Essence
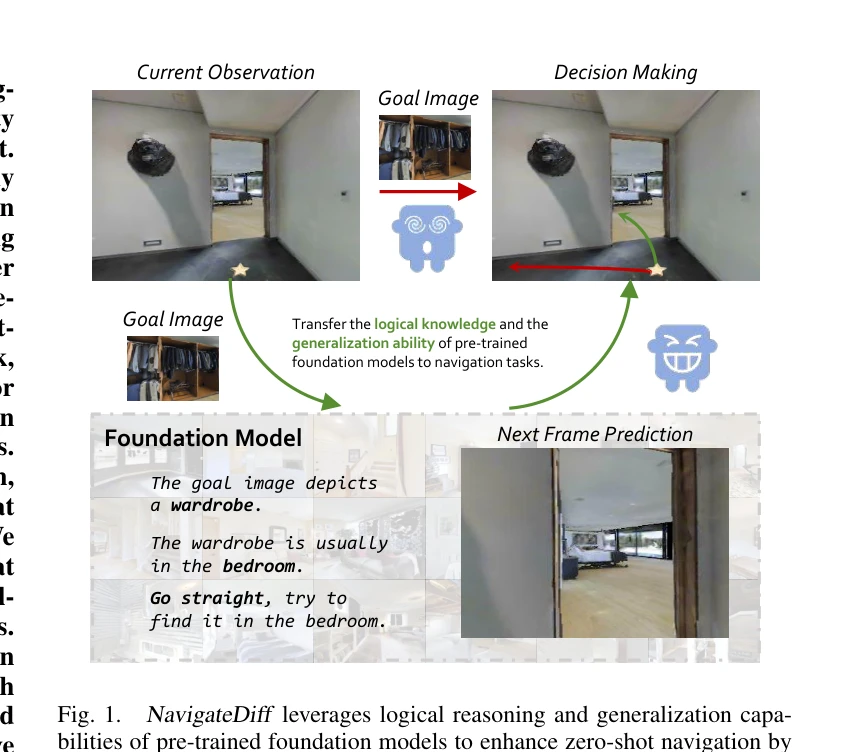
Fig. 1.
NavigateDiff는 vision-language model과 diffusion network를 결합하여 미래 프레임을 예측하는 visual predictor를 구축하고, 이를 통해 로봇이 제로샷(zero-shot) 상황에서 미지의 환경을 효과적으로 네비게이션할 수 있도록 지원한다.
저자: Yiran Qin, Ao Sun, Yuze Hong, Benyou Wang, Ruimao Zhang | 날짜: 2025-02-19 | URL: https://arxiv.org/abs/2502.13894 📄 PDF
Fig. 1.
NavigateDiff는 vision-language model과 diffusion network를 결합하여 미래 프레임을 예측하는 visual predictor를 구축하고, 이를 통해 로봇이 제로샷(zero-shot) 상황에서 미지의 환경을 효과적으로 네비게이션할 수 있도록 지원한다.
