Essence
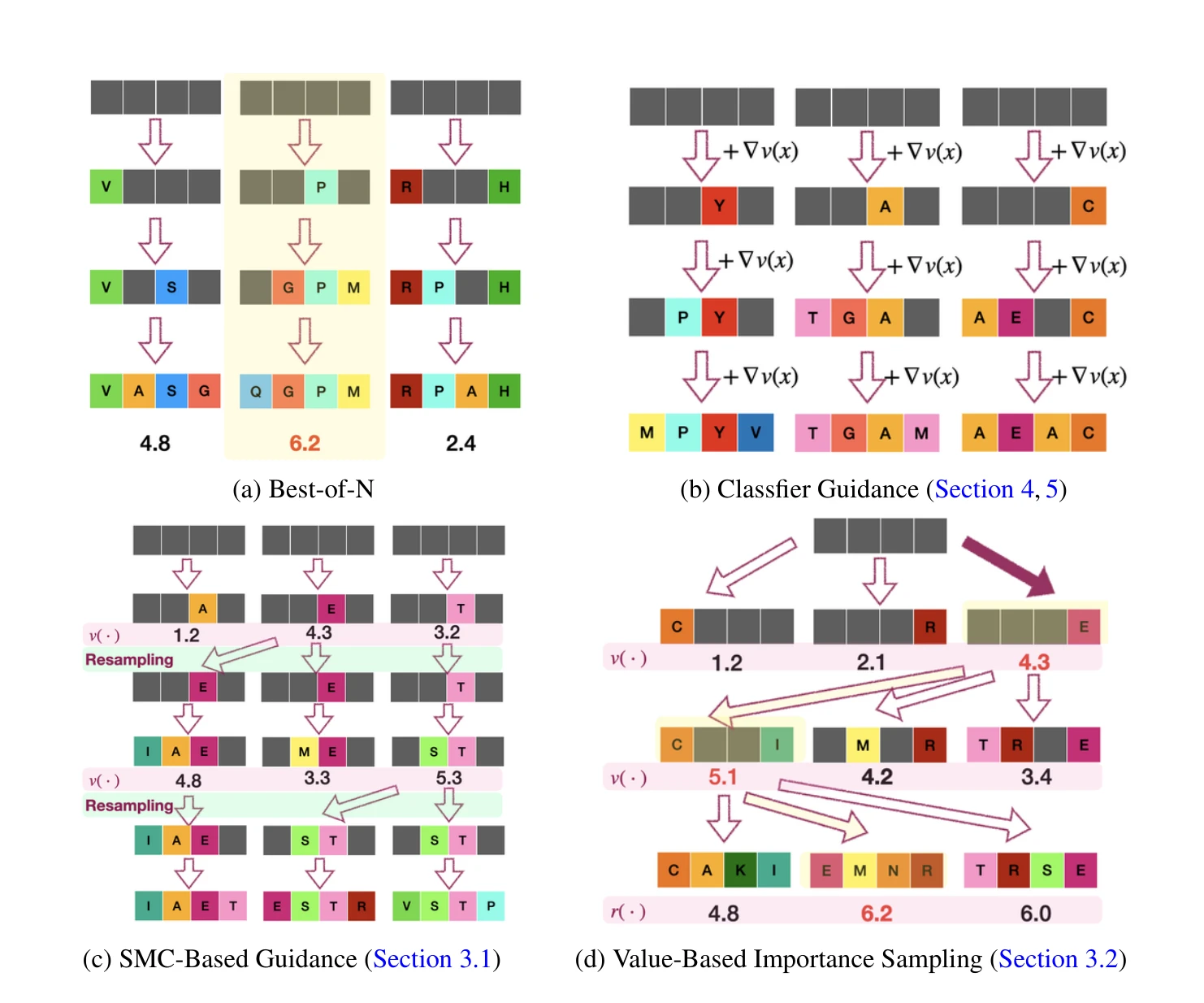
Figure 2: 최적화 목표 달성을 위한 다양한 추론 시간 기법들 (Best-of-N, 분류기 가이던스, SMC 기반 가이던스, 값 기반 중요도 샘플링)
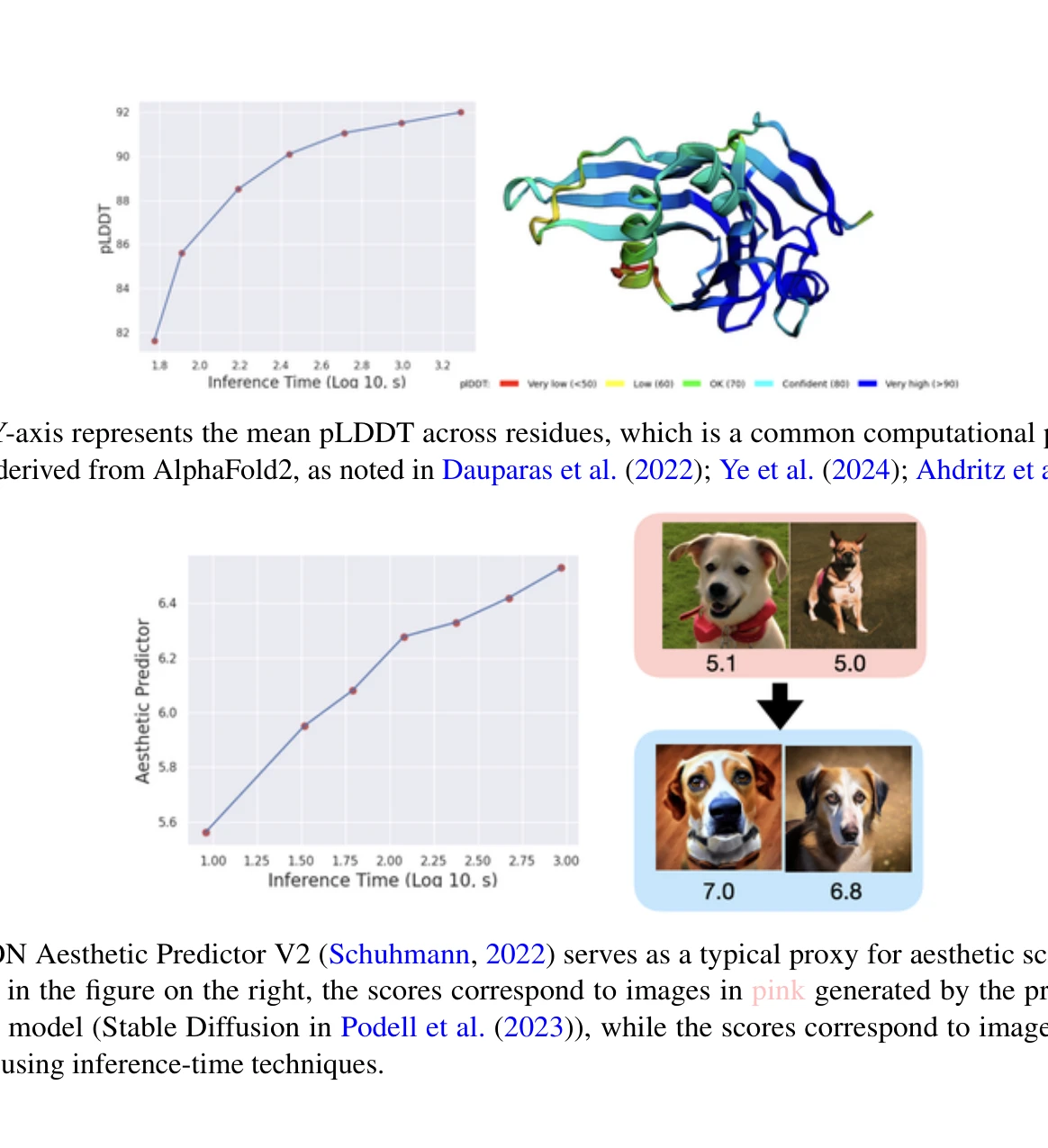
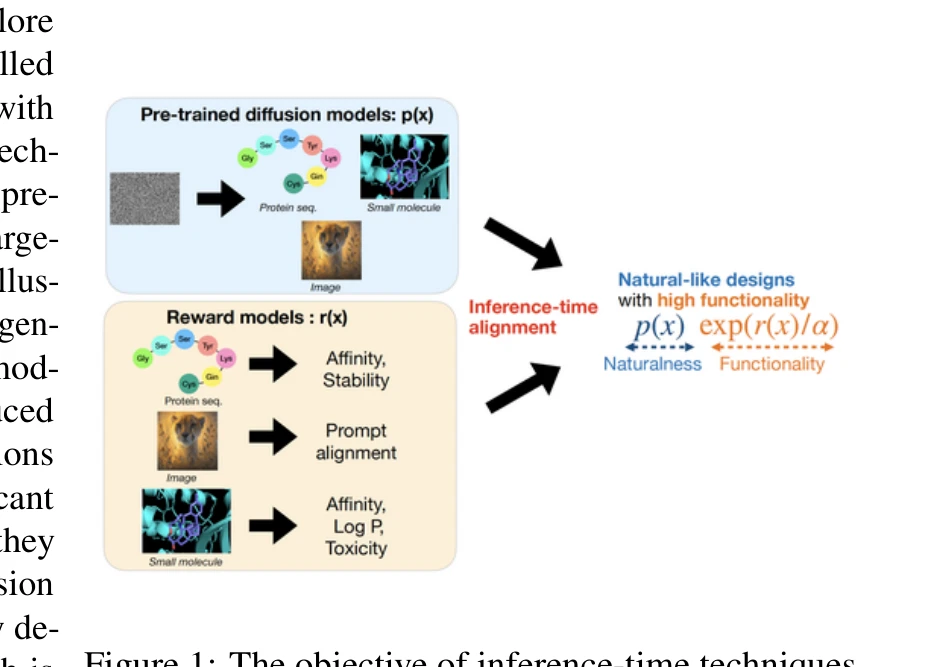
본 튜토리얼은 사전학습된 확산 모델을 미세조정하지 않으면서 추론 시간(inference time)에 보상 함수(reward function)를 최대화하는 정렬(alignment) 기법들을 통일된 관점에서 리뷰하고, 단백질 설계 같은 과학 분야에서 실제로 유용한 비미분 가능한 보상 피드백을 다루는 방법론들을 포괄적으로 다룬다.
