Essence
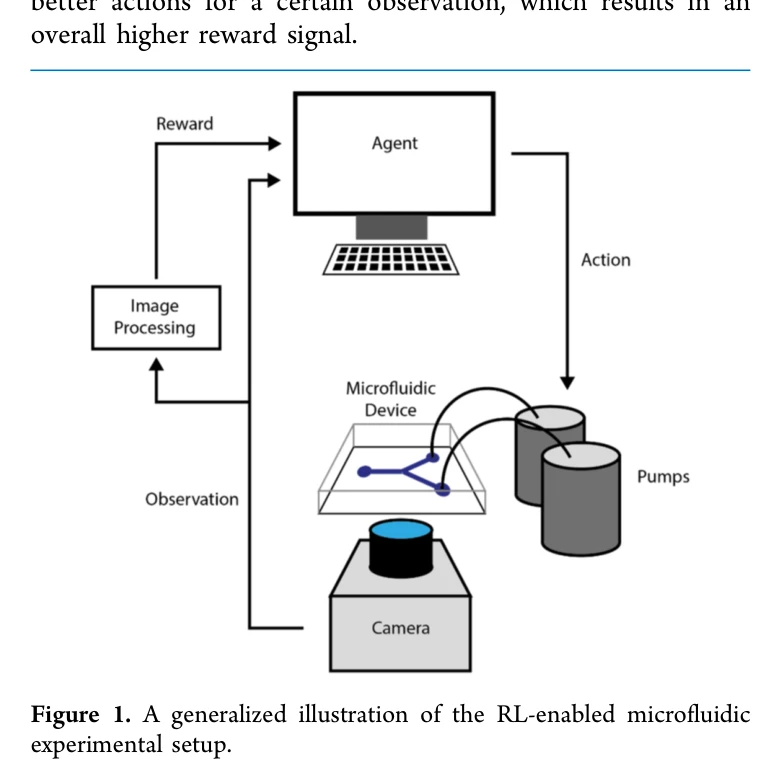
Figure 1. A generalized illustration of the RL-enabled microfluidic
마이크로플루이딕 시스템의 동적 제어를 위해 Deep Q-Networks와 model-free episodic controller 기반의 reinforcement learning 알고리즘을 적용하여, 실제 실험 환경에서 laminar flow interface 위치 제어와 droplet 크기 제어를 자동화했다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 마이크로플루이딕 분야에서 reinforcement learning을 처음 실제 실험에 적용한 선구적 연구로, DQN과 MFEC을 비교하며 실시간 비전 기반 자동 제어의 가능성을 명확히 입증했다. 마이크로플루이딕 실험의 자동화와 신뢰성 향상이라는 실질적 문제를 해결하는 중요한 기여이나, 범용성과 장시간 안정성에 대한 추가 검증이 필요하다.
같이 보면 좋은 논문
기반 연구
662번 논문은 강화학습 기반 실험 제어 자동화를 다루어, 571번과 같이 자동화 AI 평가 시스템의 기저가 되는 실험적 방법론을 제공한다.
기반 연구
380은 동적 마이크로플루이딕 시스템의 적응적 제어에서 생성 모델을 사용하는 근본적 배경을 제공한다.
기반 연구
662는 마이크로플루이딕 시스템에서 RL 기반 동시 제어를 실험적으로 탐구하여, 863의 다중 태스크 동시 실행 및 가치 함수 독립성 개념에 이론적 토대를 제공한다.
다른 접근
화학기상증착 실험에 RL 기반 에이전트 자동제어를 적용한 논문으로, 오프라인 RL의 실제 응용 사례다.
다른 접근
211은 강화학습 기반 시뮬레이터 프레임워크로 화학 실험 최적화 문제를 다루며, 662의 물리적 마이크로플루이딕 제어와 유사 기술을 사용한다.
다른 접근
466은 언어모델을 활용한 진화적 최적화 방법을 제안하며, 강화학습 기반 실험 자동화와 비교될 만한 대안적 접근을 제공한다.
다른 접근
오프라인 RL의 로봇 제어 견고성 평가로, 강화학습 기반 마이크로플루이딕 실험 제어의 한계 및 안전성 문제와 연결해볼 수 있습니다.
다른 접근
410번 'How deep do large language models internalize scientific lit' 논문은 LLM의 과학 지식 내재화 접근법으로, 실험적 제어·자동화(662)와는 근본적으로 다른 대안적 시각을 제시한다.
다른 접근
662는 마이크로플루이딕 제어용 강화학습을 실제 실험 환경에 적용하는 사례로, 891의 강화학습 기반 제어의 실용적 적용 예이다.
후속 연구
마이크로플루이딕 제어 실제 실험 현장에서 RL 알고리즘의 견고성을 직접 실험적으로 분석한 논문으로, 실질적 후속 연구다.
후속 연구
화학 및 재료과학 실험의 자동 실험실에서 강화학습 및 RL을 실질적으로 확장 적용한 사례다.
후속 연구
ReTool 논문은 LLM 및 RL 기반 도구 활용을 통한 전략적 제어 최적화로 662의 동적 제어 RL 실험을 연구 범위를 확장합니다.
후속 연구
Reinforcement Learning for Dynamic Microfluidic Control 논문은 인간 피드백과 상호작용 기반 LLM 에이전트 성능 향상 사례로, InterFeedback의 벤치마크 평가 관점에서 의미 있는 확장입니다.
후속 연구
684는 로봇과 자동화 실험실에서 화학 반응 공간을 효율적으로 매핑하는 접근법을 제안하여, 662의 RL 기반 마이크로플루이딕 제어를 실험 자동화로 확장한다.
응용 사례
662번의 실험적 강화학습 자동제어 프레임워크는 571번의 자동 쓰기평가 및 피드백 시스템 구조에 연구 방법론으로 참고될 수 있다.
응용 사례
마이크로 플루이딕스 반응 제어에서의 RL 적용이 ChemGymRL의 RL 에이전트와 직접적으로 관련 가능성을 보여준다.
응용 사례
Reinforcement Learning for Dynamic Microfluidic Control 논문은 실제 RL 기반 실험 제어에 안전성 메커니즘을 구현하여, CBFs를 통한 안전 제어의 실용적 적용사례를 제공합니다.
응용 사례
미세유체 제어 등 실제 제어계에 AI/시뮬레이션이 실시간으로 영향을 미치는 사례를 확장 이해에 유용함.