저자: Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder | 날짜: 2021 | DOI: N/A 📄 PDF
Essence
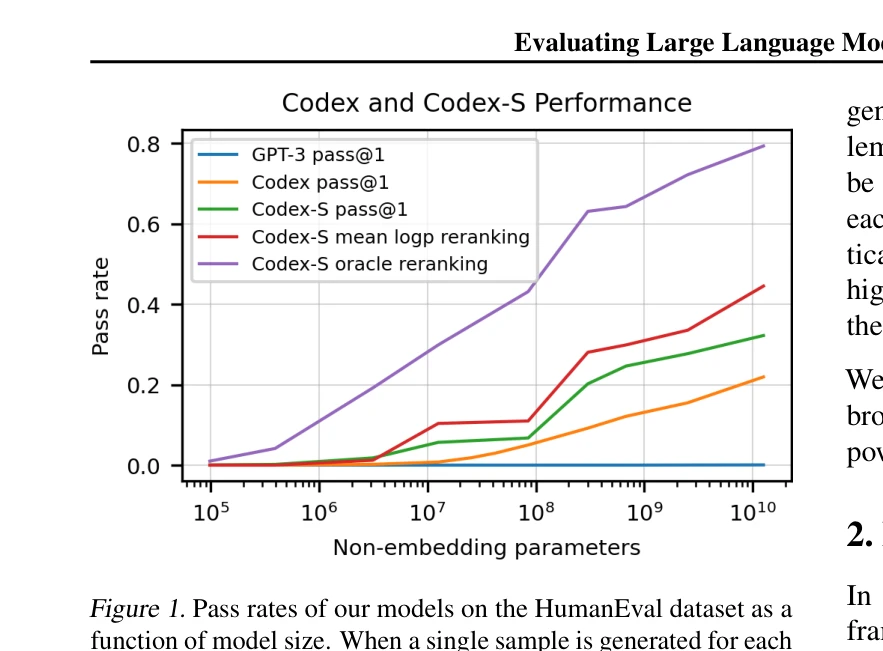
HumanEval 데이터셋에서 모델 크기에 따른 통과율. 단일 샘플 생성 시 Codex-12B는 28.8%, 100개 샘플 생성 후 단위 테스트 통과 샘플 선택 시 77.5% 달성
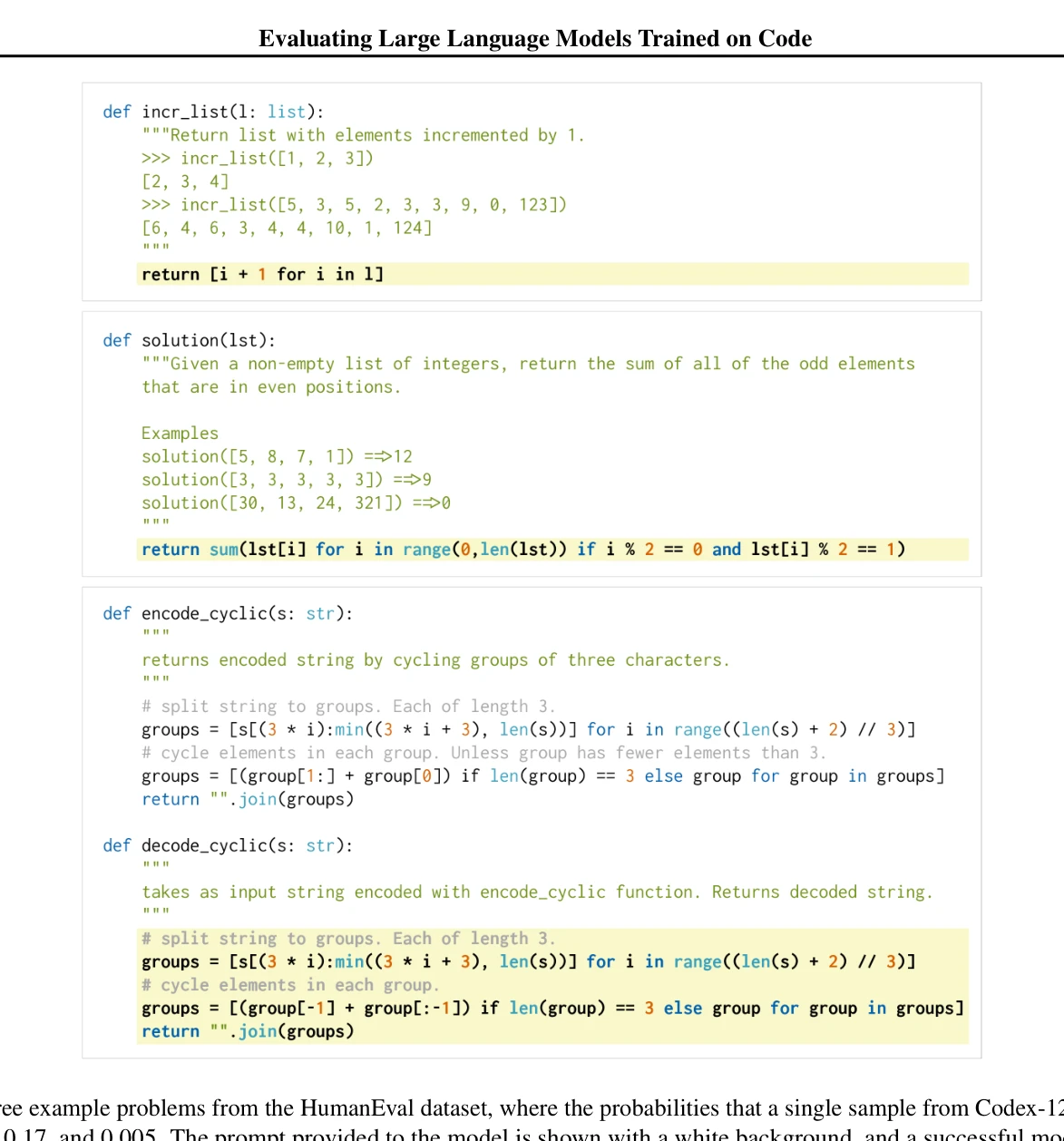
GitHub 코드로 미세조정된 GPT 기반의 Codex 모델을 제시하고, 새로운 벤치마크인 HumanEval을 통해 함수형 정확성(functional correctness) 기반의 평가 체계를 제안한 논문이다. Codex는 도큐스트링(docstring)으로부터 Python 함수를 생성하는 능력에서 기존 모델들을 크게 능가한다.
