Essence
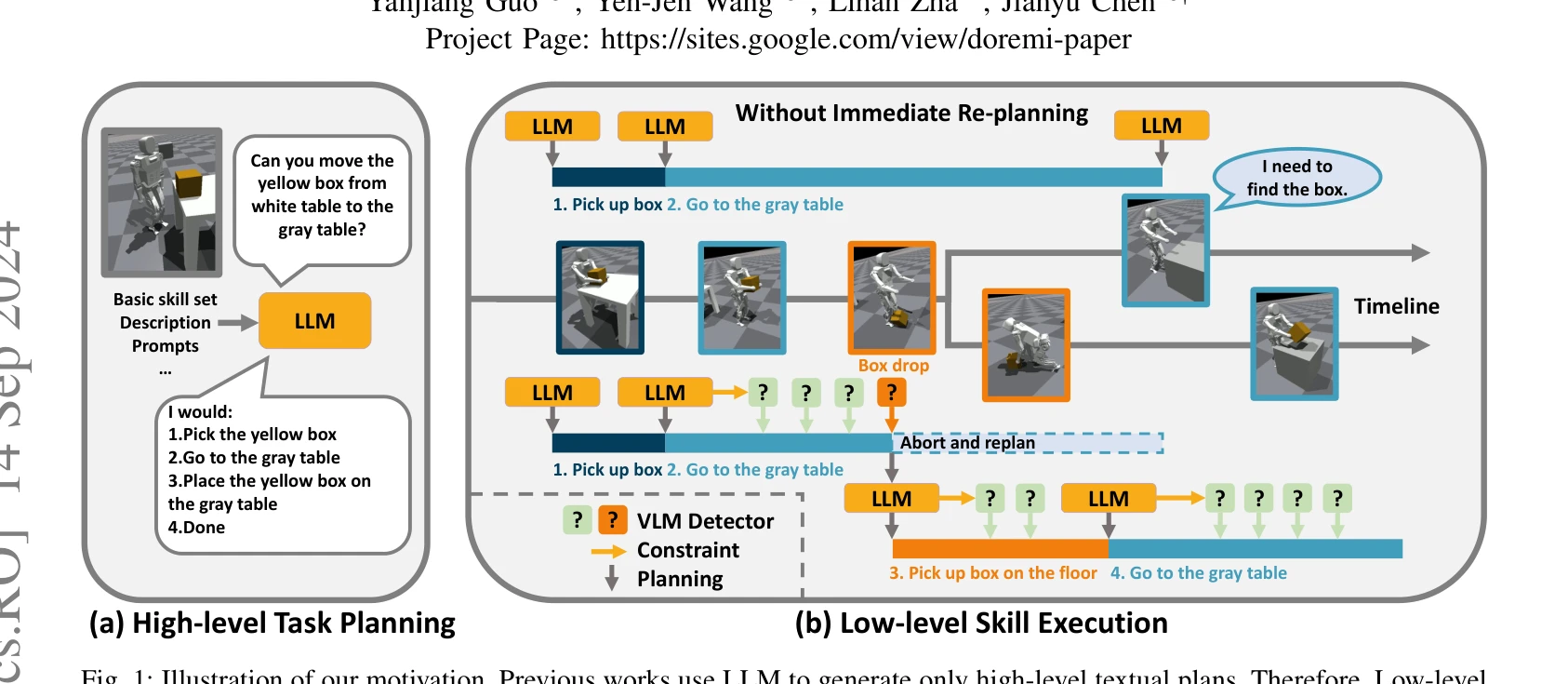
Fig. 1: Illustration of our motivation. Previous works use LLM to generate only high-level textual plans. Therefore, Low
DoReMi는 LLM으로 고수준 계획과 실행 제약조건을 동시에 생성하고, VLM으로 실행 중 제약 위반을 지속적으로 감지하여 계획-실행 불일치를 즉시 탐지하고 복구하는 로봇 작업 프레임워크이다.
저자: Yanjiang Guo, Yen-Jen Wang, Lihan Zha, Jianyu Chen | 날짜: 2023-07-01 | URL: https://arxiv.org/abs/2307.00329 📄 PDF
Fig. 1: Illustration of our motivation. Previous works use LLM to generate only high-level textual plans. Therefore, Low
DoReMi는 LLM으로 고수준 계획과 실행 제약조건을 동시에 생성하고, VLM으로 실행 중 제약 위반을 지속적으로 감지하여 계획-실행 불일치를 즉시 탐지하고 복구하는 로봇 작업 프레임워크이다.
