Essence
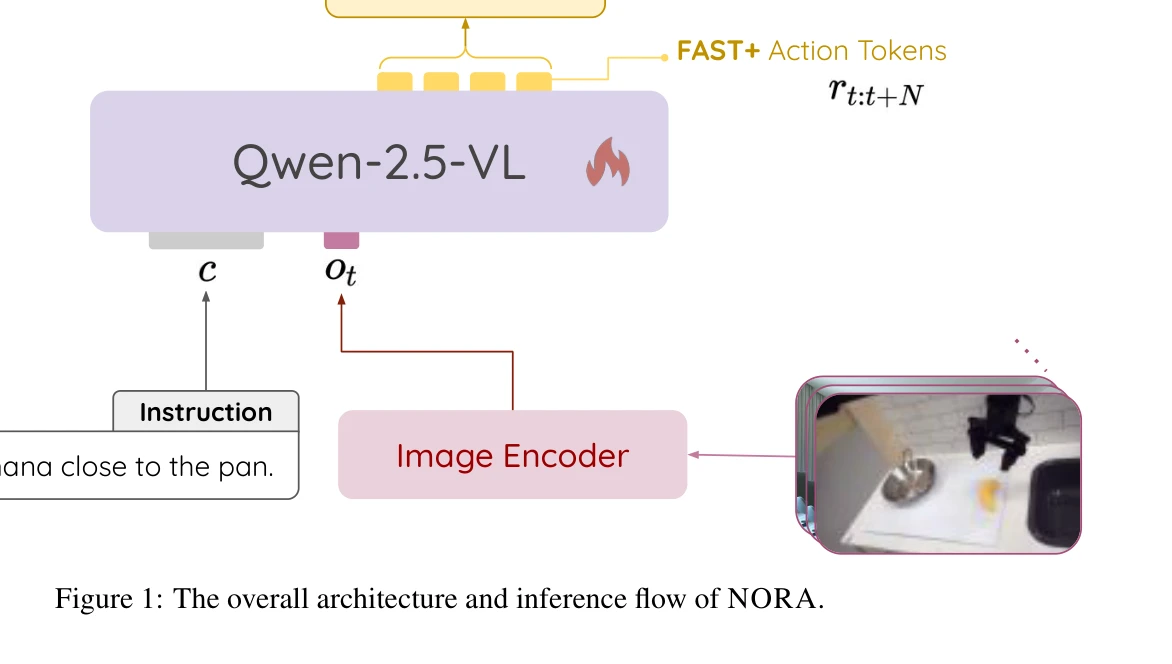
Figure 1: The overall architecture and inference flow of NORA.
NORA는 3B 파라미터의 경량 Vision-Language-Action 모델로, 기존 7B 이상의 대규모 VLA 모델보다 계산 효율을 크게 개선하면서도 실시간 로봇 제어 성능을 유지한다.
저자: Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U-Xuan Tan, Navonil Majumder, Soujanya Poria | 날짜: 2025-04-28 | URL: https://arxiv.org/abs/2504.19854 📄 PDF
Figure 1: The overall architecture and inference flow of NORA.
NORA는 3B 파라미터의 경량 Vision-Language-Action 모델로, 기존 7B 이상의 대규모 VLA 모델보다 계산 효율을 크게 개선하면서도 실시간 로봇 제어 성능을 유지한다.
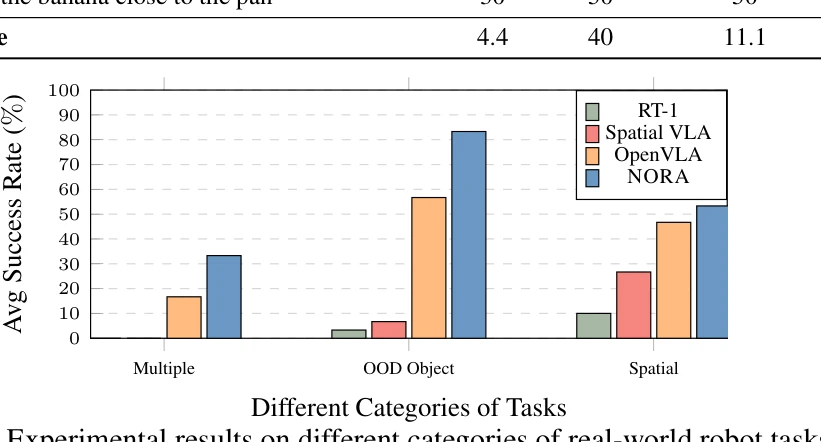
Figure 4: Experimental results on different categories of real-world robot tasks.
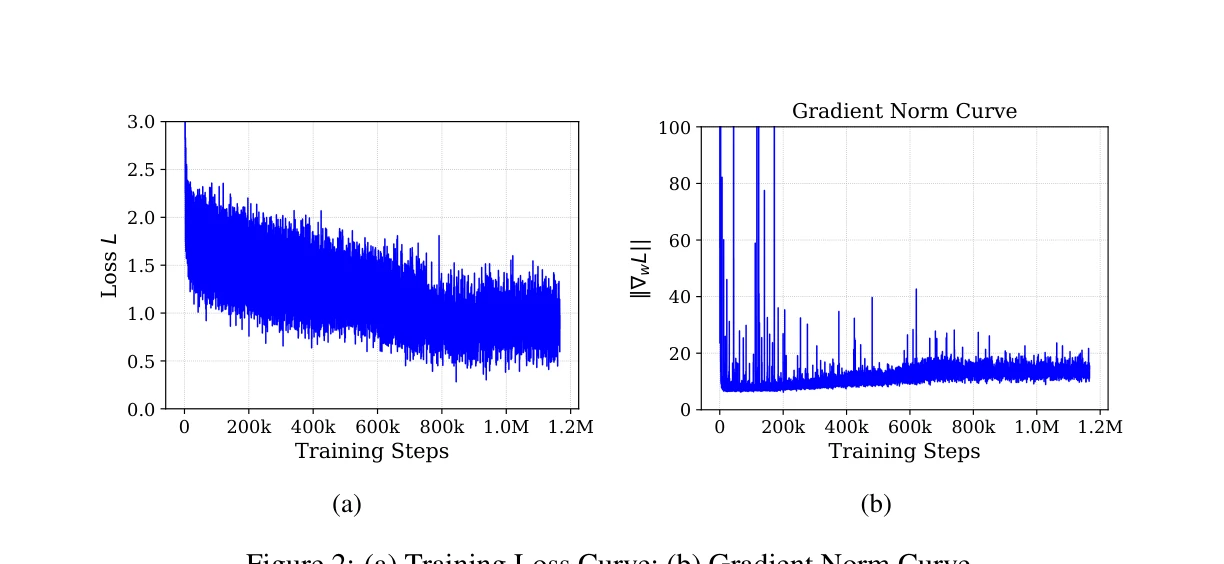
Figure 2: (a) Training Loss Curve; (b) Gradient Norm Curve.
총평: NORA는 경량 VLA 모델의 실용적 필요성을 잘 해결한 의미 있는 기여로, 3B 파라미터로 대규모 모델 대비 우수한 성능을 달성하면서 실시간 로봇 제어를 가능하게 한다. 오픈 소스 공개로 후속 연구를 촉진할 것으로 예상된다.