How
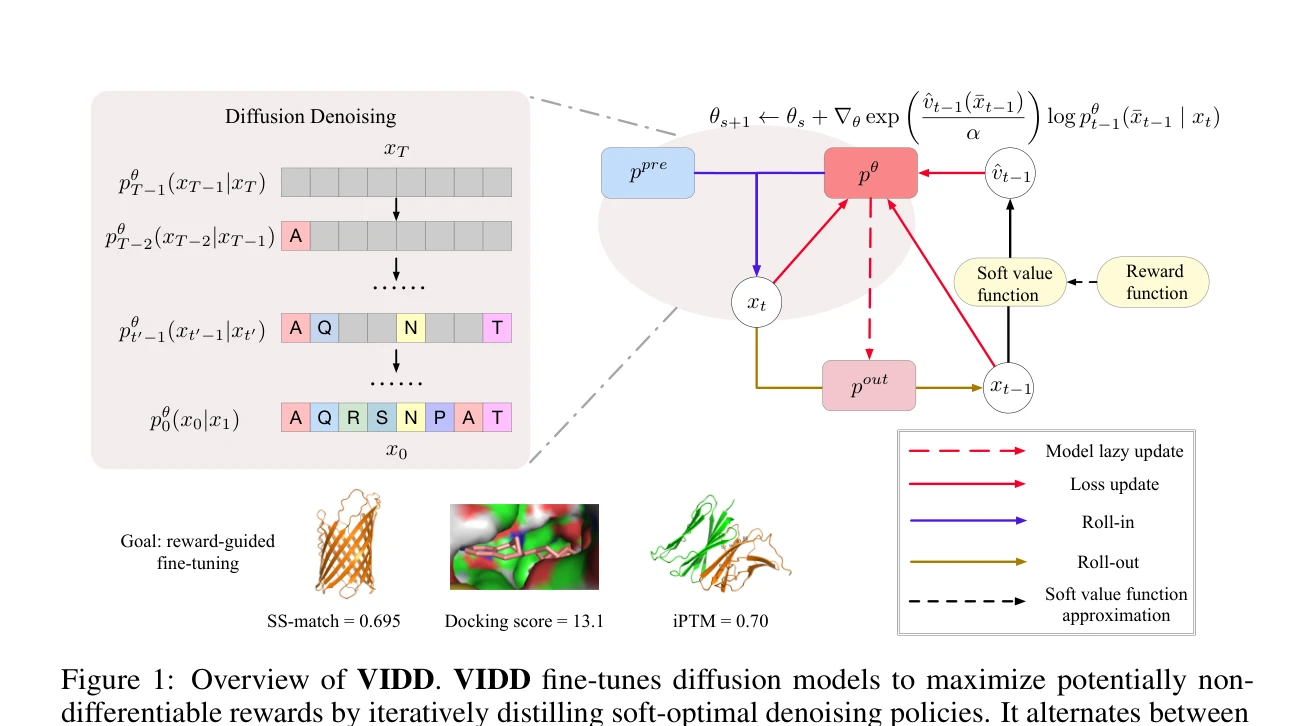
그림 1: VIDD의 알고리즘 구조 및 세 가지 핵심 단계
알고리즘 구조:
- Roll-in (오프정책 수집): 사전훈련된 모델과 이전 미세조정 정책의 혼합분포에서 궤적(trajectory)을 샘플링하여 다양한 탐색 보장. 이를 통해 현재 정책 주변의 좁은 영역으로 제한되지 않음
- Roll-out (소프트 최적정책 모의): 수집된 중간 상태 $x_t$에서 시작하여, 값함수 $\hat{v}_{t→1}$로 가중치를 부여한 보상 기반 소프트 최적정책 $p_{out}$을 구성. 이는 보상을 최적화하면서도 현재 정책과의 거리를 유지하는 KL 제약이 암묵적으로 포함됨
- Model Update (정방향 KL 최소화): 롤아웃으로부터 생성된 소프트 최적정책과 현재 모델 정책 사이의 KL 발산 최소화:
$$\mathcal{L} = KL(p_{out} || p_ω)$$
이는 전향적(forward) KL 목적함수로 모드 커버링(mode covering) 행동을 유도하여 다양성 보존
- 값함수 설계: 확산모델의 특성에 맞춘 값함수 $v_t(x_t) = \log p_{pre}(x_t) + \mathbb{E}[R(x_0)]$를 사용하여 보상과 분포 적합성 간의 균형 조절
같이 보면 좋은 논문
기반 연구
446에서 사용하는 LLM 및 생성형 AI의 과학적 응용은 004의 서베이가 이론적 배경을 폭넓게 제공한다.