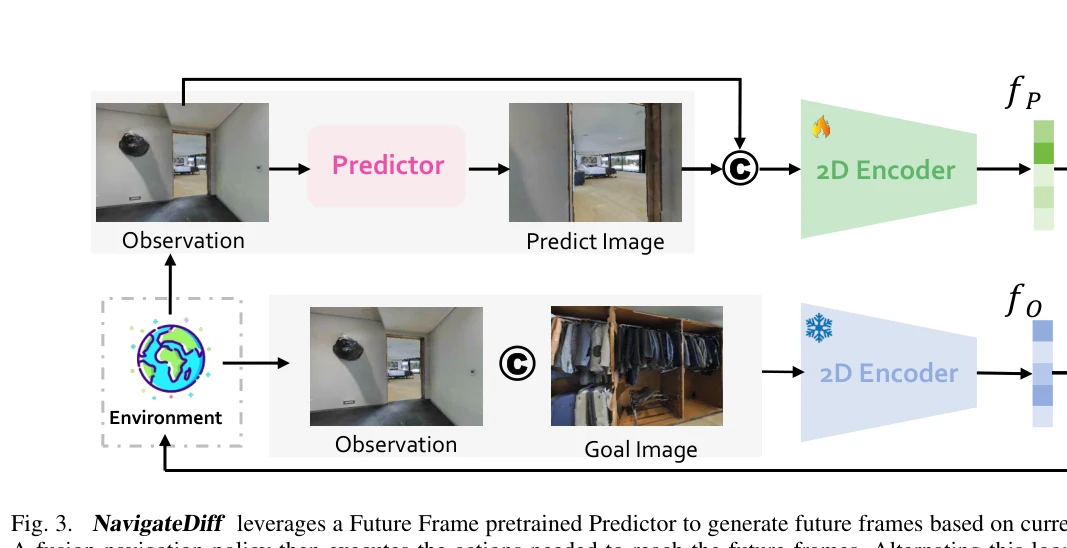
Fig. 3. NavigateDiff leverages a Future Frame pretrained Predictor to generate future frames based on current observatio
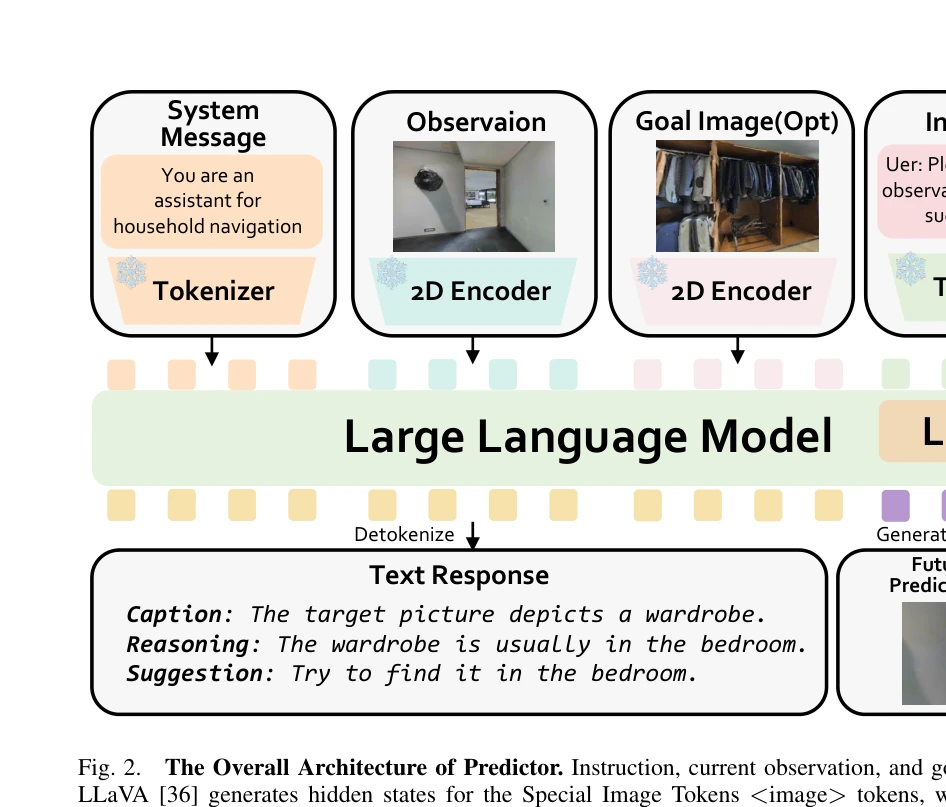
Fig. 2.
총평: NavigateDiff는 foundation model의 논리적 추론 능력과 이미지 생성 능력을 창의적으로 결합하여 zero-shot 네비게이션에 새로운 접근법을 제시한다. 높은 수준의 추론과 저수준의 제어를 분리하는 구조와 미래 프레임 예측을 중간 표현으로 활용하는 아이디어는 로봇 네비게이션 분야에 상당한 기여를 할 수 있는 논문이다.