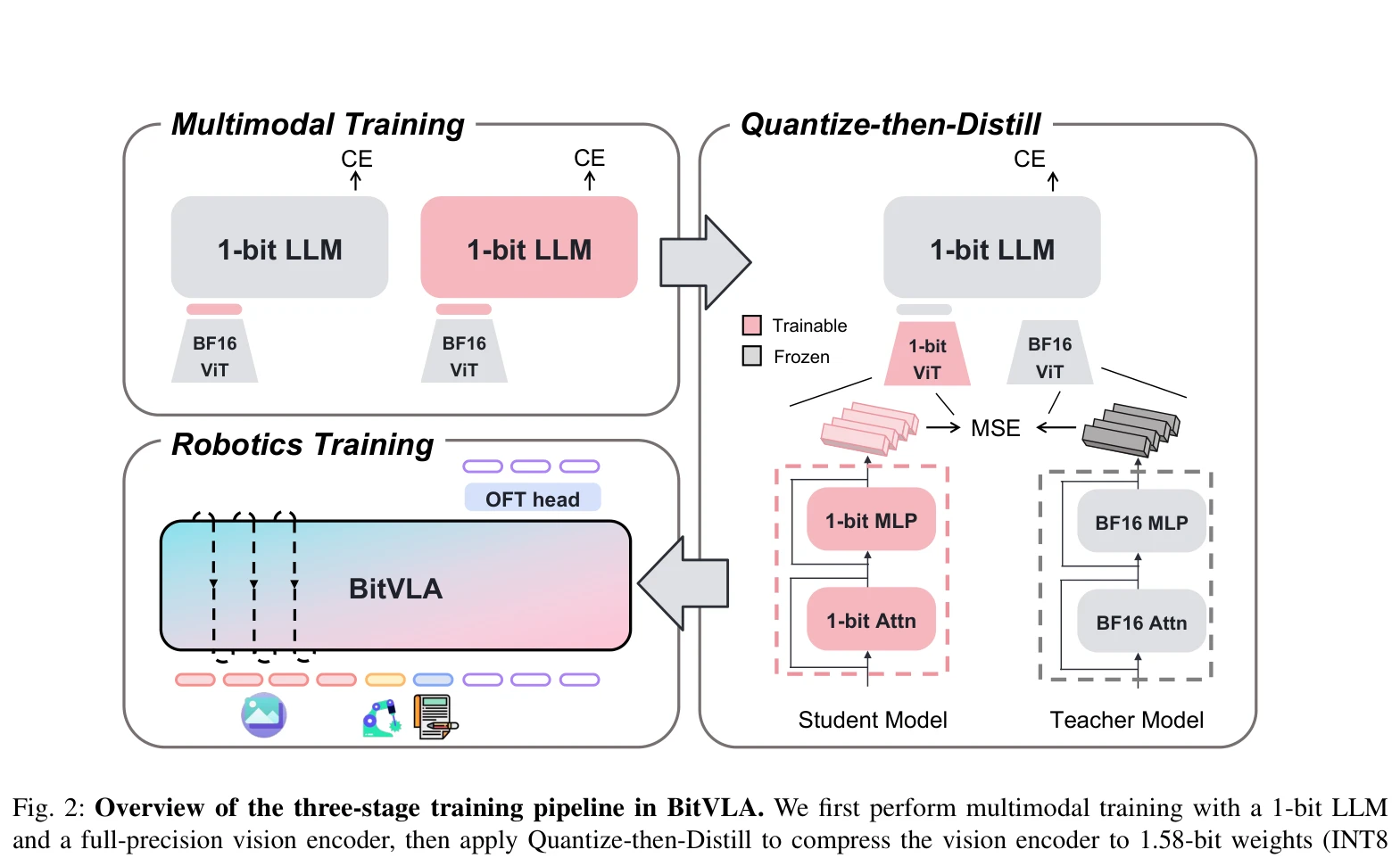
Essence
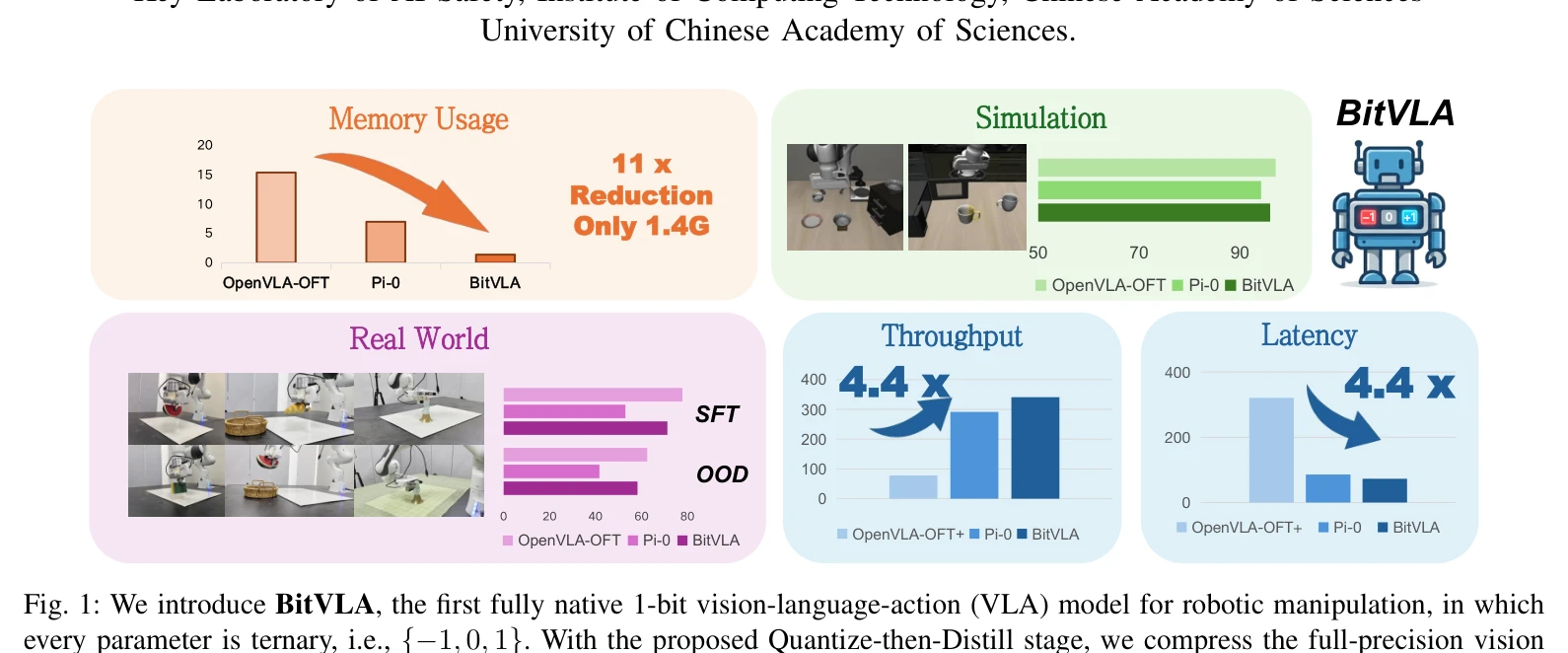
Fig. 1: We introduce BitVLA, the first fully native 1-bit vision-language-action (VLA) model for robotic manipulation, i
로봇 조작을 위한 완전한 1-bit Vision-Language-Action 모델인 BitVLA를 제안하여 11.0배의 메모리 감소와 4.4배의 지연 시간 단축을 달성하면서도 full-precision 기준 모델과 비슷한 성능을 유지한다.