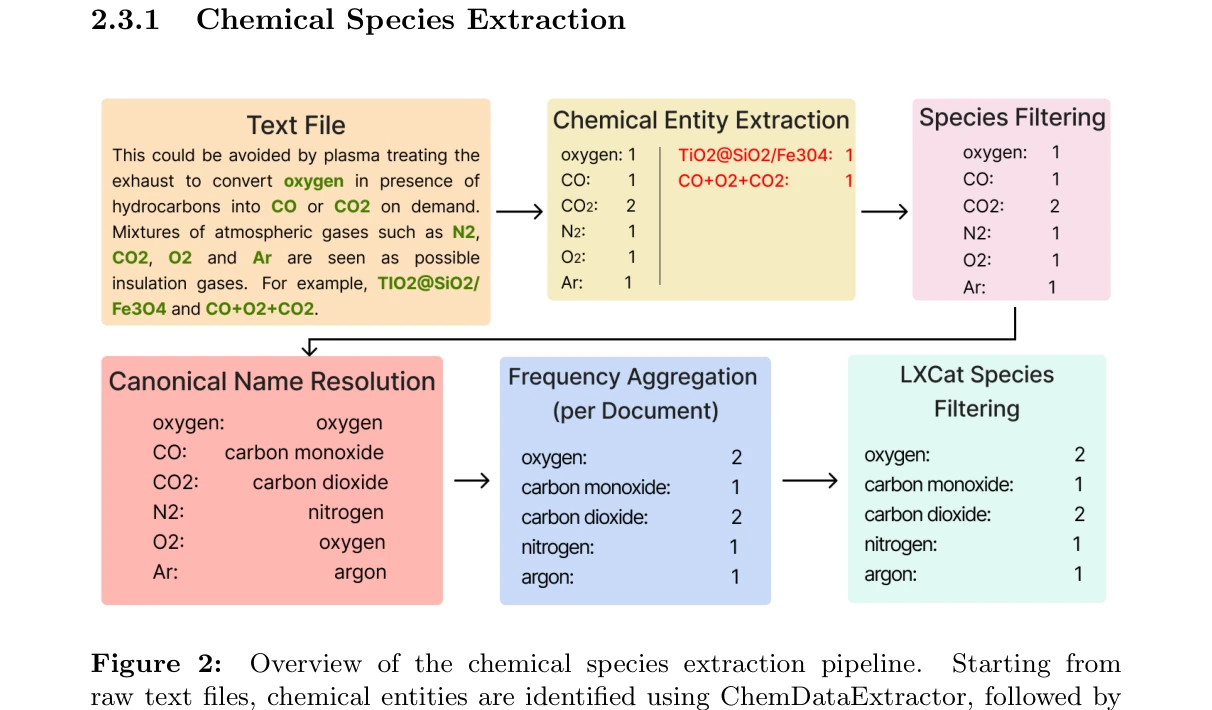
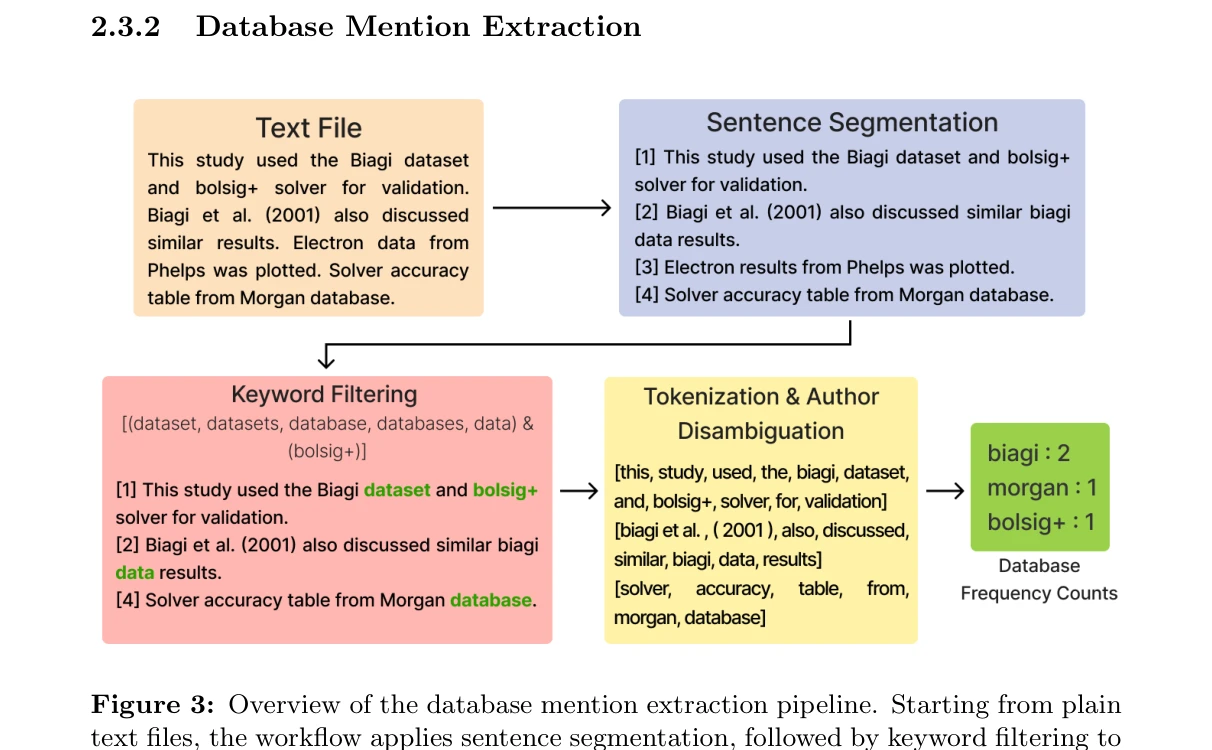
Essence
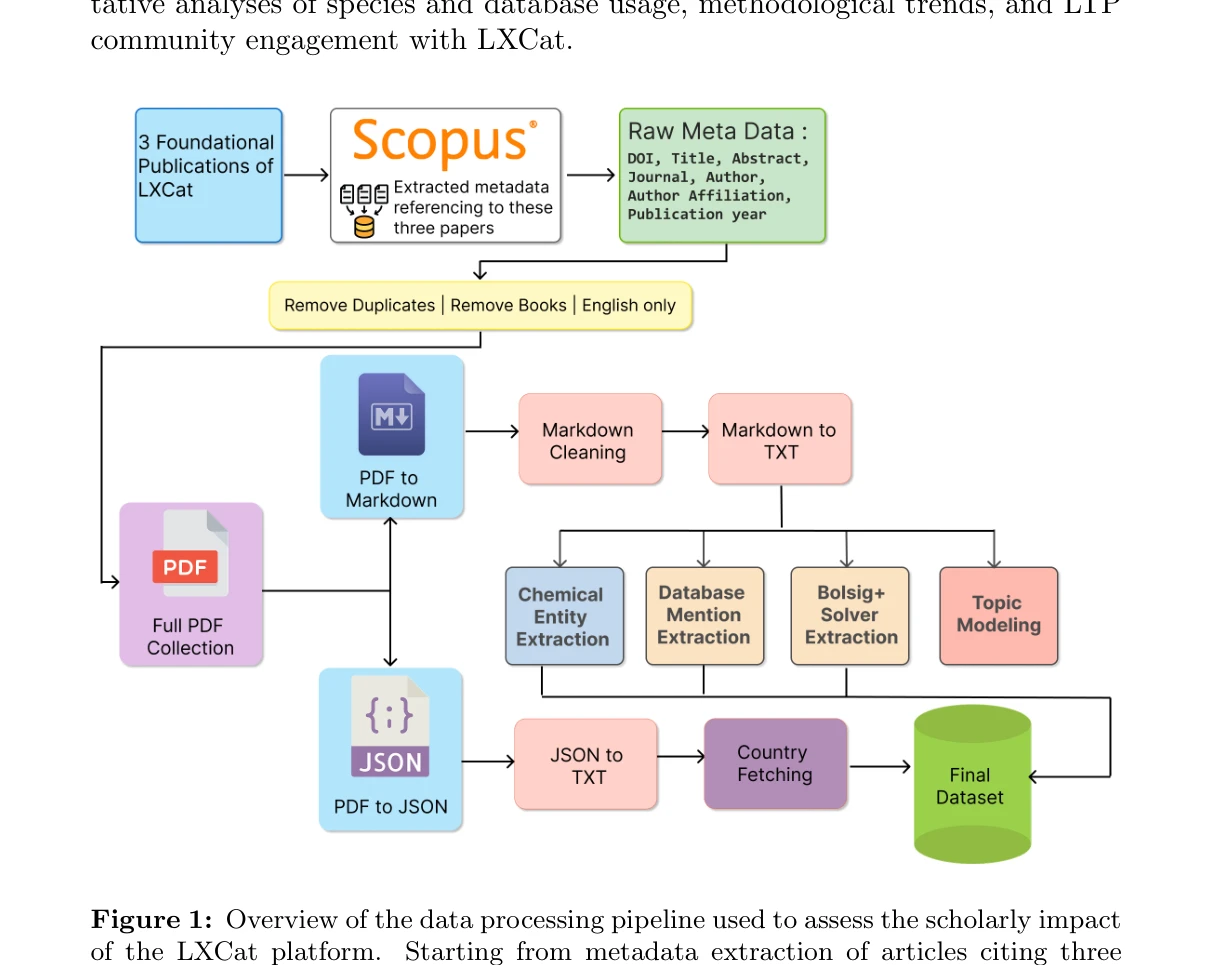
Figure 1: Overview of the data processing pipeline used to assess the scholarly impact
LXCat 오픈액세스 플랫폼의 저온 플라즈마 연구 커뮤니티에 대한 영향을 NLP 기반 전문 텍스트 scientometrics로 체계적으로 정량화한 연구이다. 인용 수를 넘어 데이터 사용 패턴, 화학 물질, 데이터베이스 활용도, 주제 진화 등을 추출하는 도메인 중립적이고 이전 가능한 평가 프레임워크를 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 연구는 인용 기반 scientometrics의 한계를 NLP 기반 full-text 분석으로 극복한 선도적 사례로, ORI 인프라의 실질적 영향을 체계적으로 정량화하는 도메인 중립적 프레임워크를 제시한다. 오픈소스 공개와 높은 이전 가능성으로 향후 오픈 사이언스 정책 수립 및 인프라 평가에 실질적 기여할 것으로 기대된다.