Essence
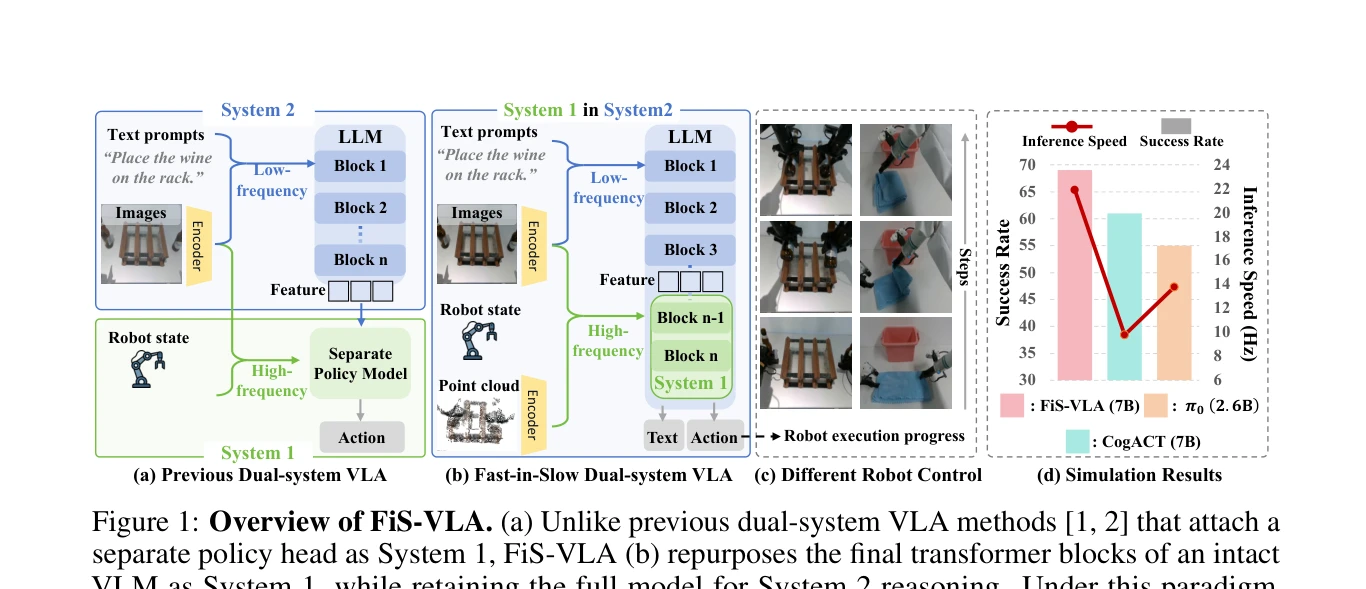
Figure 1: Overview of FiS-VLA. (a) Unlike previous dual-system VLA methods [1, 2] that attach a
Fast-in-Slow (FiS)는 VLM 기반의 System 2 내부에 System 1 실행 모듈을 매개변수 공유로 통합한 통합 dual-system VLA 모델로, 고속 제어와 추론 능력을 동시에 달성한다.
저자: Hao Chen, Jiaming Liu, Chenyang Gu, Zhuoyang Liu, Renrui Zhang, Xiaoqi Li, Xiao He, Yandong Guo, Chi-Wing Fu, Shanghang Zhang, Pheng-Ann Heng | 날짜: 2025-06-02 | URL: https://arxiv.org/abs/2506.01953 📄 PDF
Figure 1: Overview of FiS-VLA. (a) Unlike previous dual-system VLA methods [1, 2] that attach a
Fast-in-Slow (FiS)는 VLM 기반의 System 2 내부에 System 1 실행 모듈을 매개변수 공유로 통합한 통합 dual-system VLA 모델로, 고속 제어와 추론 능력을 동시에 달성한다.
Figure 1: Overview of FiS-VLA. (a) Unlike previous dual-system VLA methods [1, 2] that attach a
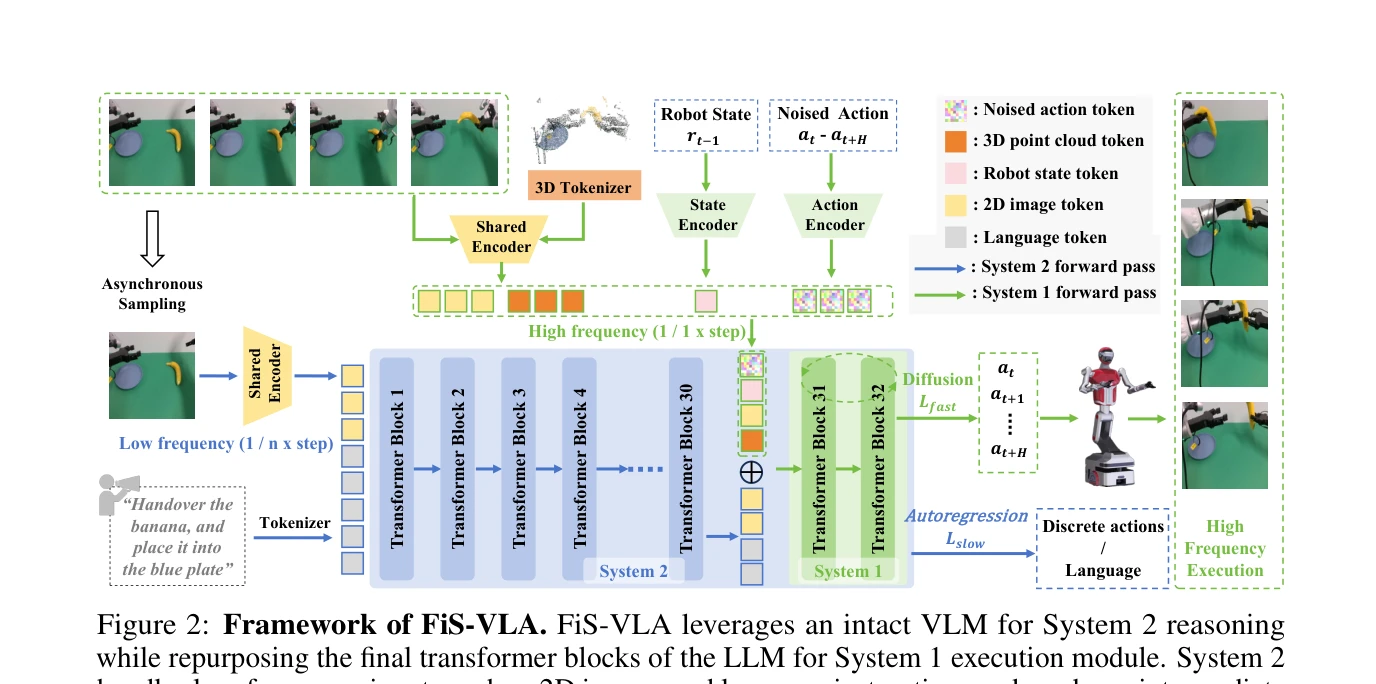
Figure 2: Framework of FiS-VLA. FiS-VLA leverages an intact VLM for System 2 reasoning
총평: FiS-VLA는 dual-system VLA의 구조적 한계를 혁신적으로 해결하고 높은 제어 빈도와 추론 능력을 동시에 달성한 중요한 기여이며, 매개변수 공유를 통한 통합 설계와 이질적 입력/주파수의 체계적 활용이 로봇 조작 분야에 큰 영향을 미칠 것으로 예상된다.