Essence
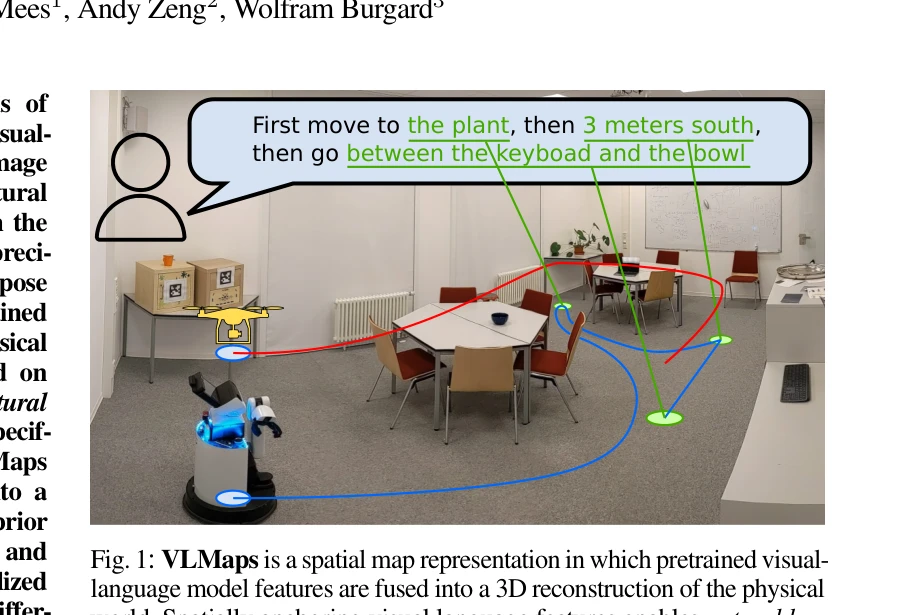
Fig. 1: VLMaps is a spatial map representation in which pretrained visual-
시각-언어 모델의 특징을 3D 재구성과 융합하여 공간 정보를 갖춘 의미론적 지도(VLMaps)를 구축하고, 이를 통해 로봇이 자연어 명령으로 공간 관계를 포함한 복잡한 네비게이션 작업을 수행할 수 있게 한다.
저자: Chenguang Huang, Oier Mees, Andy Zeng, Wolfram Burgard | 날짜: 2022-10-11 | URL: https://arxiv.org/abs/2210.05714 📄 PDF
Fig. 1: VLMaps is a spatial map representation in which pretrained visual-
시각-언어 모델의 특징을 3D 재구성과 융합하여 공간 정보를 갖춘 의미론적 지도(VLMaps)를 구축하고, 이를 통해 로봇이 자연어 명령으로 공간 관계를 포함한 복잡한 네비게이션 작업을 수행할 수 있게 한다.