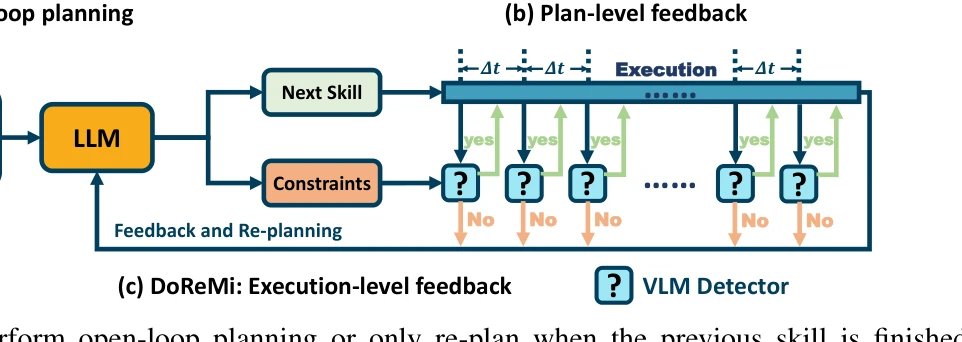
Fig. 2: Previous methods perform open-loop planning or only re-plan when the previous skill is finished. Our DoReMi
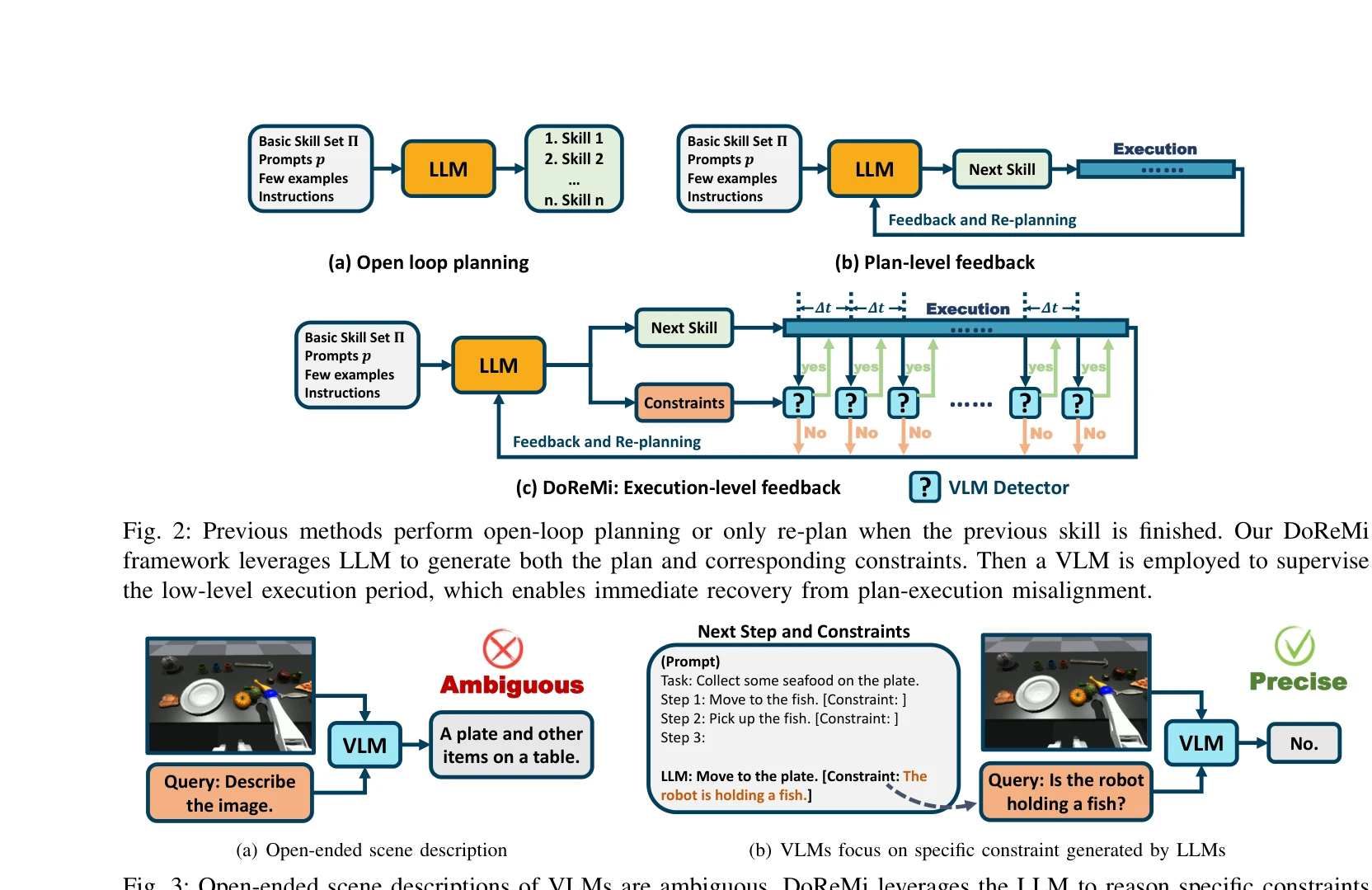
Fig. 3: Open-ended scene descriptions of VLMs are ambiguous. DoReMi leverages the LLM to reason specific constraints
총평: DoReMi는 LLM과 VLM을 창의적으로 결합하여 로봇 작업의 계획-실행 불일치 문제를 즉시 감지하고 복구하는 실용적인 프레임워크를 제시했으며, 명확한 동기, 체계적인 방법론, 견실한 실험을 통해 높은 학술적 가치와 로봇 제어 분야의 실질적 기여를 입증했다.