저자: Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han | 날짜: 2022 | DOI: N/A 📄 PDF
Essence
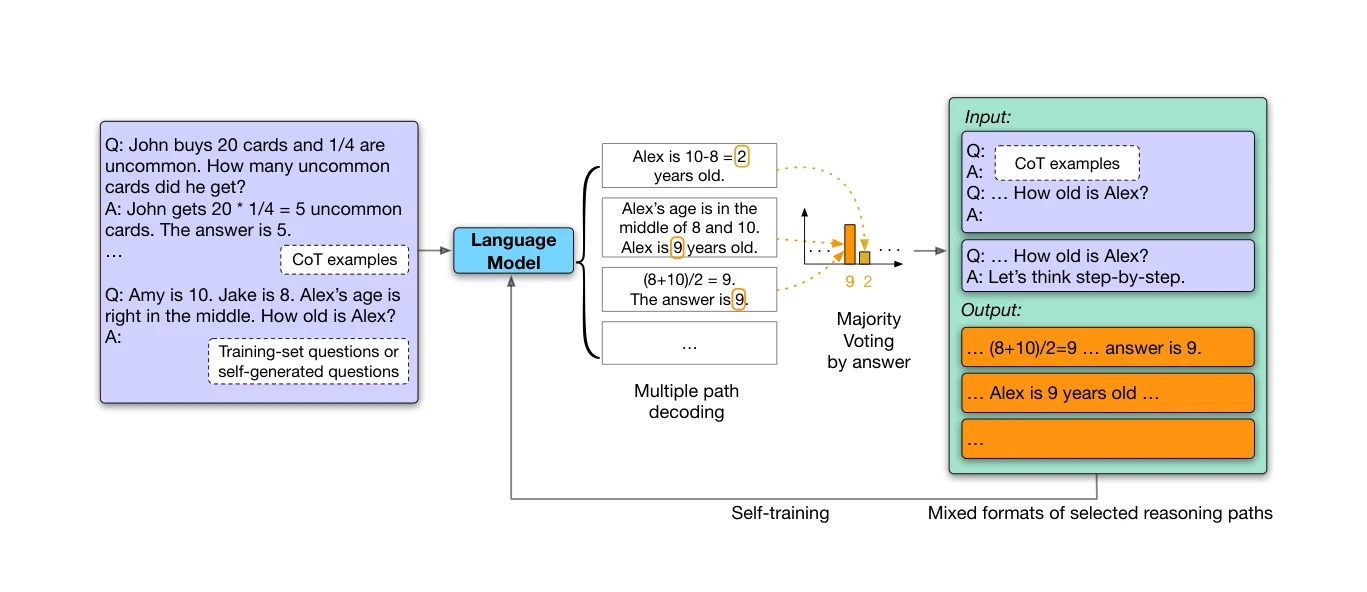
그림 1: 방법의 개요. Chain-of-Thought 예시를 활용하여 언어모델이 여러 개의 CoT 추론 경로를 생성하고, 다수결 투표(Majority Voting)로 고신뢰도 답변을 선택한 후, 이를 파인튜닝 데이터로 활용
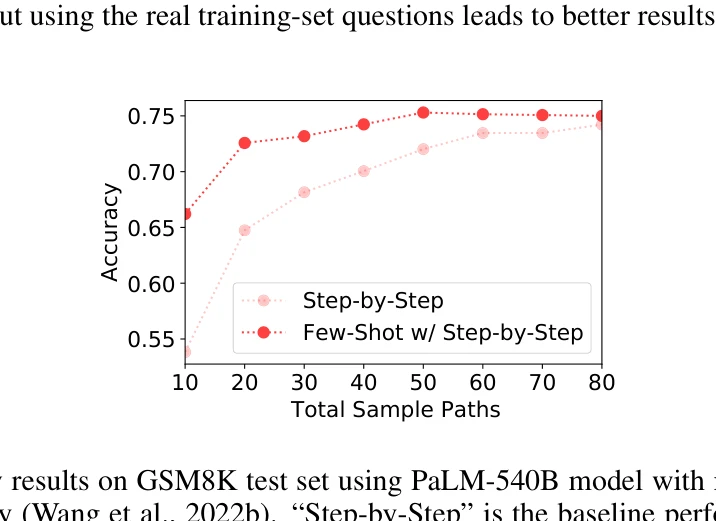
대규모 언어모델(LLM)이 레이블 없는 데이터만으로 자기 생성 고신뢰도 추론(reasoning) 경로를 통해 자가 개선(self-improve)할 수 있음을 입증한 논문이다. Chain-of-Thought 프롬팅과 자기 일관성(self-consistency)을 활용하여 감독 신호 없이 모델의 추론 능력을 향상시킨다.
