Essence
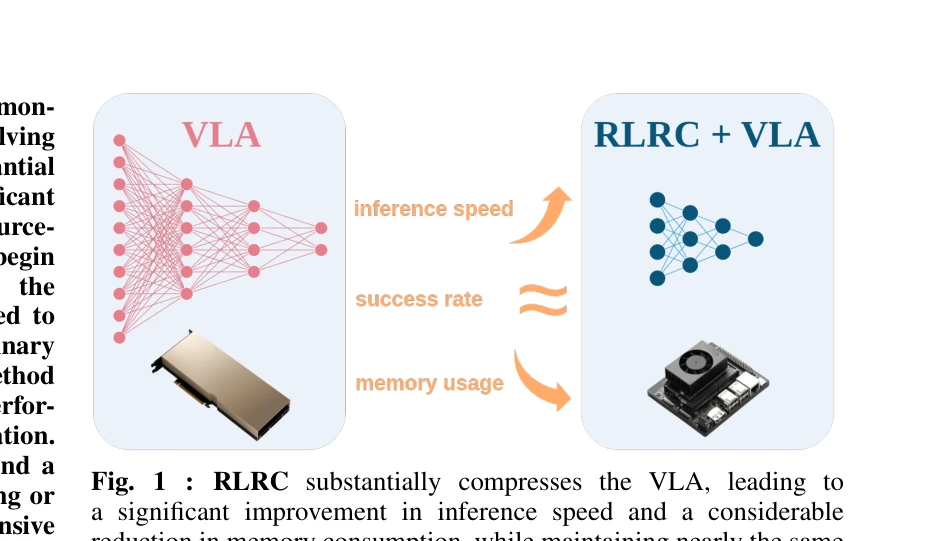
Fig. 1 : RLRC substantially compresses the VLA, leading to
Vision-Language-Action 모델의 실제 배포를 위해 structured pruning, SFT/RL 기반 성능 복구, 그리고 양자화를 결합한 RLRC 압축 방법을 제안하여 8배의 메모리 감소와 2.3배의 처리량 향상을 달성한다.
저자: Yuxuan Chen, Xiao Li | 날짜: 2025-06-21 | URL: https://arxiv.org/abs/2506.17639 📄 PDF
Fig. 1 : RLRC substantially compresses the VLA, leading to
Vision-Language-Action 모델의 실제 배포를 위해 structured pruning, SFT/RL 기반 성능 복구, 그리고 양자화를 결합한 RLRC 압축 방법을 제안하여 8배의 메모리 감소와 2.3배의 처리량 향상을 달성한다.
Fig. 1 : RLRC substantially compresses the VLA, leading to
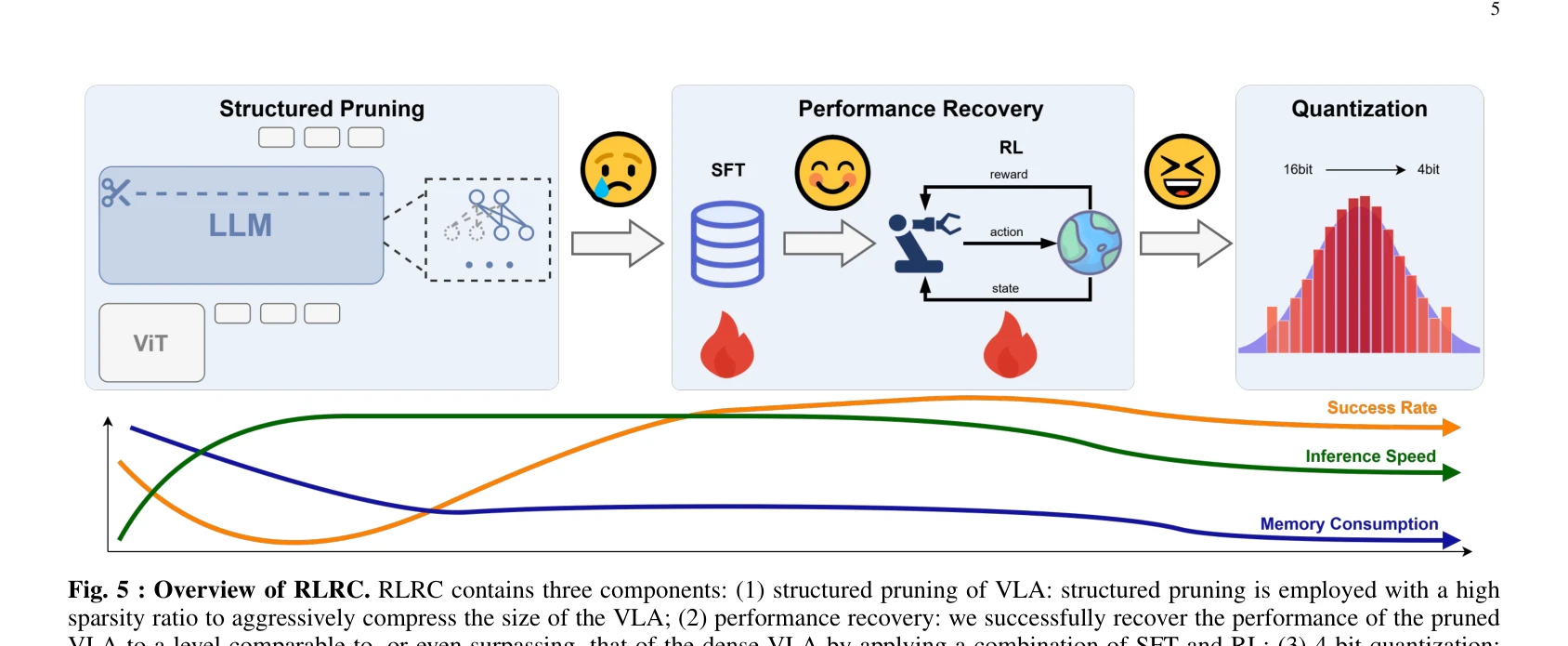
Fig. 5 : Overview of RLRC. RLRC contains three components: (1) structured pruning of VLA: structured pruning is employed
총평: RLRC는 VLA 압축을 위한 실용적이고 포괄적인 파이프라인을 제시하며, RL 기반 성능 복구라는 창의적 접근으로 기존 압축 방법을 능가한다. 자원 제약 로봇 환경에서의 VLA 배포 가능성을 크게 향상시킨다.