Essence

Fig. 1: RVT-2 performing high precision tasks. Given a language instruction, a single RVT-2 model can perform multiple 3
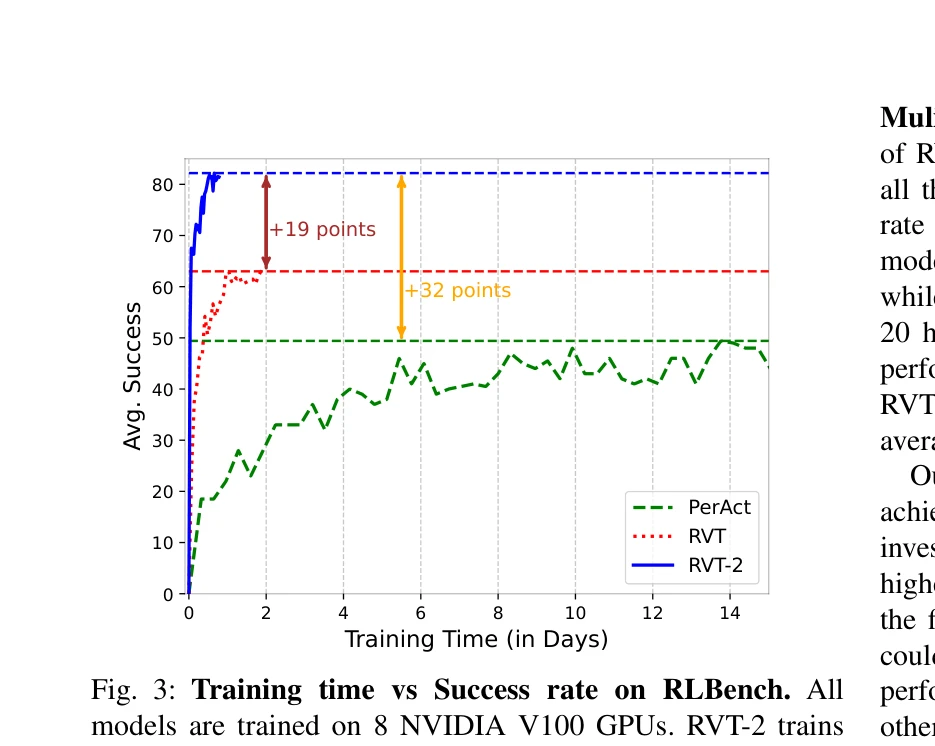
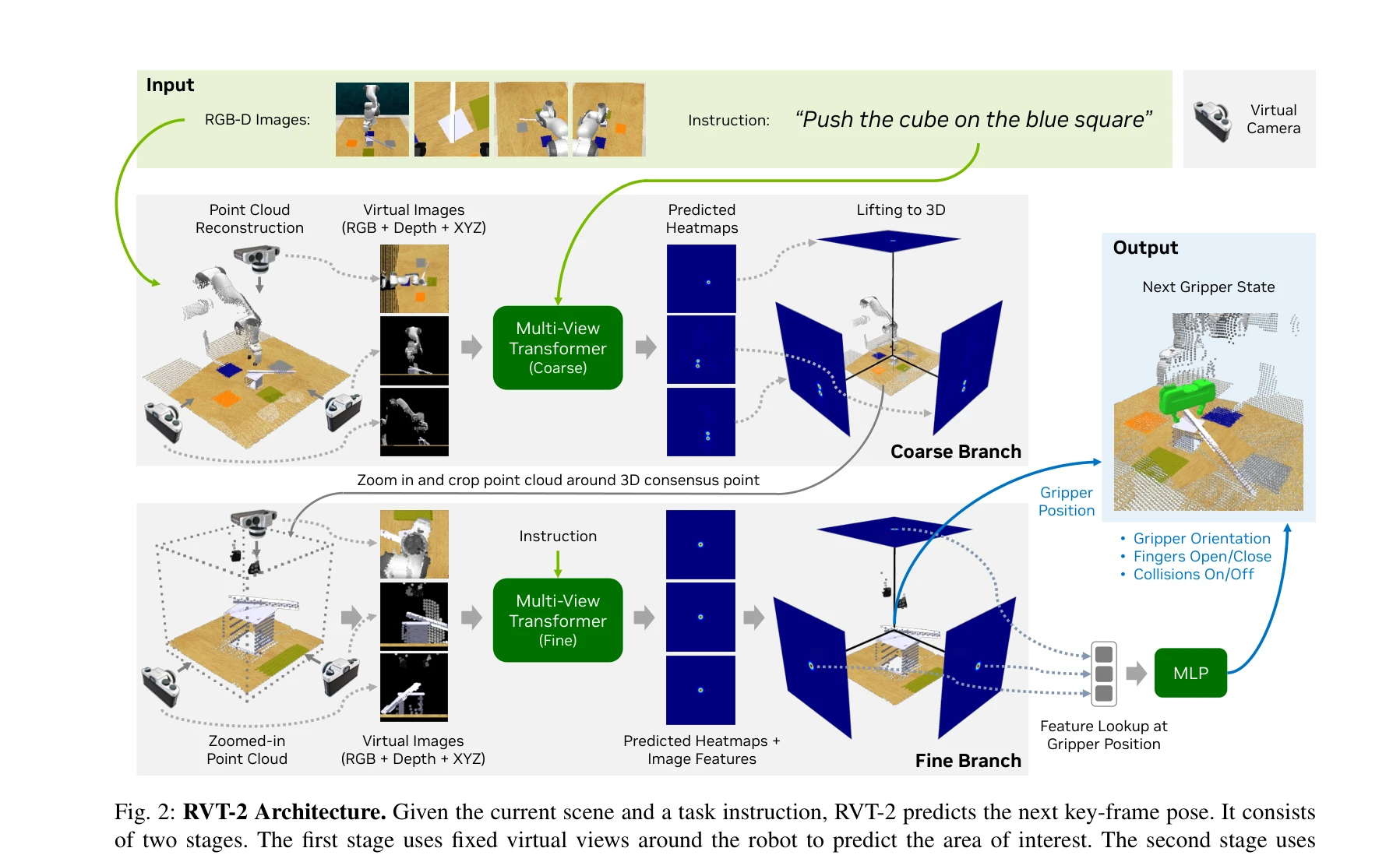
RVT-2는 적은 수의 시연으로부터 고정밀 3D 조작 작업을 학습할 수 있는 멀티태스크 로봇 조작 모델로, 이전 RVT 대비 6배 빠른 학습 속도와 2배 빠른 추론 속도를 달성하면서 RLBench에서 82%의 최고 성능을 달성했다.