저자: Sicong Jiang, Zilin Huang, Kangan Qian, Ziang Luo, Tianze Zhu, Yang Zhong, Yihong Tang, Menglin Kong, Yunlong Wang, Siwen Jiao, Hao Ye, Zihao Sheng, Xin Zhao, Tuopu Wen, Zheng Fu, Sikai Chen, Kun Jiang, Diange Yang, Seongjin Choi, Lijun Sun | 날짜: 2025-06-30 | URL: https://arxiv.org/abs/2506.24044 📄 PDF
Essence
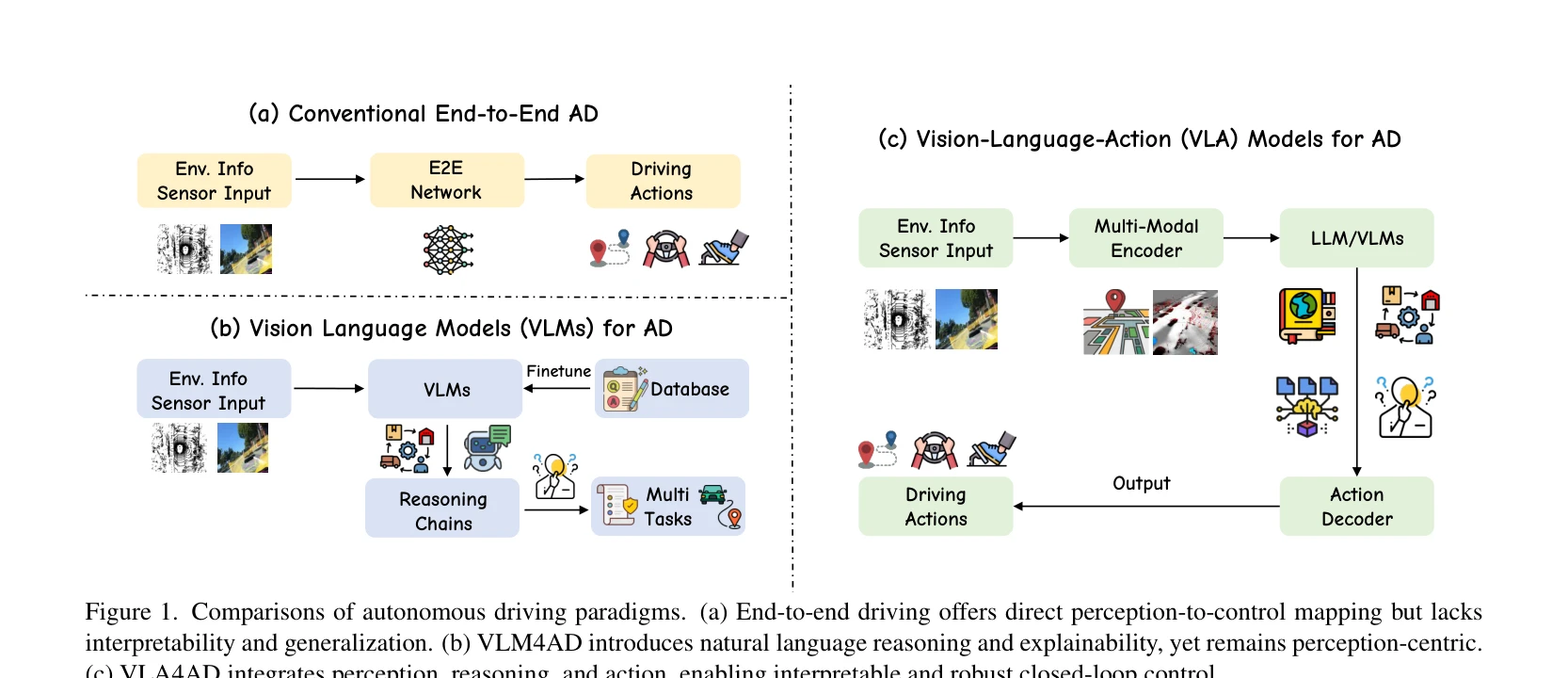
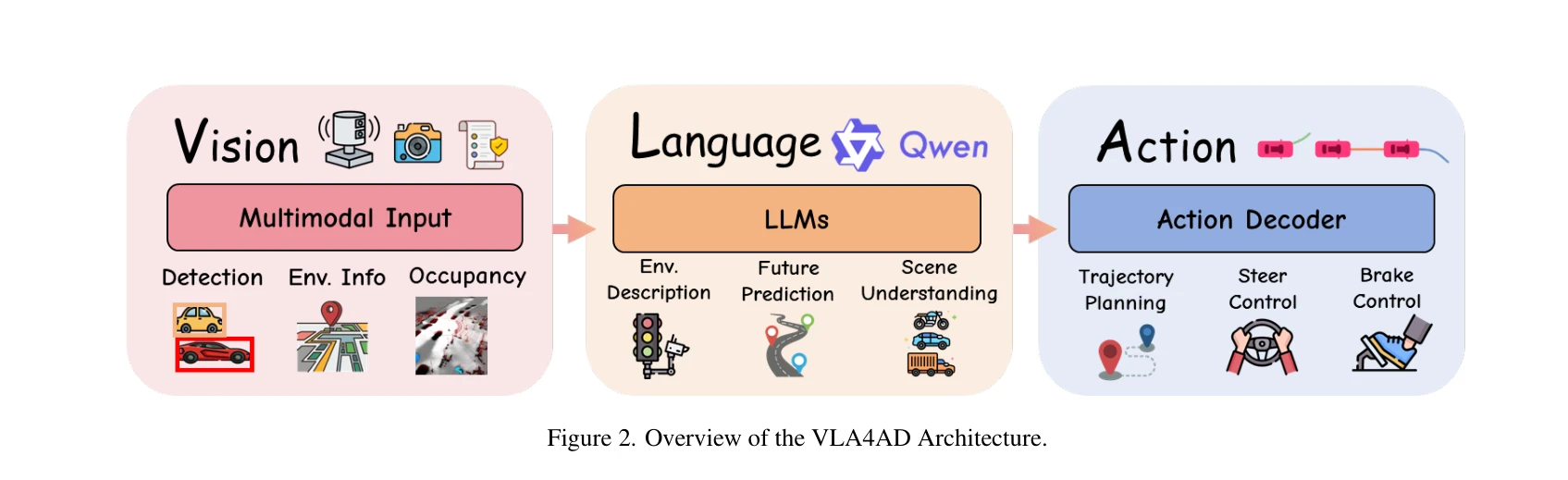
Figure 1. Comparisons of autonomous driving paradigms. (a) End-to-end driving offers direct perception-to-control mappin
본 논문은 Vision-Language-Action (VLA) 모델을 자율주행에 적용하는 최초의 종합 서베이로, 20개 이상의 대표 모델을 분석하고 시각 인식, 자연어 이해, 제어를 통합하는 패러다임의 발전 과정을 추적한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 VLA4AD 분야의 최초의 종합 서베이로서 아키텍처, 진화 과정, 모델 비교를 체계적으로 정리하고 개방 과제를 명확히 정의함으로써, 설명가능하고 견고한 자율주행 시스템 개발을 위한 중요한 참고 자료를 제공한다.