저자: Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang | 날짜: 2023-03-09 | URL: https://arxiv.org/abs/2303.05499 📄 PDF
Essence
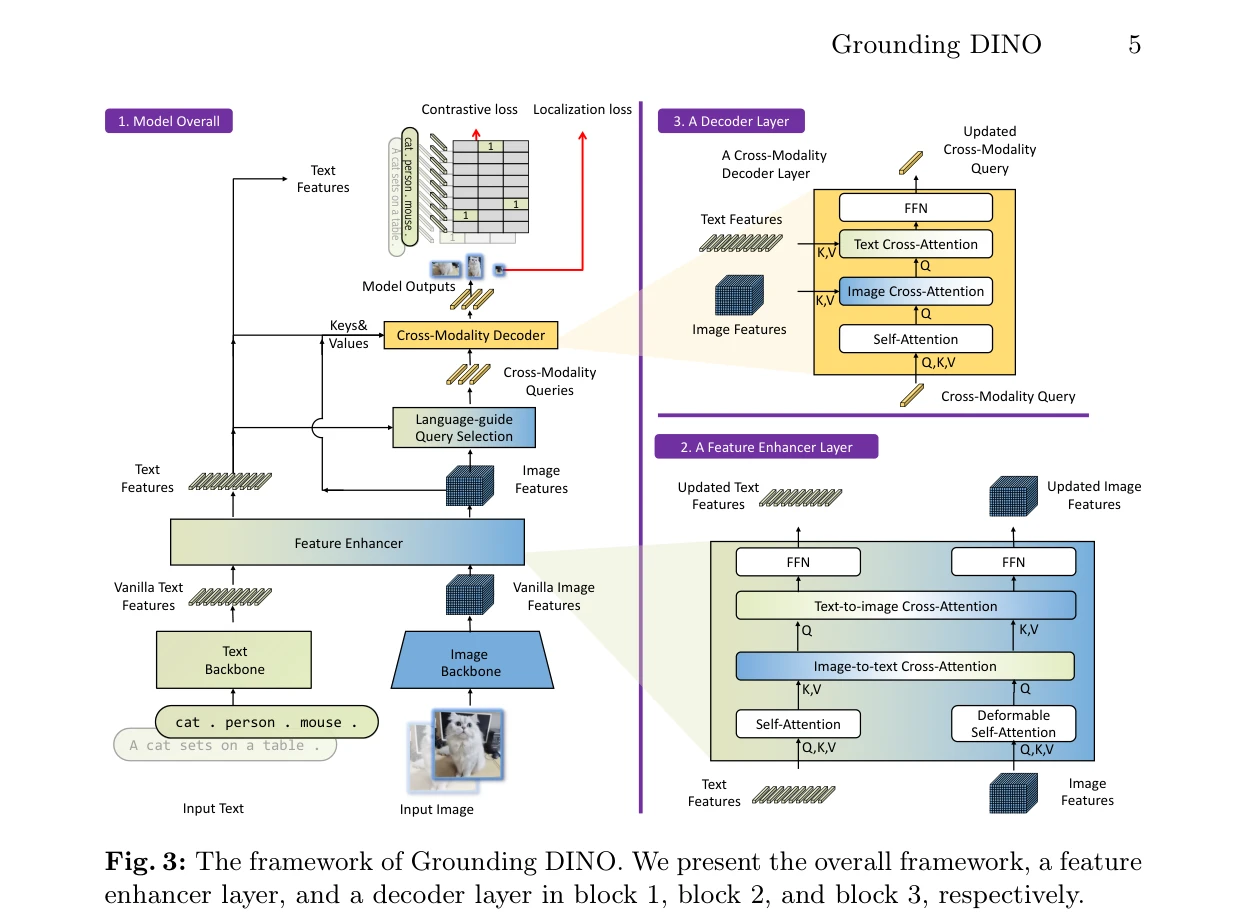
Fig. 3: The framework of Grounding DINO. We present the overall framework, a feature
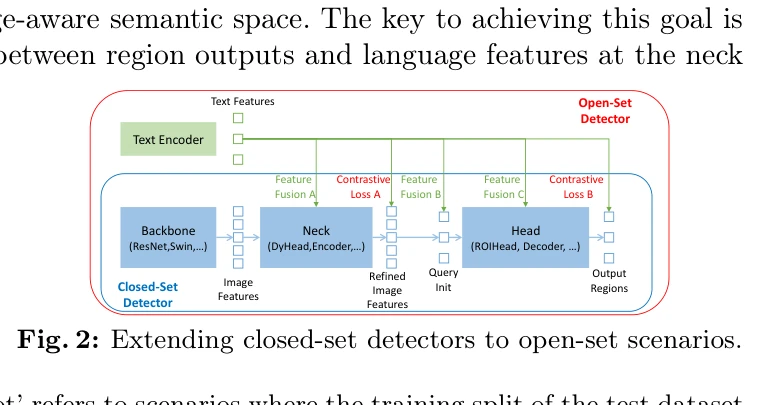
Grounding DINO는 Transformer 기반 detector DINO와 grounded pre-training을 결합하여 언어 입력(카테고리명 또는 referring expressions)으로 임의의 객체를 탐지하는 open-set object detector를 제시한다. 핵심은 언어와 비전 모달리티를 세 단계(feature enhancer, language-guided query selection, cross-modality decoder)에서 긴밀히 융합하는 것이다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: Grounding DINO는 Transformer 기반 detector의 structural advantage를 활용하여 세 단계 모두에서 tight language-vision fusion을 구현함으로써, open-set object detection의 새로운 SOTA를 수립했다. 포괄적인 벤치마크 평가와 실용적 응용 사례를 통해 높은 연구 가치를 입증한다.