저자: Baining Zhao, Ziyou Wang, Jianjie Fang, Chen Gao, Fanhang Man, Jinqiang Cui, Xin Wang, Xinlei Chen, Yong Li, Wenwu Zhu | 날짜: 2025-04-17 | URL: https://arxiv.org/abs/2504.12680 📄 PDF
Essence
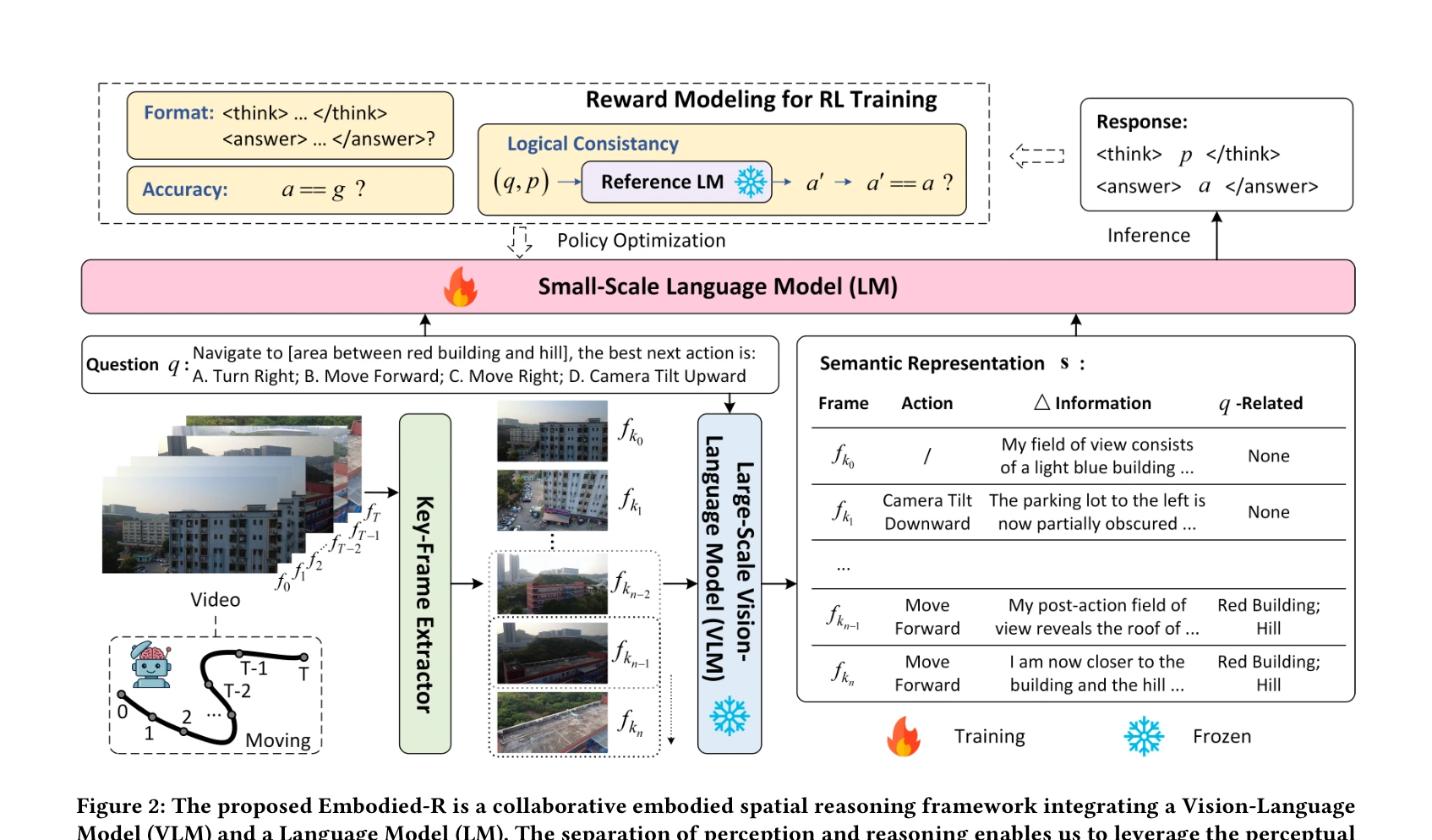
Figure 2: The proposed Embodied-R is a collaborative embodied spatial reasoning framework integrating a Vision-Language
Embodied-R은 대규모 Vision-Language Model(VLM)과 소규모 Language Model(LM)을 협력시키고 RL을 통해 embodied video에서의 spatial reasoning 능력을 활성화하는 프레임워크이다. 단 5k개의 embodied video 샘플로 훈련하여 OpenAI-o1, Gemini-2.5-pro 수준의 성능을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: embodied spatial reasoning에 RL을 처음 적용하고 대규모-소규모 모델의 협력이라는 창의적 설계로 competitive한 성능을 달성한 중요한 연구이다. 다만 reward design의 일반성과 새로운 task에 대한 generalization 능력 검증이 향후 과제이다.