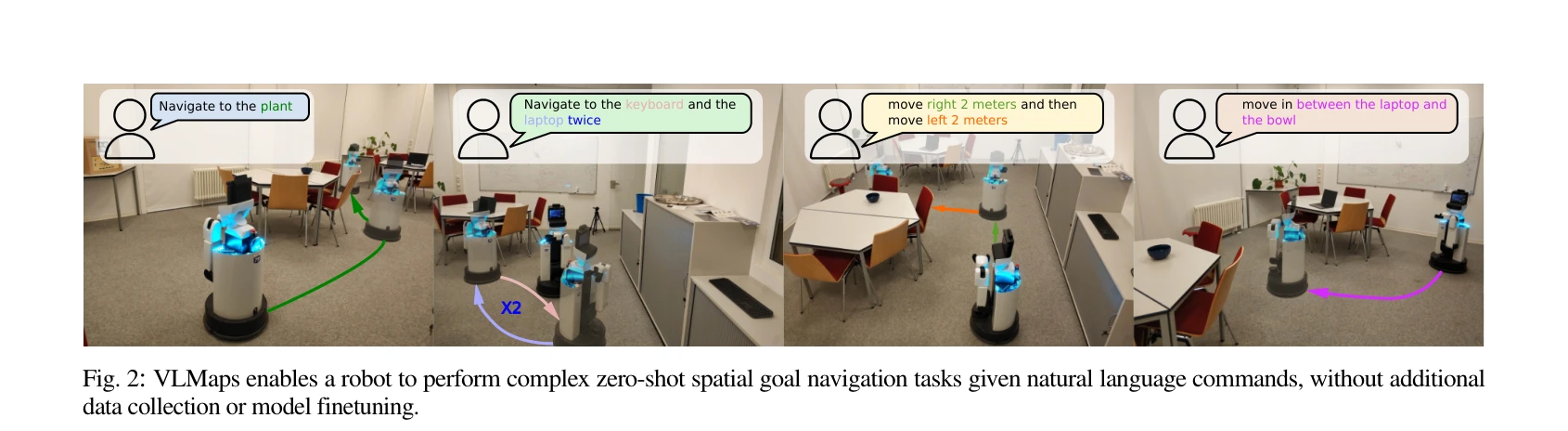
Fig. 2: VLMaps enables a robot to perform complex zero-shot spatial goal navigation tasks given natural language command
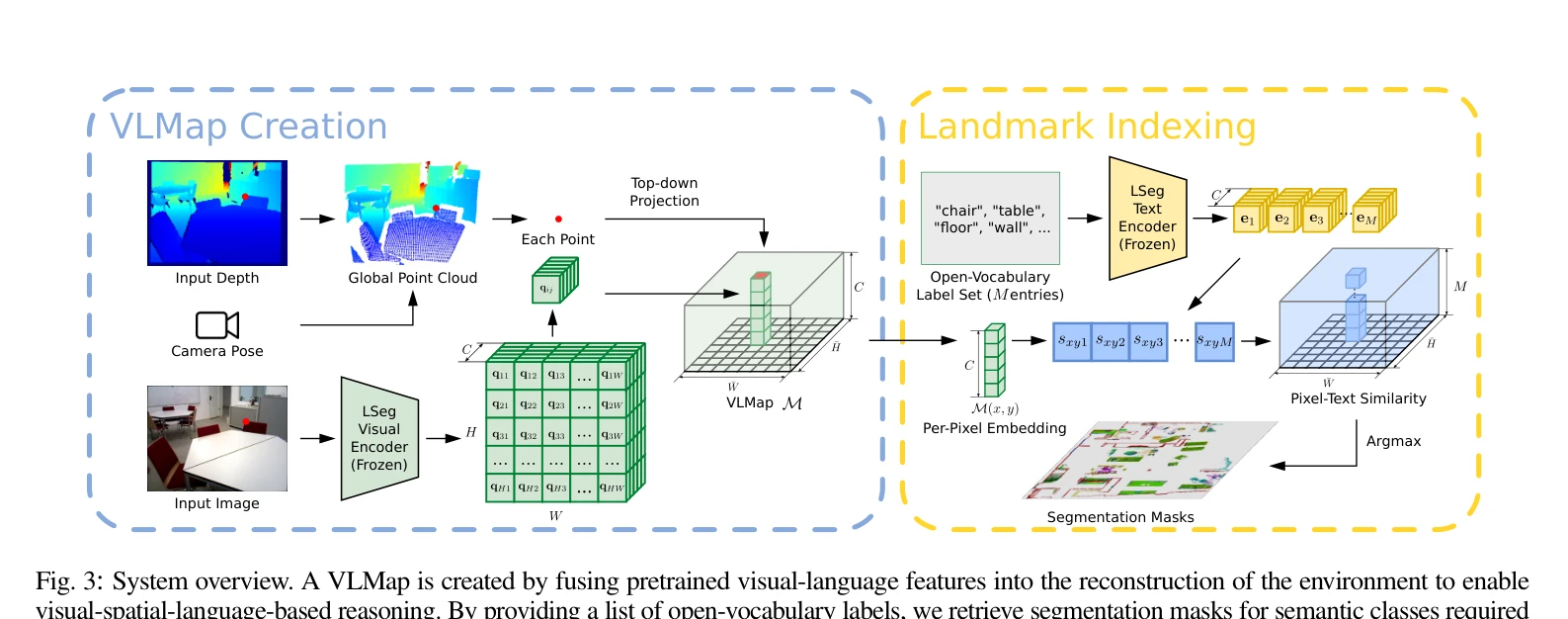
Fig. 3: System overview. A VLMap is created by fusing pretrained visual-language features into the reconstruction of the
총평: VLMaps는 사전훈련 VLM과 3D 재구성을 창의적으로 통합하여 공간-의미론적 네비게이션이라는 중요한 문제를 해결하며, 광범위한 실험으로 기존 방법 대비 우월성을 입증한 우수한 연구이다. 다만 센서 정확도, 실외 환경, 동적 장애물 등에 대한 제약 논의가 추가되면 더욱 완성도 높을 것이다.