Essence
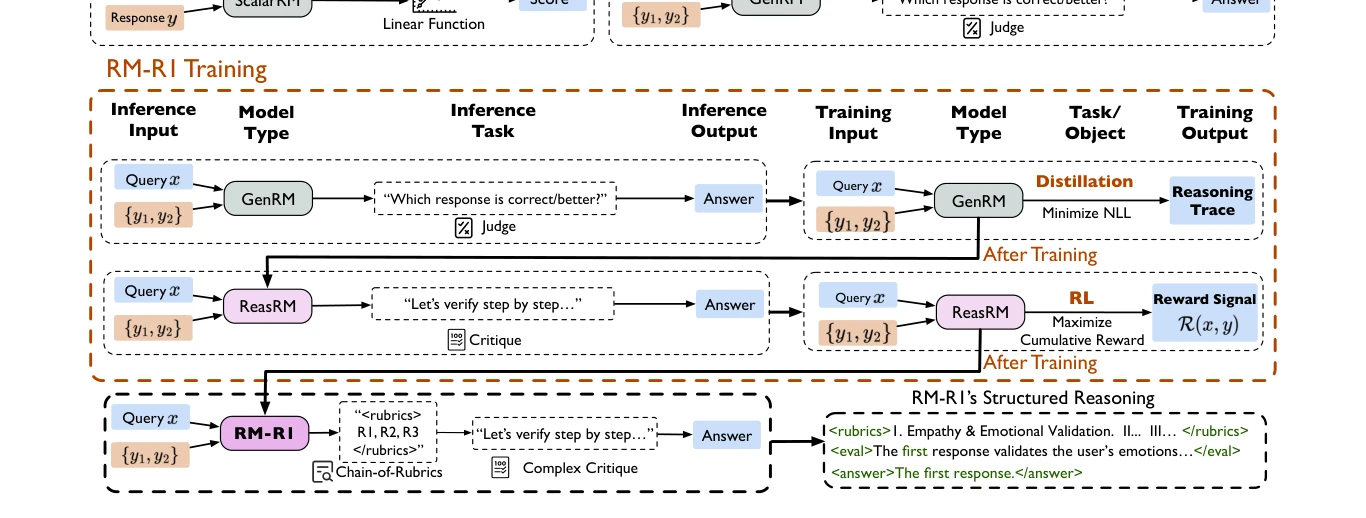
보상 모델(Reward Model, RM)에 추론 능력을 통합함으로써 해석 가능성과 성능을 모두 향상시킨 새로운 클래스의 생성형 보상 모델인 RM-R1을 제시한다. Chain-of-Rubrics(CoR) 메커니즘을 통해 작업 특성에 맞춘 맞춤형 추론 전략을 적용하여 70B, 340B 모델과 GPT-4o를 최대 4.9% 능가한다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4.5/5 Significance: 4.5/5 Clarity: 4/5 Overall: 4.4/5
총평: 보상 모델링을 추론 작업으로 재정의하는 핵심 아이디어와 Chain-of-Rubrics의 작업 인식 메커니즘이 혁신적이며, 실증적 성과(최대 4.9% 성능 향상)와 체계적 분석을 통해 실질적 기여를 입증한 우수한 연구이다. 다만 오라클 모델 의존성과 작업 분류의 이진 구조는 실무 확장성 측면에서 개선 여지가 있다.
같이 보면 좋은 논문
기반 연구
Self-Refine는 자기 피드백을 통한 LLM 단계별 추론 개선 기법을 제시하여, RM-R1의 보상모델 추론 메커니즘과 긴밀하게 연결됩니다.
기반 연구
683 논문은 보상 모델링을 통한 LLM의 추론 능력 향상 메커니즘을 설명하며, 466 논문에서 사용하는 엘리티즘 기반 강화전략의 이론적 기반이 됩니다.
기반 연구
447번 논문은 LLM의 자기 유도 강화학습 메커니즘을 다루며, 683번이 제시하는 보상모델 기반 추론 향상 전략의 이론적 기초를 제공합니다.
기반 연구
265번 논문은 RL 기반 강화추론 기법을 통해 LLM의 reasoning 성능을 향상시키며, 683번의 추론형 보상모델 접근의 이론적배경이 됩니다.
기반 연구
449의 RL 기반 LLM 최적화 논의는 683에서 제시하는 reward modeling as reasoning의 기초 위에서 출발한다.
기반 연구
RM-R1(683)은 보상모델을 통한 LLM의 논리적 추론 강화 방법론을 제시하여 243의 자연어+수치 보상 통합 접근의 이론적 기반이 된다.
기반 연구
보상 모델링과 추론 능력을 연계하는 접근법을 다루기 때문에, 강화학습 기반 자기검증(RISE) 시스템과의 이론적 연계가 유의미합니다.
다른 접근
Selfcheck 논문은 LLM의 자체 오류 인식, 추론 상태 점검에 집중하여, RM-R1 논문의 보상 모델 내 추론통합 접근에 비해 직접적 자기 점검 방식을 다룬다.
다른 접근
683번 논문은 Reasoning 기반의 Reward Modeling을 통해 LLM 자기교정의 조건과 가능성을 폭넓게 분석하여 471번의 비판적 결론과 균형 있게 읽기에 적합하다.
후속 연구
Tree-planner 논문은 효율적인 멀티스텝 작업 계획을 위한 LLM 기반 프레임워크로, RM-R1의 추론 중심 보상모델 설계 가이드라인에 실제 응용 사례를 제시한다.
후속 연구
674번 논문은 LLM의 전략적 도구 사용 및 강화학습 기반 추론을 다루어, 683번의 체인오브루브릭스(CoR)를 활용한 맞춤형 추론 전략과 연결됩니다.
후속 연구
RM-R1: Reward Modeling as Reasoning 논문은 RL 기반으로 LLM의 추론능력 강화와 검색 통합 성능 향상 방안을 추가로 탐구합니다.