Evaluation
총평: 이 논문은 레이블 없는 데이터로 대규모 언어모델이 자가 개선할 수 있음을 명확히 입증한 중요한 연구다. Chain-of-Thought와 자기 일관성을 창의적으로 조합하여 강력한 자동 감독 신호를 얻었으며, 도메인 내외 다수 데이터셋에서 상태 추적 수준의 성능을 달성했다. 다만 신뢰도 평가의 정교성, 오류 증폭 위험, 계산 비용 등의 한계가 있으나, 감독 신호 의존성을 크게 줄일 수 있다는 점에서 실무적 가치가 매우 높다.
같이 보면 좋은 논문
기반 연구
LLM이 암묵적으로 self-improvement를 학습하도록 하는 방법을 제시해, 자기 개선 논문의 기반이 된다.
기반 연구
470은 LLM의 자기 개선 가능성에 대한 이론적/실험적 논의로 746의 기초적 배경을 제공합니다.
기반 연구
470의 LLM 자기개선 능력 관련 연구는 180에서 평가하는 능동적 정보수집 및 전략 적응의 이론적 기반이 된다.
기반 연구
LLM의 자기개선과 self-improvement 구조에 대한 이론적 분석을 바탕으로, 447번 논문의 반복적 강화학습 구조를 뒷받침합니다.
기반 연구
LLM의 자기 개선과 반복적 오류 수정 메커니즘의 기본 원리를 바탕으로, 598번 논문의 강화학습적 self-correction 프로세스의 기초를 제공합니다.
기반 연구
LLM의 자기개선과 반사(reflection) 방법론의 한계를 분석해, DLPO에서 다루는 프롬프트 최적화 개선의 이론적 배경을 제공한다.
기반 연구
Large language models can self-improve 논문은 LLM의 인간수준 추론 및 적응력의 발전상을 조명하며, 튜링 테스트 통과와 같은 성취의 이론적 기반이 됩니다.
기반 연구
Large language models can self-improve 논문은 LLM 자기개선 개념의 이론적 근거와 실험적 사례를 제공해 538의 자기개선 능력 계량화 분석에 토대를 제공합니다.
기반 연구
353의 LLM을 활용한 자동화 및 자기개선 AI 에이전트 설문은 470 연구의 기술‧이론적 토대를 제공합니다.
다른 접근
Self-Refine 논문은 LLM의 iterative self-feedback을 통한 답변 개선 구조를 제시하며, 자기 개선과 자기 점검의 동향을 같이 이해할 수 있다.
다른 접근
Large language models can self-improve 논문은 LLM의 자기 개선 능력을 평가하는 논문으로, Selfcheck의 단계별 자기검증과 달리 장기적 자기학습 측면을 논의한다.
다른 접근
470 'Large language models can self-improve' 논문은 SFT/RL 외에도 자체 생성된 피드백과 자기개선 루프를 통한 LLM 일반화 향상 전략을 다루어 대조적으로 참고할 수 있습니다.
후속 연구
747은 zero-shot self-checking 및 자기 일관성 기반 reasoning 강화 전략을 통해 LLM의 self-improve를 실제로 검증한다.
후속 연구
470 논문은 LLM의 자기 개선능력(자기 수정, self-improvement)의 체계적 실증을 제공하여, 314에 제안된 PIT(self-improvement 프레임)의 효과를 실험적으로 확장한다.
후속 연구
447은 자기 인센티브를 통한 LLM 자기개선 방식으로, 470의 자기 일관성과 신뢰도 추론 기반 자기개선 실험의 후속 발전입니다.
후속 연구
538 논문은 LLM 자기 개선 능력의 한계와 자기 반영 기법들의 효과를 체계적으로 측정하여, 470의 주장을 벤치마크/비판한다.
후속 연구
470은 LLM의 자기개선 학습과 자기반성의 기법을 다루어, 845에서 제안한 RISE 프레임워크의 확장 논의를 보완한다.
반론/비판
Large language models can self-improve 논문은 LLM의 자기개선 가능성을 실험적으로 주장하며, self-correction 한계라는 본 논문과 논점이 대조됩니다.
반론/비판
LLM의 self-improvement(자기개선) 능력이 실제로 가능한지에 대해 실험적으로 논의, 추론 경계 프레임워크에 비판적 입장 제시.