Essence

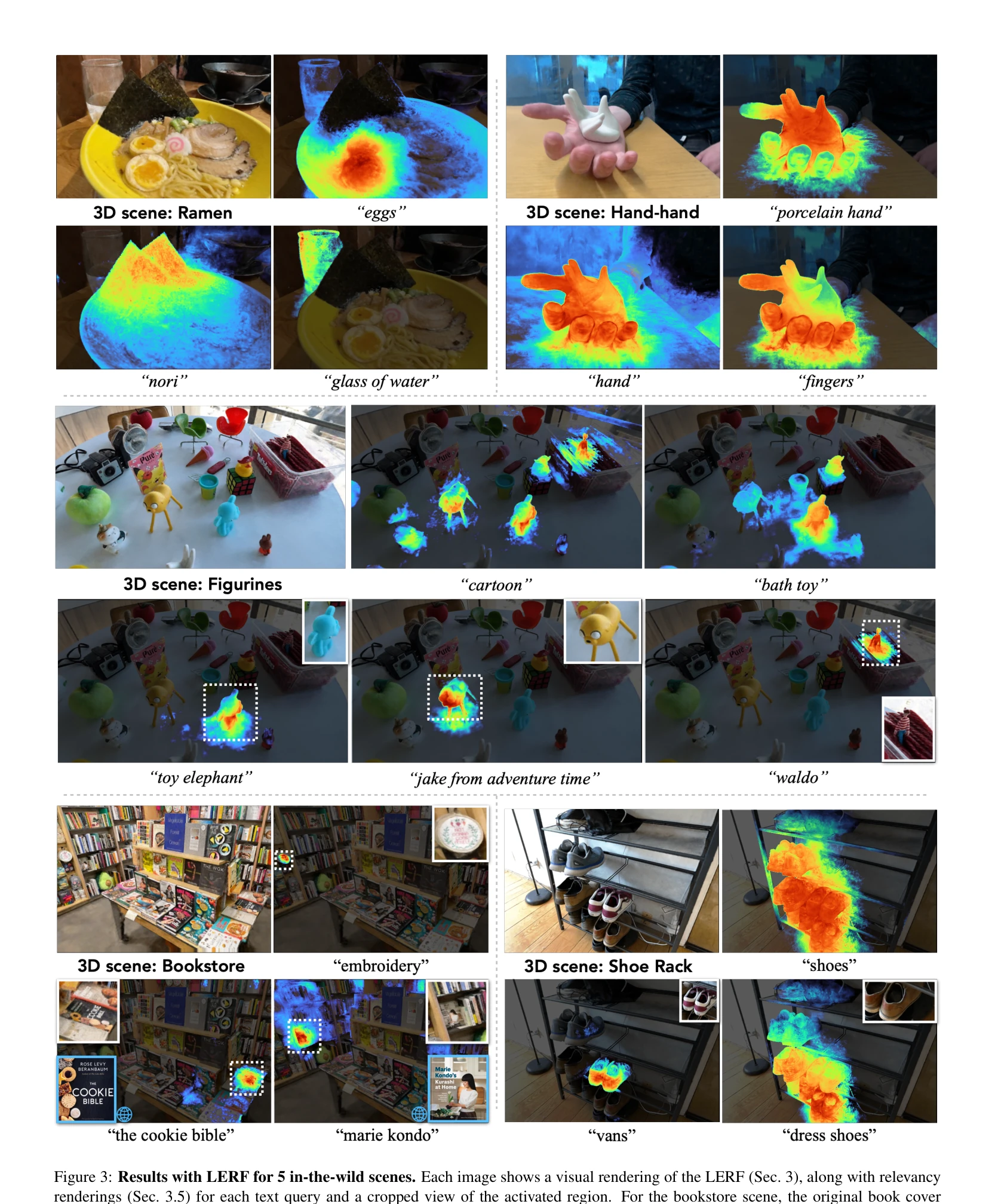
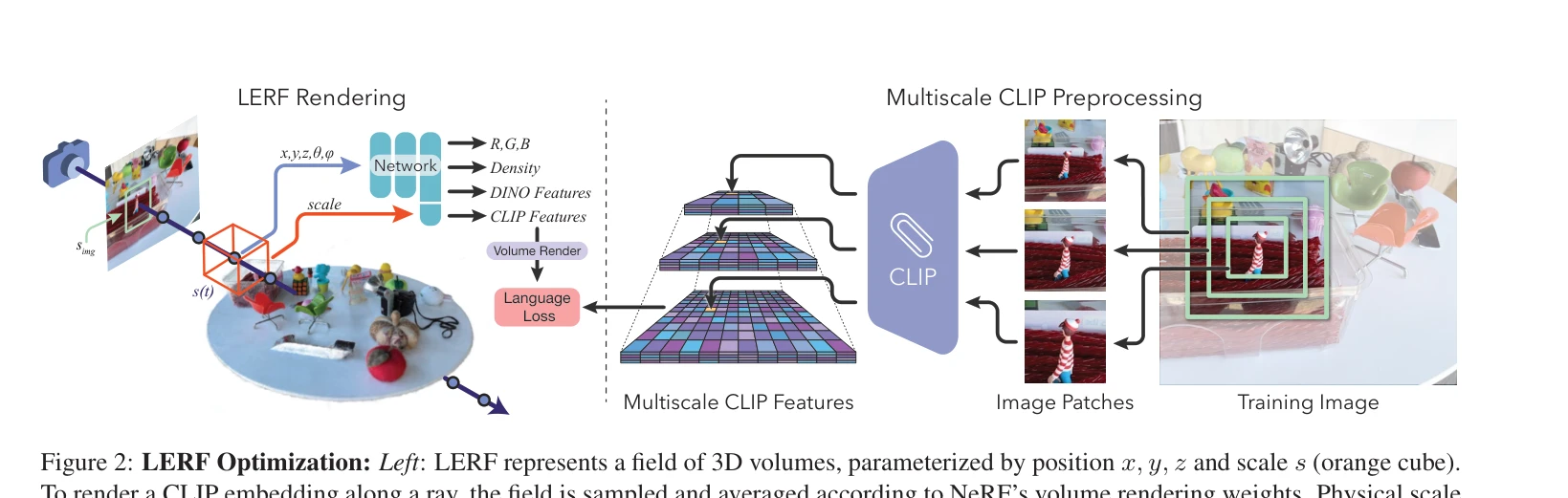
Figure 1: Language Embedded Radiance Fields (LERF). LERF grounds CLIP representations in a dense, multi-scale 3D field. A
LERF는 CLIP 임베딩을 NeRF에 정합하여 자연어로 3D 장면을 쿼리할 수 있도록 하는 방법이다. 다중 스케일 언어 필드를 학습함으로써 시각적 속성, 의미론, 추상적 개념, 장기 꼬리 객체 등 다양한 형태의 자연어 질의에 실시간으로 응답한다.