How
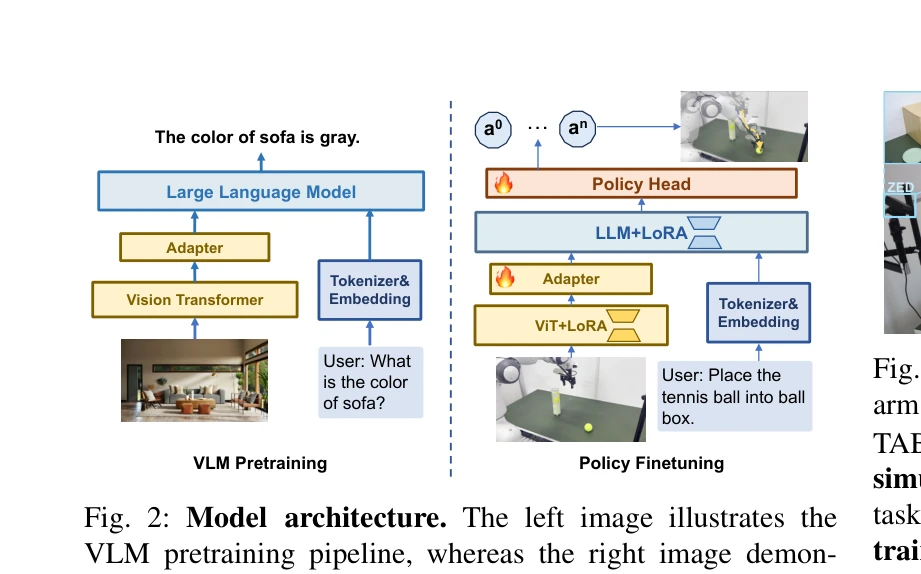
Fig. 2: Model architecture. The left image illustrates the
- 경량 VLM 구축: Pythia 언어 모델과 LLaVA 데이터셋을 활용하여 70M~1.4B 매개변수 규모의 컴팩트한 vision-language 모델 학습
- LoRA 기반 효율적 미세조정: 사전학습된 VLM의 가중치를 고정하고 LoRA를 통해 전체 매개변수의 5%만 학습 가능하도록 설정
- Policy decoder 통합: 사전학습된 multimodal 모델의 출력을 단순 선형 투영을 통해 diffusion policy decoder에 연결
- Diffusion 기반 액션 생성: 자동회귀 토큰 예측 대신 diffusion 모델을 이용한 직접 로봇 액션 출력으로 추론 속도 개선