Essence
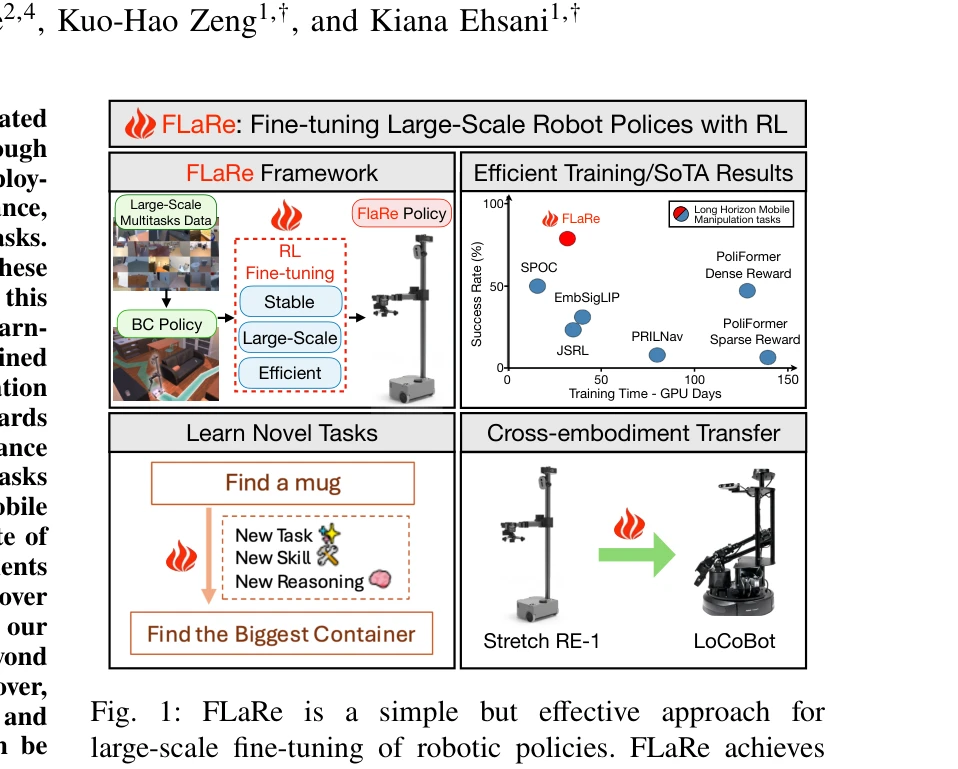
Fig. 1: FLaRe is a simple but effective approach for
FLaRe는 대규모 다중 작업 Behavior Cloning으로 사전학습된 로봇 정책을 Reinforcement Learning으로 효과적으로 미세조정하는 프레임워크로, 그래디언트 안정화 기법을 통해 성능 정체를 극복한다.
저자: Jiaheng Hu, Rose Hendrix, Ali Farhadi, Aniruddha Kembhavi, Roberto Martin-Martin, Peter Stone, Kuo-Hao Zeng, Kiana Ehsani | 날짜: 2024-09-25 | URL: https://arxiv.org/abs/2409.16578 📄 PDF
Fig. 1: FLaRe is a simple but effective approach for
FLaRe는 대규모 다중 작업 Behavior Cloning으로 사전학습된 로봇 정책을 Reinforcement Learning으로 효과적으로 미세조정하는 프레임워크로, 그래디언트 안정화 기법을 통해 성능 정체를 극복한다.
Fig. 1: FLaRe is a simple but effective approach for
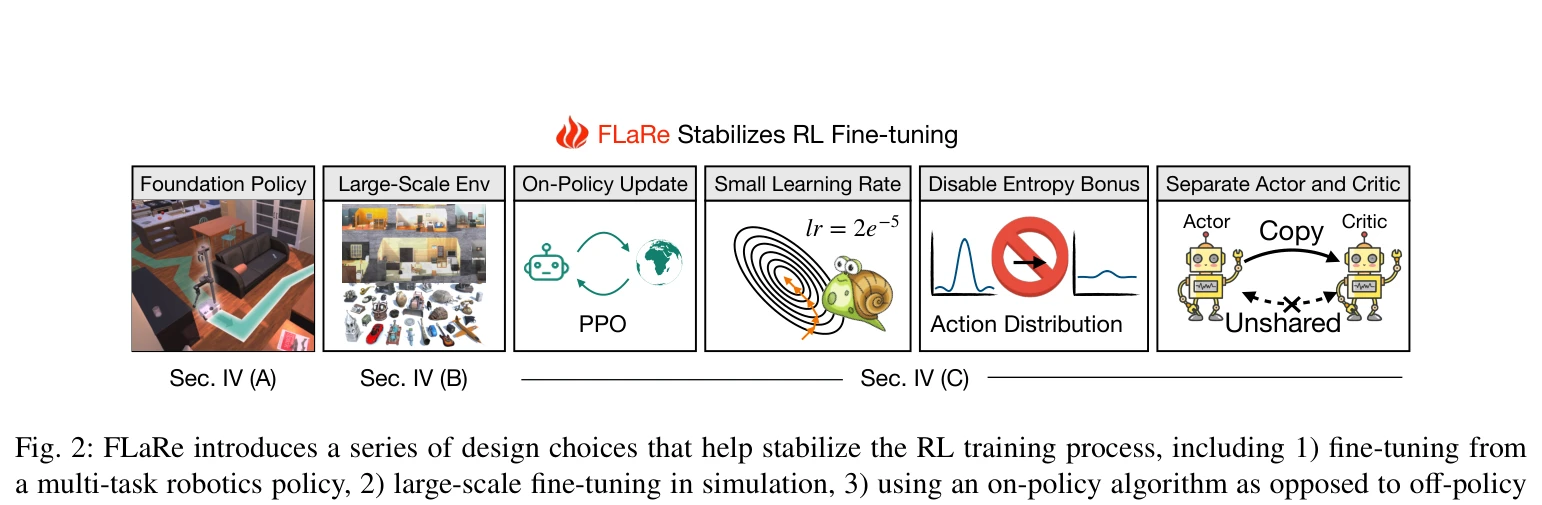
Fig. 2: FLaRe introduces a series of design choices that help stabilize the RL training process, including 1) fine-tunin
총평: FLaRe는 대규모 로봇 정책 미세조정의 실질적 문제들을 명확히 진단하고 체계적인 설계 선택으로 해결하여, 시뮬레이션과 실제 로봇 모두에서 획기적인 성능 향상을 달성했다. 특히 그래디언트 안정화 기법과 대규모 RL 훈련의 성공적 적용은 로봇 기초 모델 분야의 중요한 진전을 나타낸다.