Essence
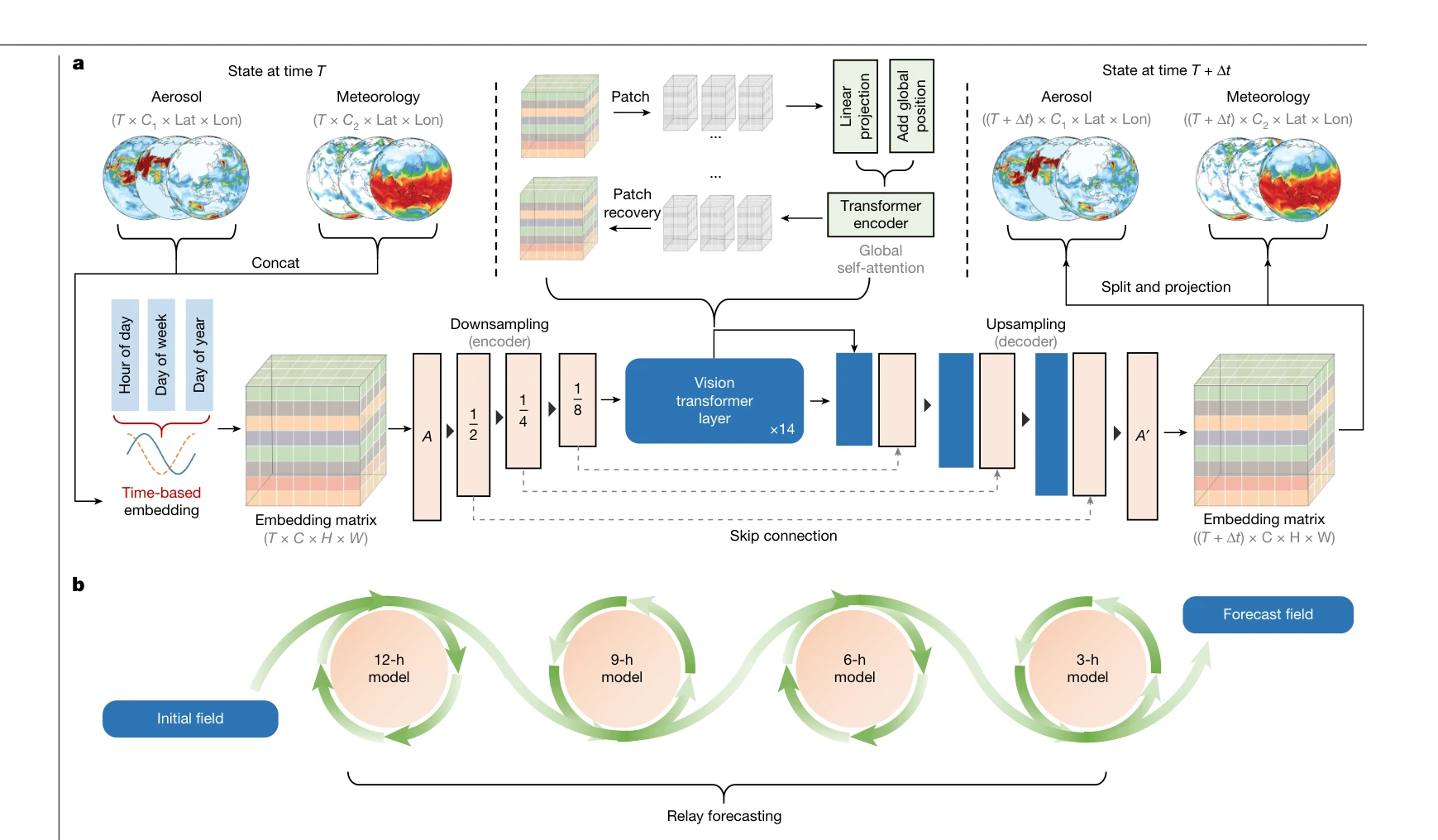
Fig. 1 | Architecture of the machine-learning-driven AI-GAMFS. a, The
Vision Transformer와 U-Net을 결합한 AI-GAMFS를 제안하여 42년 에어로졸 재분석 데이터로 학습한 후, 5일·3시간 단위 전역 에어로졸 광학 성분 및 표면 농도를 1분 안에 예보하며 기존 CAMS 및 지역 먼지 모델을 능가하는 성능을 달성한다.
저자: Ke Gui, Xutao Zhang, Huizheng Che, Lei Li, Yu Zheng, Linchang An, Yucong Miao, Hujia Zhao, Oleg Dubovik, Brent Holben, Jun Wang, Pawan Gupta, Elena S. Lind, Carlos Toledano, Hong Wang, Zhili Wang, Yaqiang Wang, Xiaomeng Huang, Kan Dai, Xiangao Xia, Xiaofeng Xu, Xiaoye Zhang | 날짜: 2026-03-19 | DOI: 10.1038/s41586-026-10234-y 📄 PDF
Fig. 1 | Architecture of the machine-learning-driven AI-GAMFS. a, The
Vision Transformer와 U-Net을 결합한 AI-GAMFS를 제안하여 42년 에어로졸 재분석 데이터로 학습한 후, 5일·3시간 단위 전역 에어로졸 광학 성분 및 표면 농도를 1분 안에 예보하며 기존 CAMS 및 지역 먼지 모델을 능가하는 성능을 달성한다.
