저자: Zhen Fang, Zhuoyang Liu, Jiaming Liu, Hao Chen, Yu Zeng, Shiting Huang, Zehui Chen, Lin Chen, Shanghang Zhang, Feng Zhao | 날짜: 2025-11-27 | URL: https://arxiv.org/abs/2511.22134 📄 PDF
Essence
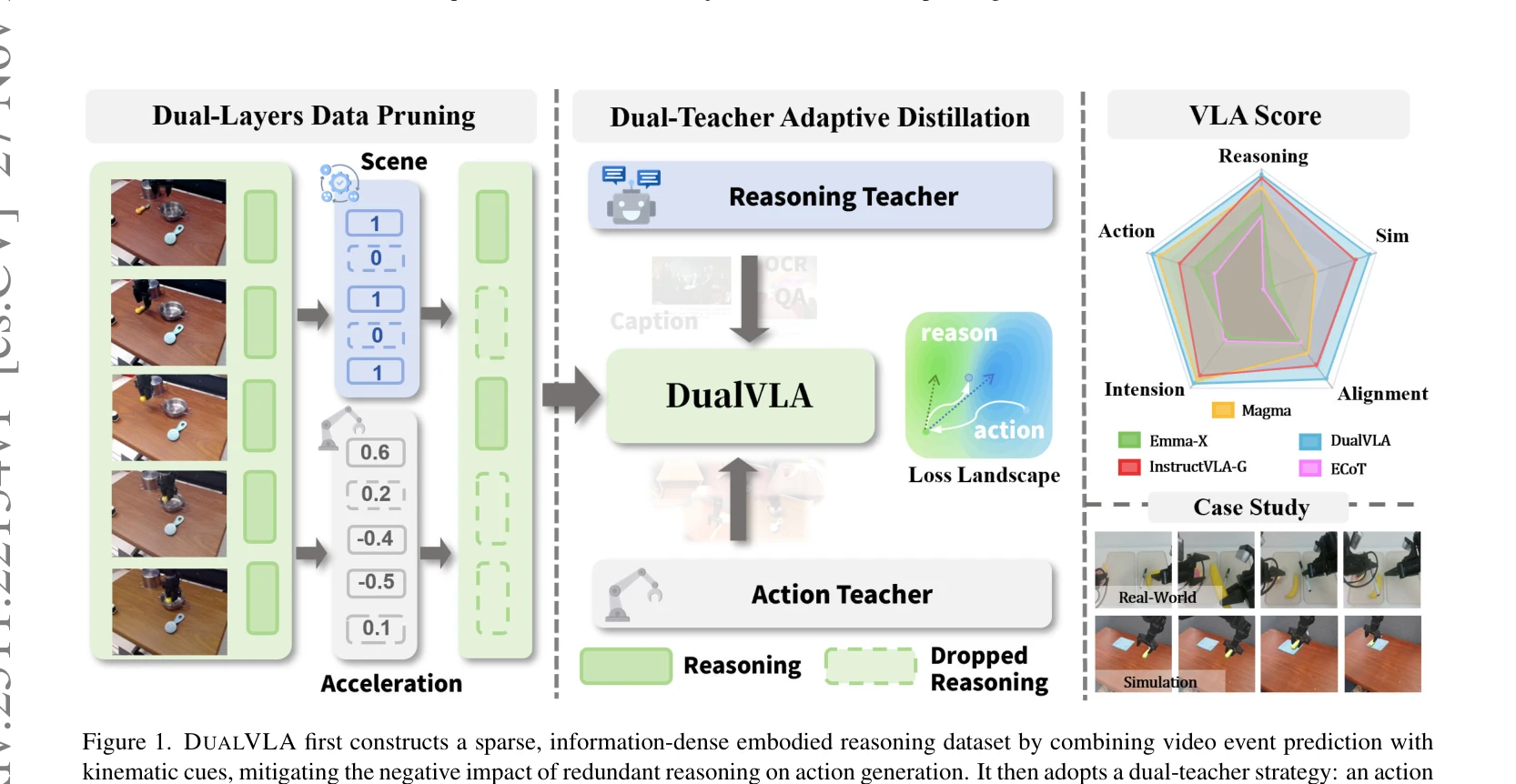
Figure 1. DUALVLA first constructs a sparse, information-dense embodied reasoning dataset by combining video event predi
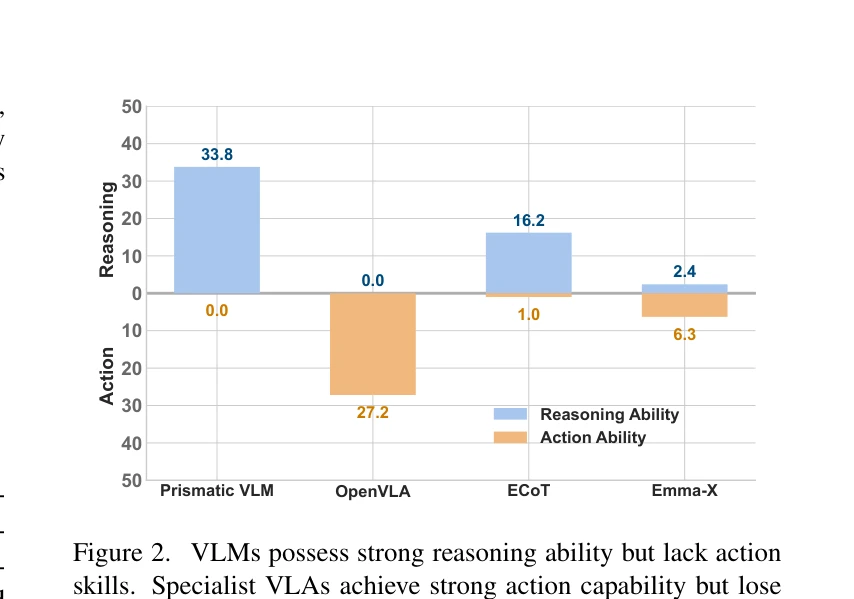
DualVLA는 Vision-Language-Action 모델에서 추론 능력을 추가할 때 발생하는 행동 성능 저하(action degeneration)를 해결하기 위해, 이중층 데이터 프루닝과 이중 교사 적응형 증류 전략을 통해 추론과 행동을 부분적으로 분리하는 접근법을 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 Vision-Language-Action 모델의 실질적인 문제인 action degeneration을 명확히 정의하고, 이를 해결하기 위한 이중층 프루닝과 이중 교사 증류 전략을 제시함으로써 추론 능력과 조작 능력의 균형을 효과적으로 달성하였다. 특히 VLA 평가를 위한 다차원적 프레임워크 제시는 향후 embodied AI 연구의 평가 표준으로서 중요한 기여를 한다.