Essence

Figure 1: Human is able to complete a long-horizon task much faster than a teleoperated robot. This
MimicPlay는 저비용의 인간 플레이 데이터에서 고수준 계획을 학습하고 소량의 원격조종 데이터에서 저수준 제어 정책을 학습하는 계층적 모방 학습 프레임워크로, 장기 조작 작업의 데이터 효율성을 대폭 향상시킨다.
저자: Chen Wang, Linxi Fan, Jiankai Sun, Ruohan Zhang, Li Fei-Fei, Danfei Xu, Yuke Zhu, Anima Anandkumar | 날짜: 2023-02-24 | URL: https://arxiv.org/abs/2302.12422 📄 PDF
Figure 1: Human is able to complete a long-horizon task much faster than a teleoperated robot. This
MimicPlay는 저비용의 인간 플레이 데이터에서 고수준 계획을 학습하고 소량의 원격조종 데이터에서 저수준 제어 정책을 학습하는 계층적 모방 학습 프레임워크로, 장기 조작 작업의 데이터 효율성을 대폭 향상시킨다.
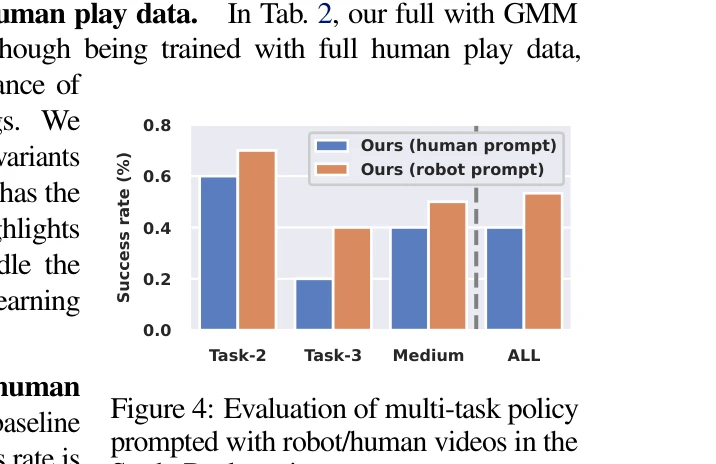
Figure 4: Evaluation of multi-task policy

Figure 2: Overview of MIMICPLAY. (a) Training Stage 1: using cheap human play data to train a
총평: MimicPlay는 데이터 수집 비용이라는 모방 학습의 근본적 문제를 창의적으로 해결하면서 실제 로봇 작업에서 우수한 성능을 입증한 의미있는 연구이다. 인간과 로봇 데이터의 상보적 활용이라는 새로운 패러다임은 로봇 학습의 확장성을 크게 향상시킬 수 있는 잠재력을 보여준다.