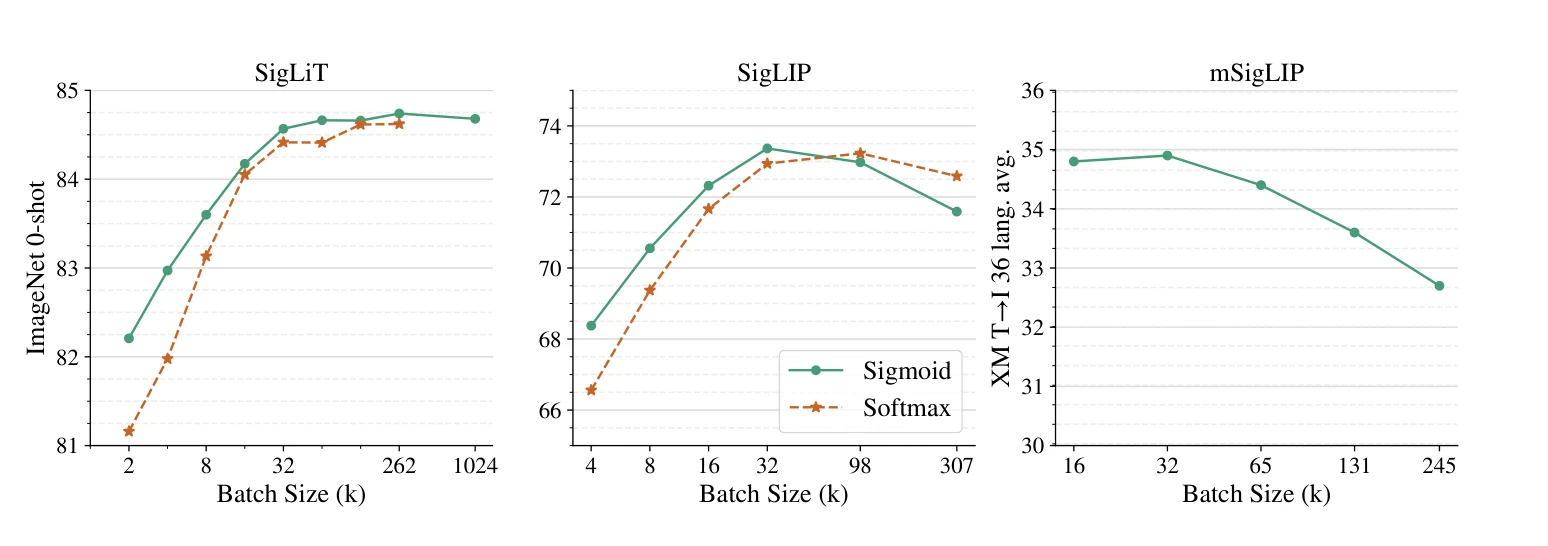
Essence
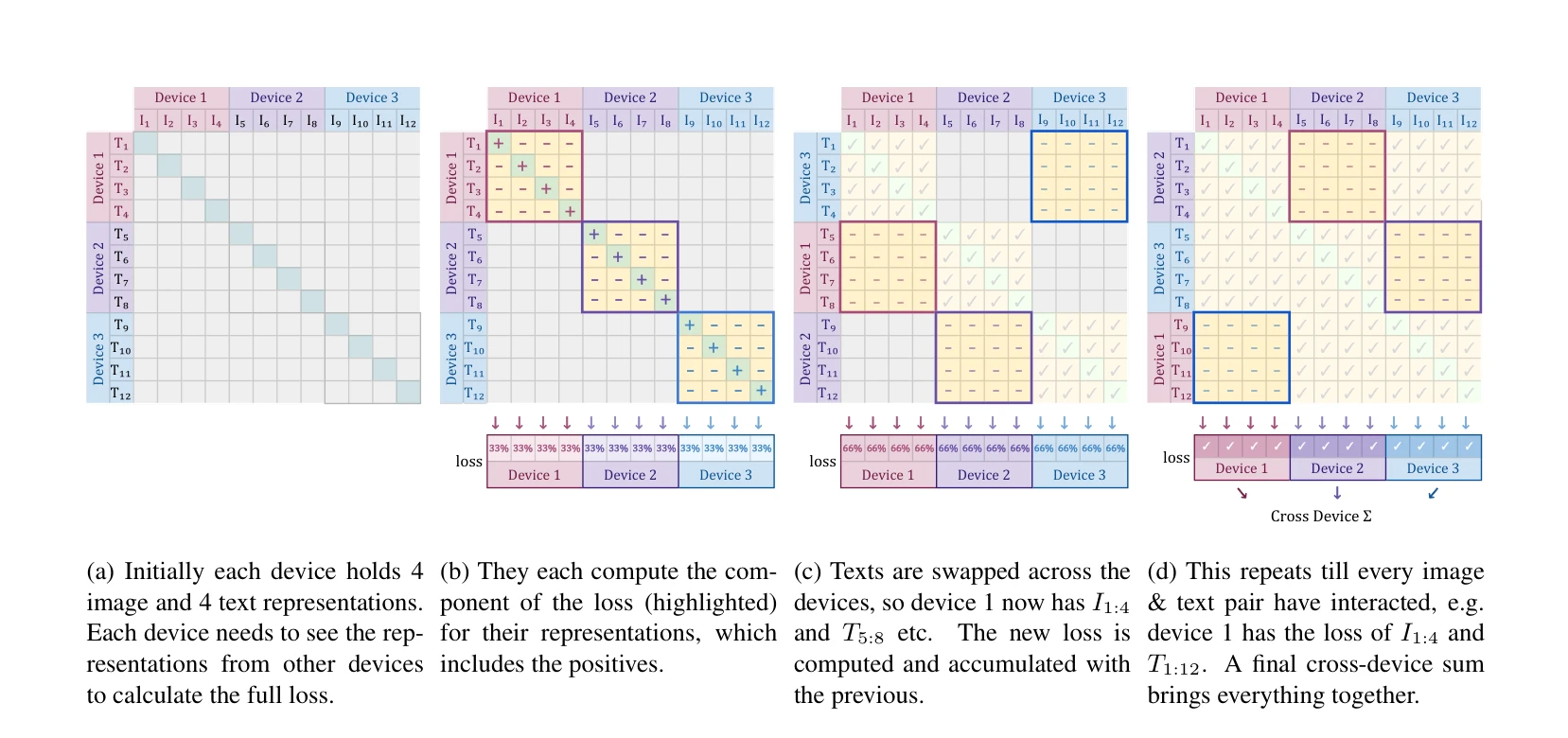
Figure 1: Efficient loss implementation demonstrated via a mock setup with 3 devices and a global batch size of 12. There
Language-Image Pre-training을 위해 softmax 정규화 대신 pairwise sigmoid loss를 제안하며, 이는 배치 크기와 무관하게 작동하여 메모리 효율성을 개선하고 작은 배치 크기에서 더 나은 성능을 달성한다.