Essence
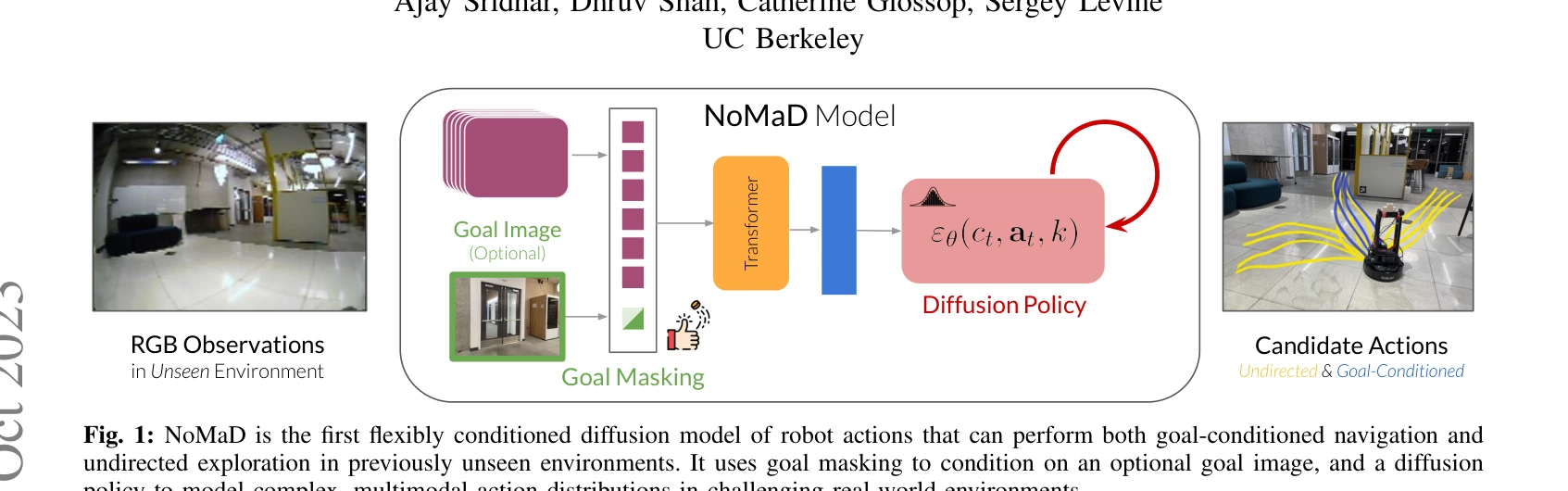
Fig. 1: NoMaD is the first flexibly conditioned diffusion model of robot actions that can perform both goal-conditioned
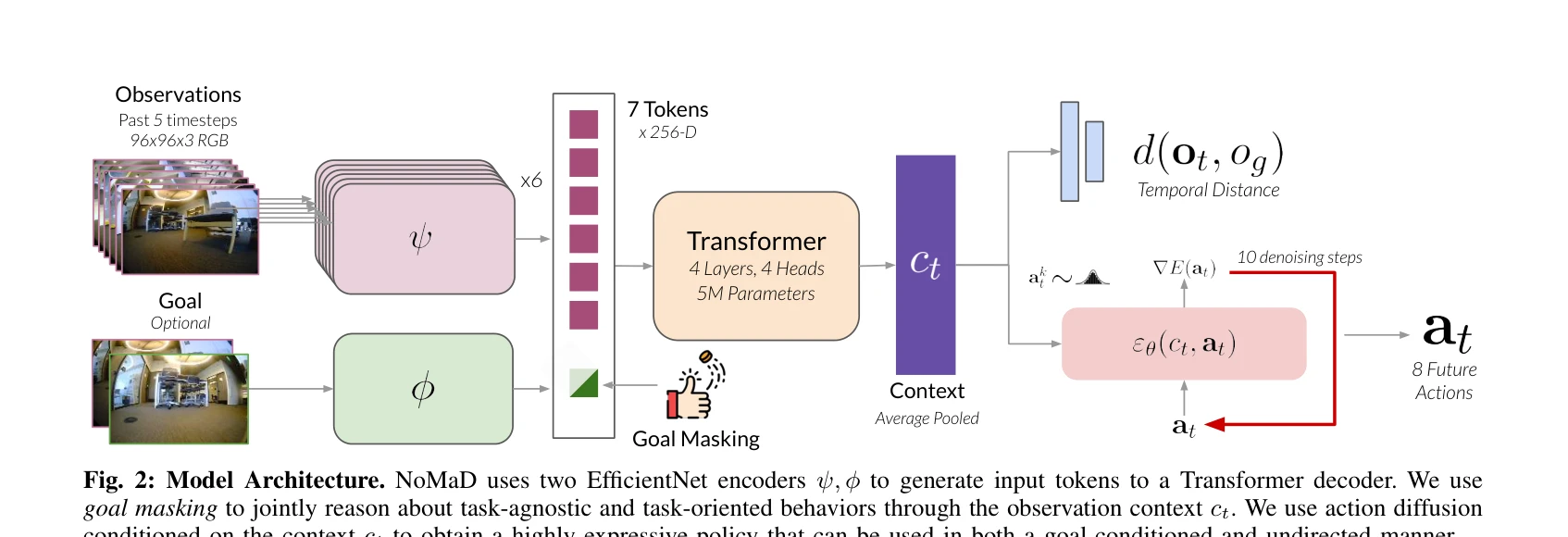
NoMaD는 goal masking을 활용한 unified diffusion policy로 로봇의 목표 지향 네비게이션과 목표 무관 탐색을 단일 모델로 처리하며, Transformer 기반 정책과 diffusion model decoder를 결합하여 미지의 환경에서 효과적인 네비게이션을 구현한다.