Achievement
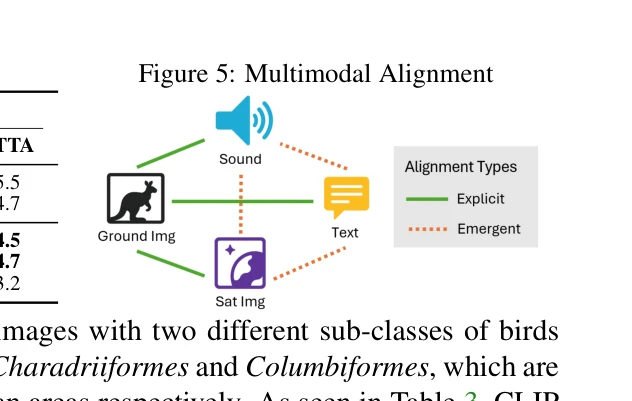
Figure 5: Multimodal Alignment
- 성능 개선: Search-TTA는 계획자 성능을 최대 30.0%, 확률 맵 분포를 8.5% 향상시키며, 특히 CLIP 예측이 부족한 경우에서 두드러진다.
- 멀티모달 정렬: 텍스트 및 음성 모달리티에 대해 추가 학습 없이 제로샷 일반화를 달성하며 emergent alignment를 시연한다.
- 규모 있는 VLM 비교: 훨씬 더 큰 VLM과 비교할 수 있는 성능을 보이면서도 경량이다.
- 실제 배포: 하드웨어인루프 테스트를 통해 실제 UAV에서 동작 가능함을 입증한다.
- 새로운 벤치마크: 인터넷규모 생태계 데이터 기반 380k 학습 이미지와 8k 검증 이미지를 포함한 AVS-Bench 데이터셋을 공개한다.