Evaluation
총평: 본 튜토리얼은 확산 모델의 추론 시간 정렬 기법들을 처음으로 체계적으로 통합하는 시도로서, 특히 비미분 보상이 실제인 과학 도메인의 관점에서 현실적 가치가 높으며, 제시된 프레임워크는 향후 연구의 이론적 기초가 될 수 있다. 다만 각 기법의 근사 품질, 수렴성, 값 함수 오차의 영향 등에 대한 정량적 이론 분석이 보강된다면 더욱 강력한 참고 자료가 될 것이다.
같이 보면 좋은 논문
기반 연구
682의 확산모델 보상 유도 반복개선은 428의 reward-guided alignment 방식의 이론적·기술적 연장선에 있습니다.
기반 연구
결정 구조 생성(특히 결정을 분할해 생성)에서 대칭성 기반 생성 알고리즘의 이론적 기반을 보여줘, 보상 기반 diffusion 모델 정렬 기법의 적용성을 확장합니다.
다른 접근
Derivative-Free Guidance in Continuous and Discrete Diffusion Models(269)은 모델 미세조정 없이 보상 기반 유도 기법을 개발하여, 428의 테스트타임 정렬 아이디어와 직접 비교된다.
다른 접근
Diffusion 모델 정렬을 텍스트 조건이 아닌 reward-guided fine-tuning으로 수행한 다른 접근법을 보여줍니다.
다른 접근
Inference-Time Alignment in Diffusion Models with Reward-Guided Search 논문은 Diffusion 모델 정렬에서 보상 기반 최적화의 또 다른 구현 사례입니다.
다른 접근
Inference time alignment와 reward guidance를 diffusion 모델에 적용하여 단백질과 항체 등 Protein Landscape의 생성 품질을 높인다는 점에서 DDS 방식과 비교할 수 있다.
다른 접근
428번 논문은 reward-guided diffusion framework의 분자동역학 시뮬레이션에 최신 alignment 전략을 논하므로, 3101에서 제시하는 효율적 PIMD와 접근 관점에서 대조할 수 있습니다.
후속 연구
추론 단계에서의 보상/정렬 개선 기법 등 SHAC-ASAM과 유사한 강화학습 reward optimization 방법론의 발전 방향을 제시합니다.
후속 연구
Reward-Guided Iterative Refinement in Diffusion Models at Test Time(682)는 확산 모델의 테스트 타임 보상 기반 정렬을 다양한 과학적 응용에 적용하며, 428에서 다룬 리뷰의 실제적 확장 사례이다.
후속 연구
LLM의 테스트 타임 최적화 전략(정보 병목 기반)이 diffusion 모델의 inference-time alignment에 응용될 수 있습니다.
후속 연구
보상 신호를 통한 디퓨전 모델의 추론 정렬 기법이 생성형 normalizing flow 가속과 유사한 문제를 다룹니다.
후속 연구
428번 논문은 diffusion 기반 분자 생성에서 reward-guidance와 alignment를 통합하는 최신 발전으로, CoCoGraph의 제약 확산과 맥락이 맞닿아 있습니다.
응용 사례
테스트 타임 최적화와 inference-time alignment 아이디어가 정보 병목 이론 및 LLM의 실제 입력 정책과 연결되어 diffusion 모델에도 적용될 수 있음을 시사합니다.