Essence
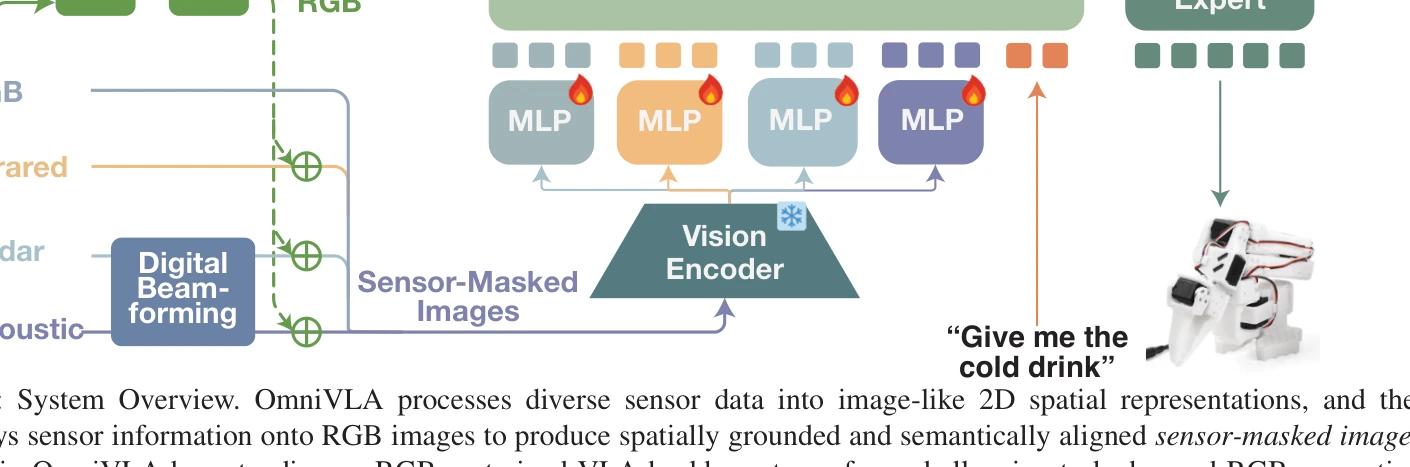
Fig. 2: System Overview. OmniVLA processes diverse sensor data into image-like 2D spatial representations, and then
OmniVLA는 RGB, 적외선, mmWave 레이더, 음향 마이크로폰 등 다중 센서를 통합하는 최초의 VLA 모델로, 센서-마스크된 이미지라는 통일된 표현을 통해 물리적 정보가 포함된 로봇 조작을 가능하게 한다.
저자: Heyu Guo, Shanmu Wang, Ruichun Ma, Shiqi Jiang, Yasaman Ghasempour, Omid Abari, Baining Guo, Lili Qiu | 날짜: 2025-11-03 | URL: https://arxiv.org/abs/2511.01210 📄 PDF
Fig. 2: System Overview. OmniVLA processes diverse sensor data into image-like 2D spatial representations, and then
OmniVLA는 RGB, 적외선, mmWave 레이더, 음향 마이크로폰 등 다중 센서를 통합하는 최초의 VLA 모델로, 센서-마스크된 이미지라는 통일된 표현을 통해 물리적 정보가 포함된 로봇 조작을 가능하게 한다.

Fig. 5: Examples of Robotic Manipulation Task Completion
Fig. 2: System Overview. OmniVLA processes diverse sensor data into image-like 2D spatial representations, and then
총평: OmniVLA는 다중 센서를 VLA에 통합하는 문제에 대해 우아하고 실용적인 솔루션을 제시하며, 센서-마스크된 이미지라는 단순하면서도 효과적인 표현으로 확장 가능성과 데이터 효율성을 동시에 달성한 의미 있는 기여이다.