저자: Zhaowei Wang, Hongming Zhang, Tianqing Fang, Ye Tian, Yue Yang, Kaixin Ma, Xiaoman Pan, Yangqiu Song, Dong Yu | 날짜: 2024-10-03 | URL: https://arxiv.org/abs/2410.02730 📄 PDF
Essence
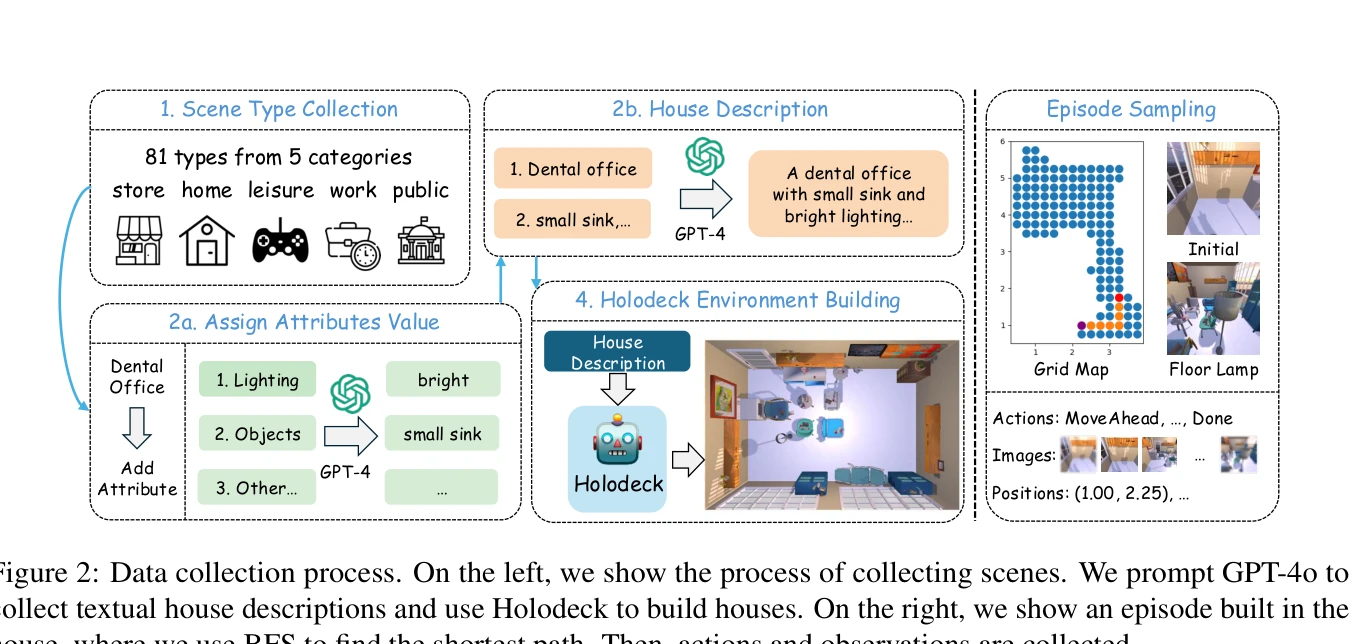
Figure 2: Data collection process. On the left, we show the process of collecting scenes. We prompt GPT-4o to
Large Vision-Language Models (LVLMs)의 embodied 환경 이해와 네비게이션 능력을 탐구하기 위해 81개 장면 유형과 5,707개 객체 범주를 포함하는 대규모 데이터셋 DivScene을 제시하고, CoT 설명을 통한 fine-tuning으로 GPT-4o를 20% 이상 상회하는 성능 달성.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 이 논문은 open-vocabulary object navigation 작업을 처음 체계적으로 정의하고 기존의 100배 이상 다양한 객체를 포함하는 대규모 벤치마크를 제시하여 높은 학술적 기여도를 가짐. LVLM의 embodied AI 능력을 평가하기 위한 중요한 자산을 제공하며, BFS 기반 이모테이션 러닝과 CoT 설명의 조합으로 실용적이고 효율적인 학습 방법을 제시한 점이 탁월함.