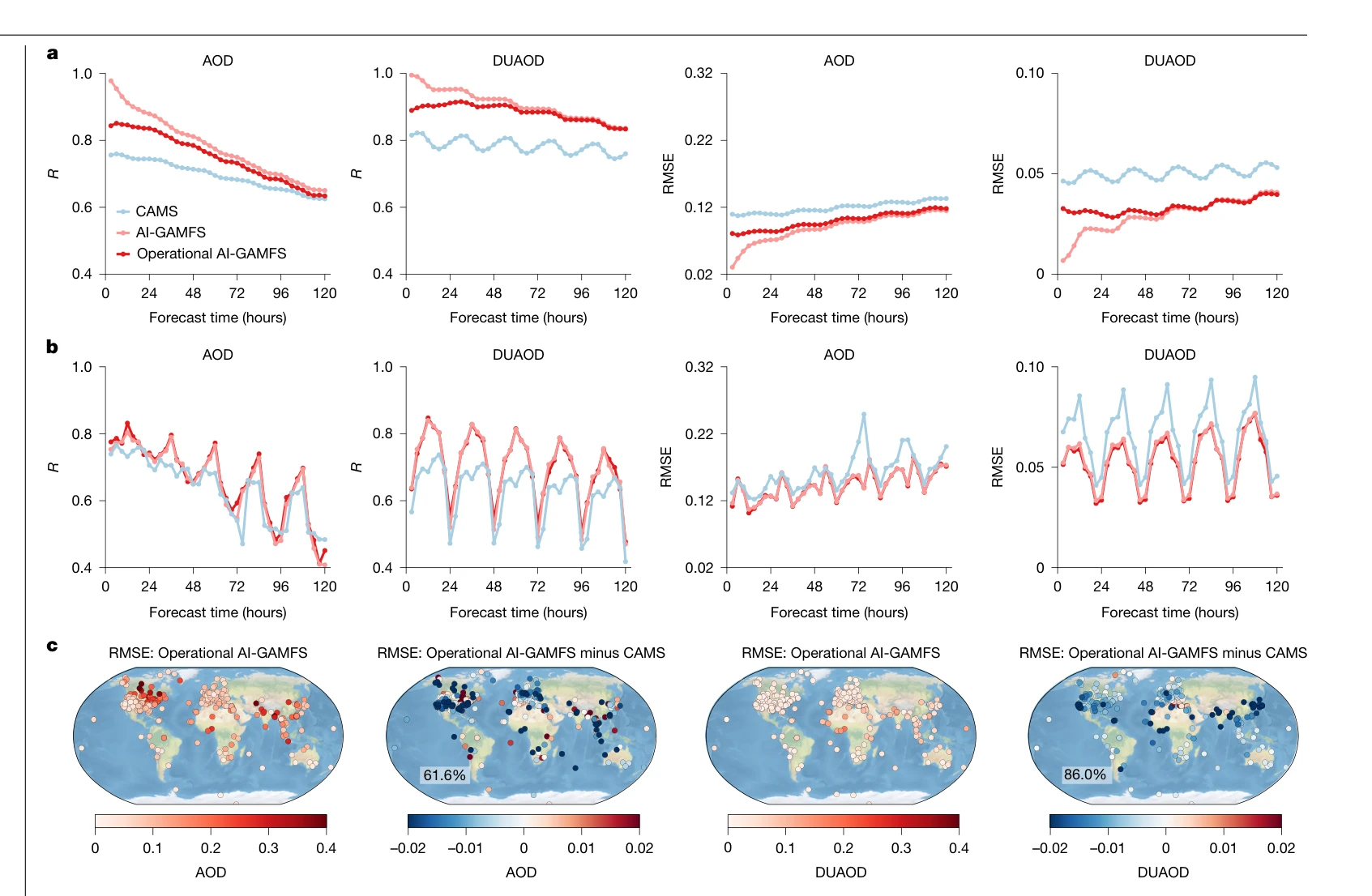
Fig. 2 | Superior performance of AI-GAMFS in global AOD and DUAOD
Fig. 1 | Architecture of the machine-learning-driven AI-GAMFS. a, The
총평: Vision Transformer와 U-Net의 창의적 결합, 42년 데이터 기반의 포괄적 학습, 그리고 relay forecasting을 통한 오차 축적 해결로 전역 에어로졸 예보의 정확도와 효율성을 동시에 혁신적으로 향상시킨 고도의 기술적·실무적 성과를 달성한 논문이다.