How
- 데이터 수집: 2020년 5월 GitHub의 5,400만 공개 저장소에서 수집한 Python 파일(179GB → 필터링 후 159GB). 자동 생성 파일, 장행 코드 제거.
- 미세조정 전략: GPT-3 모델 계열에서 출발(더 빠른 수렴). 사전학습된 자연어 표현 활용이지만, 미세조정 데이터셋 규모가 충분히 크면 성능 향상 제약.
- Codex-S: 올바르게 구현된 독립형 함수(standalone functions)로 추가 미세조정하여 37.7% 해결률 달성 - 도메인 특화의 효과 입증.
- Pass@k 계산:
```
pass@k = 1 - ∏(1 - k/(n-c+i)) for i=1 to k
```
여기서 n=생성 샘플 수, c=정답 샘플 수. 단순 추정 1-(1-p̂)^k는 편향됨을 증명.
- 보안 샌드박스: gVisor 컨테이너 런타임으로 호스트 리소스 에뮬레이션, eBPF 방화벽으로 악의적 네트워크 접근 차단.
같이 보면 좋은 논문
기반 연구
코드 관련 LLM HumanEval 벤치마크와 유사하게, SciBench도 고등수준 과학문제 해결능력을 계량화함으로써 LLM 평가 벤치마크의 원리와 활용을 공유합니다.
기반 연구
GPT-4 기반 에이전트의 자기 반성 및 문제 해결 메커니즘의 이론적 기반을 제공한다.
기반 연구
코드 생성 언어모델 평가에서 HumanEval 벤치마크는 SciCode 과학자 큐레이션 코딩문제 데이터셋 개발의 이론적·실용적 기반이 됩니다.
기반 연구
320번 논문은 LLM 기반 코드 및 소프트웨어 벤치마크의 설계와 평가 원리를 다루며 782번 SWE-bench와 비교분석에 유용하다.
기반 연구
320번 논문은 코드 기반 대형언어모델 평가와 AI 모델의 내재 특성 진단을 다루어, 3282번의 파운데이션 모델 내부 표현 분석 기법과 이론적으로 연결됩니다.
기반 연구
320 논문은 코드 학습 기반 모델의 실질 성능 평가로, 3033과 같은 복잡한 실험 최적화 작업에 활용된 대형 LLM의 신뢰성 기반을 제공한다.
다른 접근
두 논문은 동일한 Codex/HumanEval 연구를 다루며, 코드 LLM 평가의 시초로서 함께 읽어야 한다.
다른 접근
코드 특화 언어 모델 개발에서 유사한 문제를 다른 방법론으로 해결하는 연구이다.
다른 접근
차트 이해를 위한 자동화된 데이터 생성 및 모델 학습 방법론을 제안하는 유사한 연구이다.
다른 접근
320 논문은 코드 기반 LLM의 학습 및 평가를 체계적으로 분석하여 LLM self-debugging의 효과와 한계를 비교해볼 수 있습니다.
다른 접근
AI 코드 생성 도구가 소프트웨어 보안에 미치는 영향을 평가하는 유사한 실험적 연구이다.
다른 접근
320은 코드 기반 LLM의 평가와 역할에 중점을 두며, 723에서 언급한 다양한 기반 LLM 평가의 한 갈래를 보여줍니다.
다른 접근
Evaluating large language models trained on code 논문은 LLM이 논문 기반 알고리즘에서 새로운 코드 생성 작업을 해결하는 역량을 측정하는 대안적 접근을 취합니다.
다른 접근
320은 다양한 코드 LLM들의 비교 평가를 제공, 741이 제시하는 code curation을 통한 성능 개선의 실제적 효과를 확인할 수 있습니다.
후속 연구
StarCoder는 Codex 이후 오픈소스 코드 LLM의 발전을 대표하며, HumanEval 벤치마크 기반 평가 체계가 어떻게 발전했는지 보여준다.
후속 연구
Qwen2.5의 코드 학습 성능, 사후 튜닝이 실제 코드 학습벤치마크에서 어느정도 영향 주는지 평가할 수 있다.
후속 연구
SciCode는 과학 연구 코딩 능력을 평가하는 고난도 벤치마크로, HumanEval의 기본 코드 생성 평가를 과학 연구 영역으로 확장한다.
응용 사례
SWE-bench는 LLM의 소프트웨어 실전 이슈 해결 능력을 평가하는 실제적 벤치마크로, 코드 생성 평가체계의 신규 응용사례다.