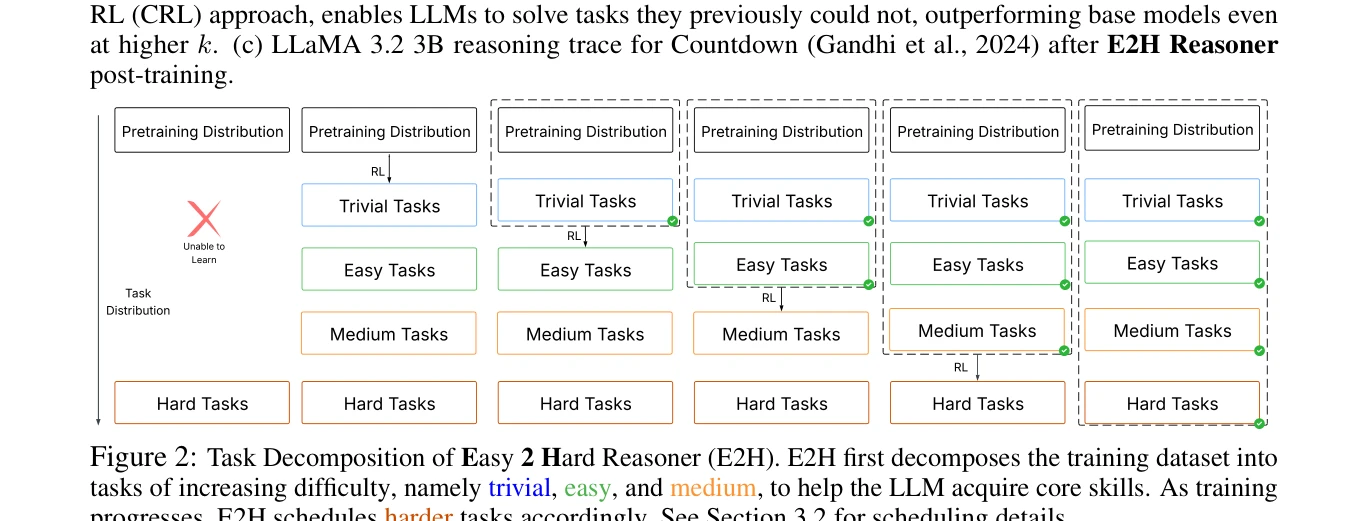
E2H Reasoner의 작업 분해: 학습이 진행됨에 따라 자명(Trivial) → 쉬움(Easy) → 중간(Medium) → 어려움(Hard) 작업으로 점진적 전환
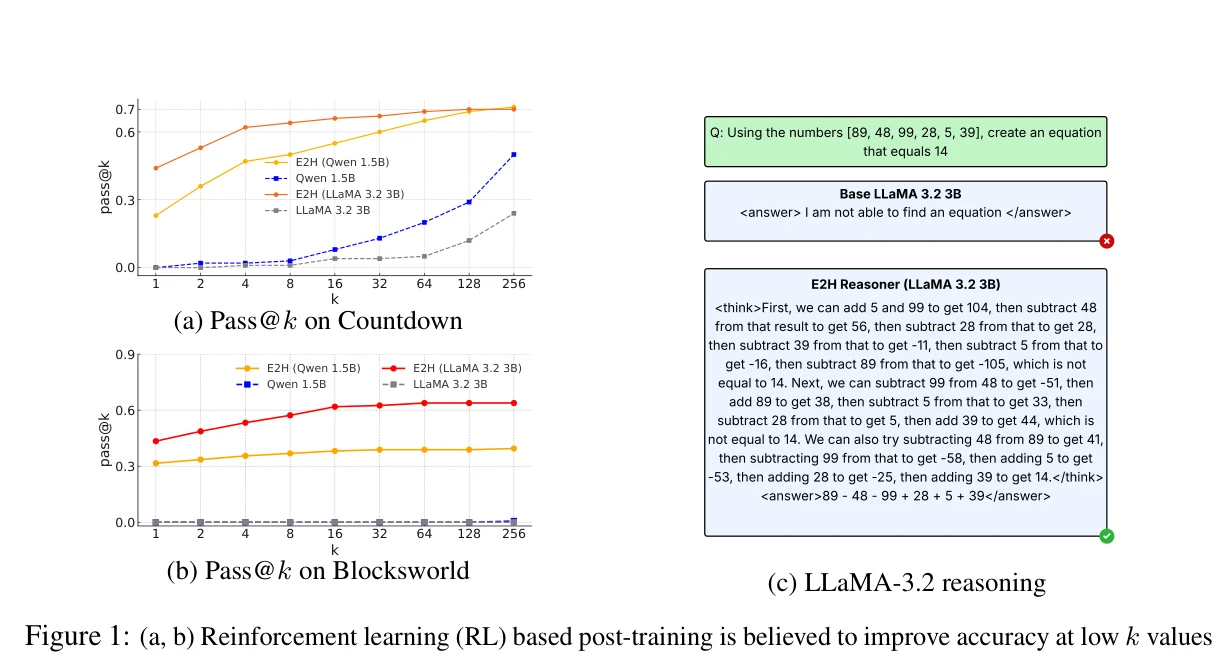
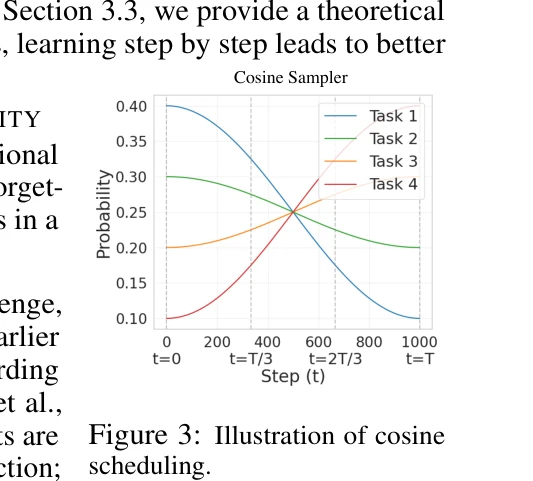
본 논문은 대규모 언어모델(LLM)의 추론 능력을 강화학습(RL)과 커리큘럼 학습을 결합하여 개선하는 E2H Reasoner 방법을 제시한다. 작업을 난이도별로 분해하고 확률적 스케줄러를 통해 쉬운 작업에서 어려운 작업으로 점진적 학습을 수행함으로써, 단순 RL만으로는 해결 불가능한 추론 문제를 학습 가능하게 한다.