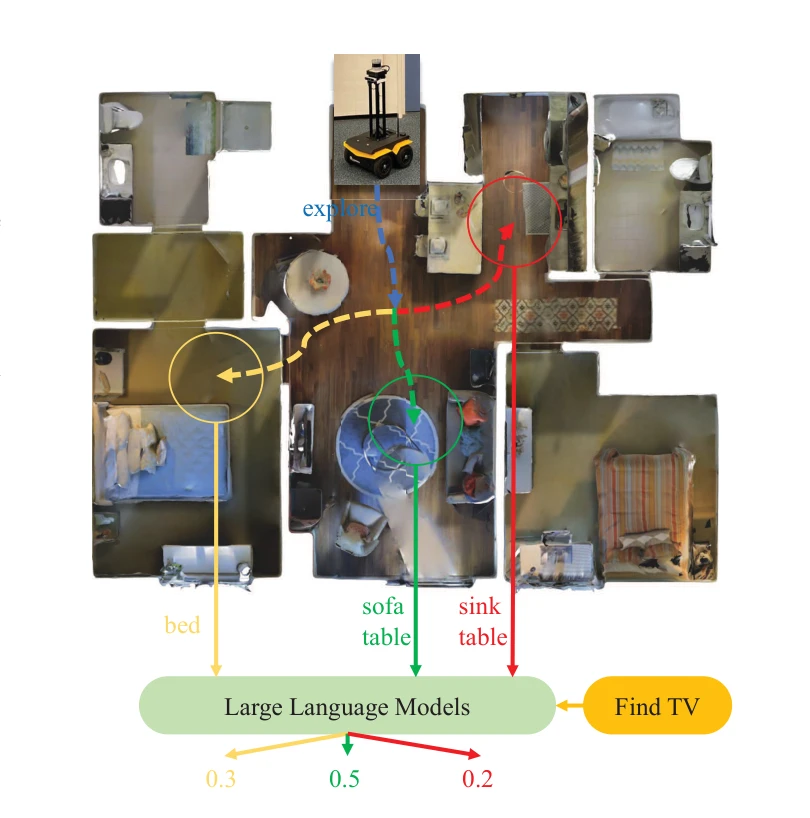
Essence
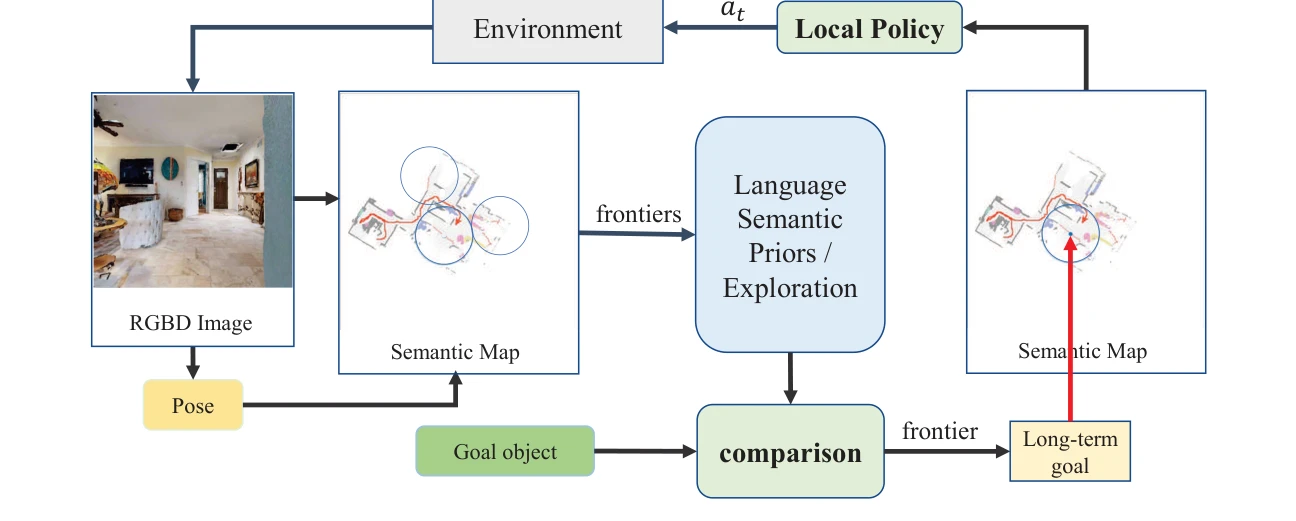
Fig. 2: The architecture of the target navigation framework. The framework takes RGB-D images as input to generate a
대형 언어모델(LLM)을 활용하여 의미적 맵과 프론티어 선택을 통해 미지의 환경에서 시각적 목표 항법을 수행하는 프레임워크를 제안한다. Zero-shot과 feed-forward 두 가지 패러다임으로 상식적 추론을 이용한 효율적 탐색을 달성한다.