기반 연구
446의 보상 기반 디퓨전 파인튜닝 방식은 682에서 소개된 테스트타임 반복적 보상 최적화 프레임워크의 이론적 출발점을 제공한다.
기반 연구
446의 보상 유도 파인튜닝 및 분포 확장 방법은 867의 검증기 기반 플로우 최적화 프레임워크의 근간이 된다.
기반 연구
보상 유도 확산모델 고도화(Iterative Distillation) 논문으로, Clean-Sample Markov chain 샘플링 전략과 근본적인 연결점을 설명한다.
기반 연구
Diffusion 모델의 reward-guided fine-tuning 방법론에 대한 체계적 분석 결과로, CAGenMol의 강화학습 기반 보상 세부 구현에 필요한 이론적 토대를 제공한다.
기반 연구
보상 유도형 diffusion 모델 fine-tuning의 일반적 전략을 제시하며, MP2D의 reward-guided sampling 설계의 이론적 기반이 된다.
다른 접근
555 논문은 분자 그래프 생성을 위한 GAN 기반 접근법을 제안하여, 확산모델 기반 설계와 대조적으로 참고할 수 있다.
다른 접근
두 논문 모두 미분불가능한 보상 함수로 확산 모델을 제어하는 방법을 다루지만, 446은 미세조정 기반, 269는 추론 시간 가이드 기법을 제안한다.
다른 접근
Iterative Distillation for Reward-Guided Fine-Tuning of Diff 논문이 보상-유도 미세조정을 통한 확산모델 일반화 탐색을 시도한 점에서 로봇 정책 최적화에 SAM을 적용한 본 논문의 대안적 성격을 지닙니다.
다른 접근
생물분자 설계에서 확산모델로 reward 기반 최적화를 시도한 논문은 LLM 기반 화학합성 자동화와 목표는 같지만 방법이 다릅니다.
다른 접근
Reward-Guided Iterative Refinement in Diffusion Models 논문은 보상 기반 확산모델 최적화의 또다른 딥러닝 프레임워크를 제시합니다.
다른 접근
Inference-Time Alignment in Diffusion Models 논문은 reward 신호를 활용한 확산모델 최적화의 또다른 실험적 접근을 보여줍니다.
다른 접근
두 논문 모두 diffusion 모델의 reward 기반 보정 문제를 다루지만, 서로 다른 최적화 방식과 실험 프로토콜을 제안하여 비교 분석이 유용하다.
다른 접근
Reward-Guided Discrete Diffusion은 보상함수를 활용한 diffusion fine-tuning이라는 유사 문제를 다른 수식으로 해결하는 최신 연구입니다.
다른 접근
RNA 2차 구조 설계를 위한 다른 최적화 기반 방법을 제시하는 연구이다.
후속 연구
Iterative Distillation for Reward-Guided Fine-Tuning of Diffusion Models 논문은 보상 기반 튜닝과 견고성 강화 접근을 통한 RL 모델 개선 방법을 추가로 다룹니다.
후속 연구
CAGenMol 논문은 조건 인지 및 목적추구 확산언어모델로 생물분자/재료 설계에 reward-guided fine-tuning 프레임워크를 확장합니다.
후속 연구
Reward-guided fine-tuning 접근을 사용하여 생성 모델(특히 diffusion 기반)의 구조 다양화 및 제약 적용 가능성을 추가적으로 제시합니다.
응용 사례
SAMPLE 플랫폼은 자동 단백질 공학에서 시료 공간 탐색 효율화에 reward-guided 확산모델이 실제 응용되는 사례입니다.
응용 사례
446의 확산모델 보상 최적화는 AlphaFold3와 같은 최신 확산기반 생체구조 예측 모델의 현실 적용 효율성을 높이는 실질적 방법을 제시한다.
반론/비판
Hallucinations can improve large language models in drug discovery 논문은 '불안정성'이 항상 부정적이지 않다는 시각을 제시하여, reward-guided fine-tuning의 한계와 해석을 균형감있게 보여줍니다.