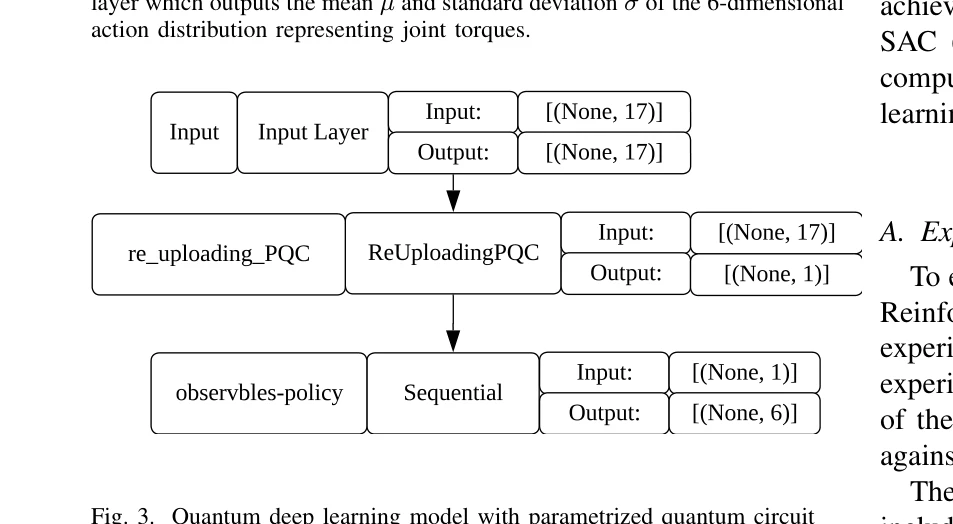
Essence
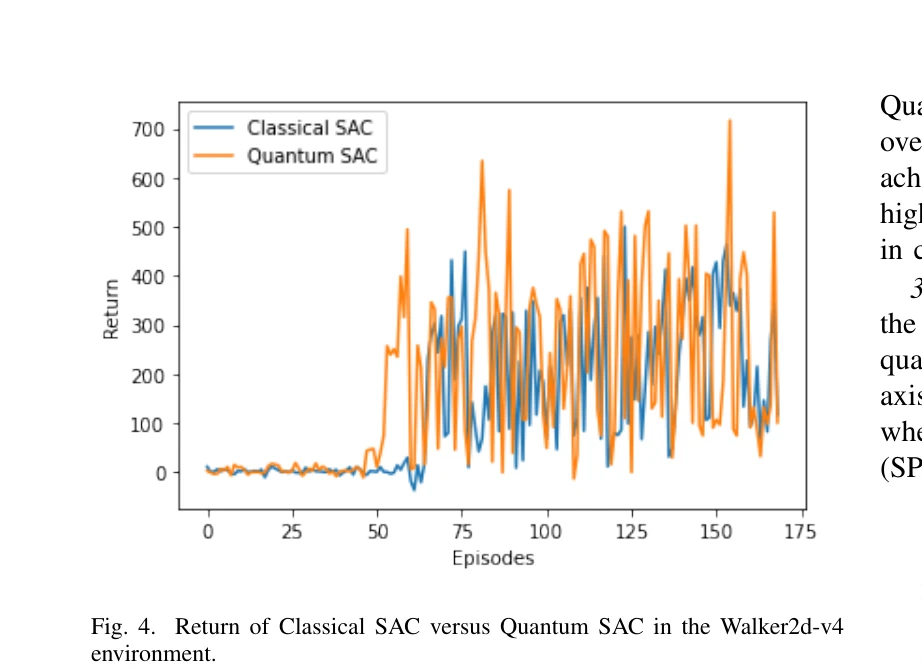
Fig. 4. Return of Classical SAC versus Quantum SAC in the Walker2d-v4
이 논문은 Soft Actor-Critic(SAC) 알고리즘을 parameterized quantum circuit으로 구현한 quantum deep reinforcement learning(QDRL)을 humanoid robot navigation 작업에 적용하여, 고차원 상태-행동 공간에서 고전적 RL보다 92% 더 적은 스텝으로 8% 높은 성능을 달성했다.