Essence
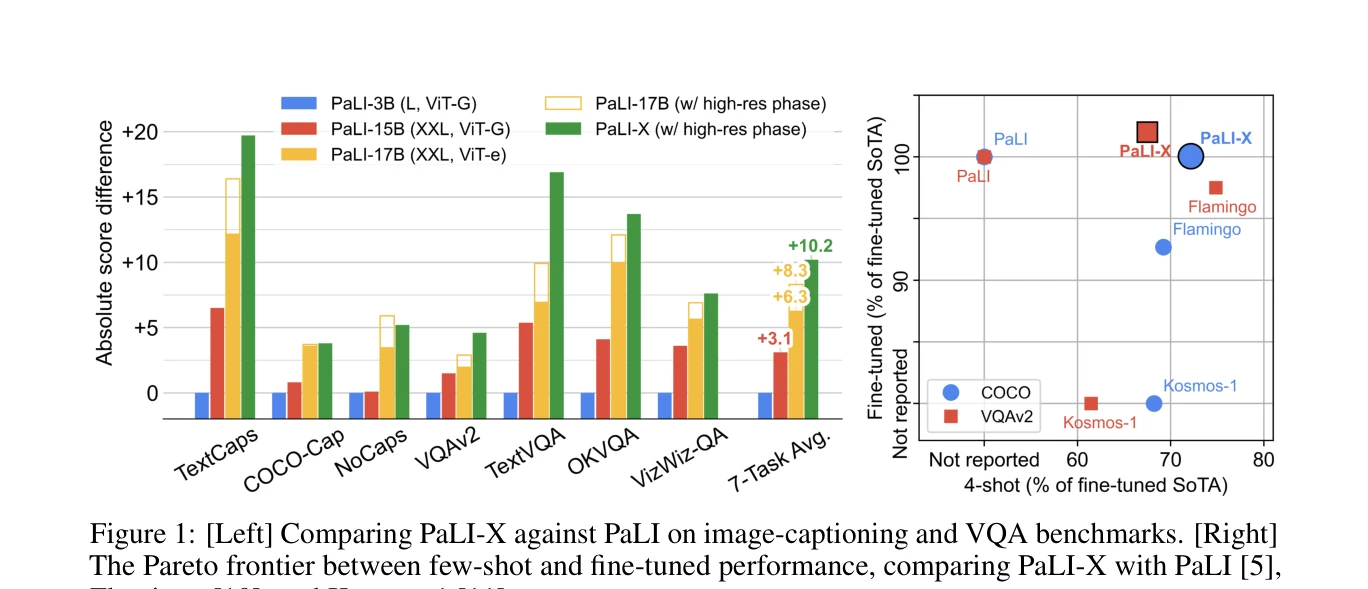
Figure 1: [Left] Comparing PaLI-X against PaLI on image-captioning and VQA benchmarks. [Right]
PaLI-X는 시각 및 언어 컴포넌트를 균형있게 확장한 다국어 비전-언어 모델로, 25개 이상의 벤치마크에서 새로운 최첨단 성능을 달성하며 복잡한 계산과 다국어 객체 검출 같은 새로운 능력을 보여준다.
저자: Xi Chen, Josip Djolonga, Piotr Padlewski, Basil Mustafa, Soravit Changpinyo, Jialin Wu, Carlos Riquelme Ruiz, Sebastian Goodman, Xiao Wang, Yi Tay, Siamak Shakeri, Mostafa Dehghani, Daniel Salz, Mario Lucic, Michael Tschannen, Arsha Nagrani, Hexiang Hu, Mandar Joshi, Bo Pang, Ceslee Montgomery, Paulina Pietrzyk, Marvin Ritter, AJ Piergiovanni, Matthias Minderer, Filip Pavetic, Austin Waters, Gang Li, Ibrahim Alabdulmohsin, Lucas Beyer, Julien Amelot, Kenton Lee, Andreas Peter Steiner, Yang Li, Daniel Keysers, Anurag Arnab, Yuanzhong Xu, Keran Rong, Alexander Kolesnikov, Mojtaba Seyedhosseini, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, Radu Soricut | 날짜: 2023-05-29 | URL: https://arxiv.org/abs/2305.18565 📄 PDF
Figure 1: [Left] Comparing PaLI-X against PaLI on image-captioning and VQA benchmarks. [Right]
PaLI-X는 시각 및 언어 컴포넌트를 균형있게 확장한 다국어 비전-언어 모델로, 25개 이상의 벤치마크에서 새로운 최첨단 성능을 달성하며 복잡한 계산과 다국어 객체 검출 같은 새로운 능력을 보여준다.
Figure 1: [Left] Comparing PaLI-X against PaLI on image-captioning and VQA benchmarks. [Right]
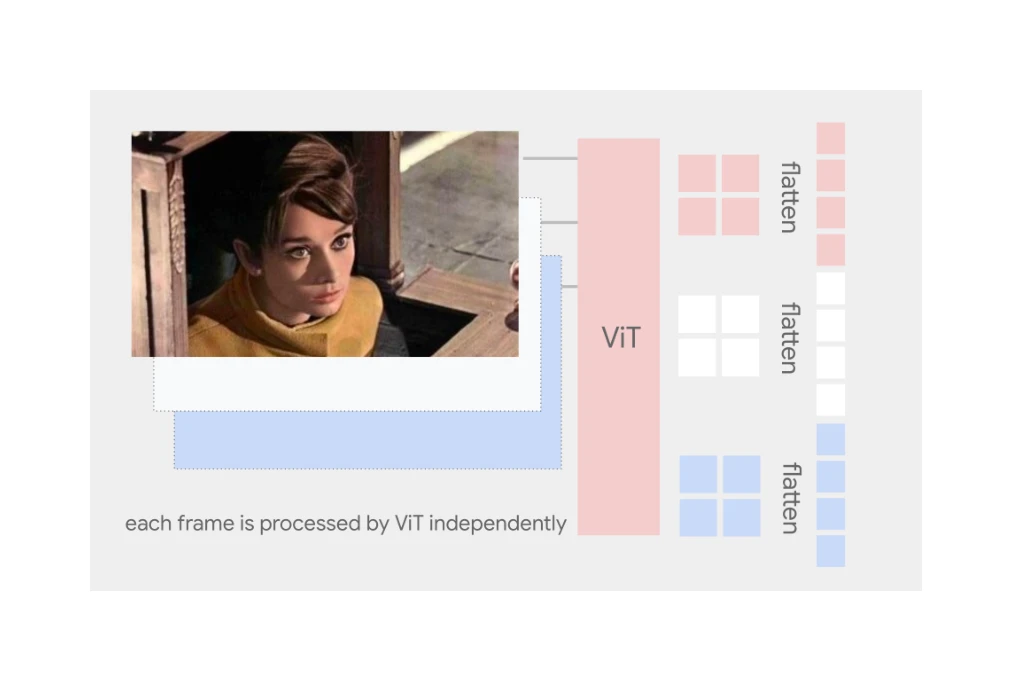
Figure 4: Visual input for videos: each frame is independently processed by ViT; patch embeddings
총평: PaLI-X는 균형잡힌 초대형 비전-언어 모델 확장을 통해 광범위한 작업에서 최첨단 성능을 달성하고 새로운 emergence capability를 보여주는 매우 의미 있는 연구이다. 단, 모델 규모로 인한 실무 적용의 제약과 emergence 메커니즘에 대한 심층 분석이 추가되면 더욱 우수한 논문이 될 것이다.