How
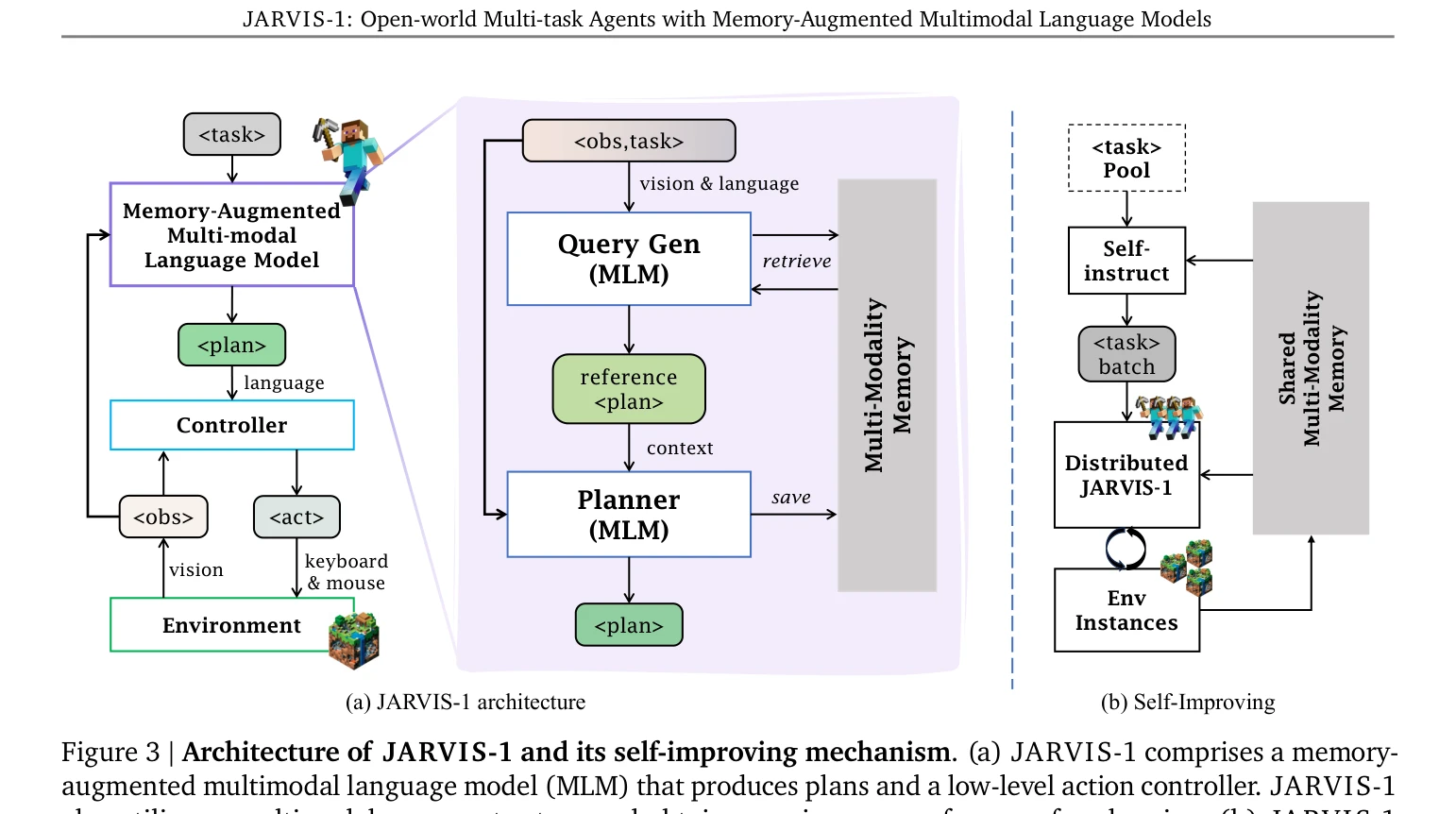
Figure 3 | Architecture of JARVIS-1 and its self-improving mechanism. (a) JARVIS-1 comprises a memory-
- MineCLIP(multimodal foundation model)과 GPT(LLM)를 체인으로 연결하여 multimodal language model (MLM) 구성
- 시각 관찰과 현재 상황을 기반으로 한 situation-aware planning으로 동적 환경에 적응
- 과거 성공 경험과 계획을 저장하는 multimodal memory로 in-context learning 수행
- Interactive planning으로 계획 실행 중 환경 피드백을 받아 실시간 계획 수정
- Self-instruct 메커니즘으로 에이전트가 자율적으로 새로운 작업을 생성하고 탐색 수행
- Goal-conditioned controller로 MLM이 생성한 고수준 계획을 저수준 모터 제어로 변환