Essence
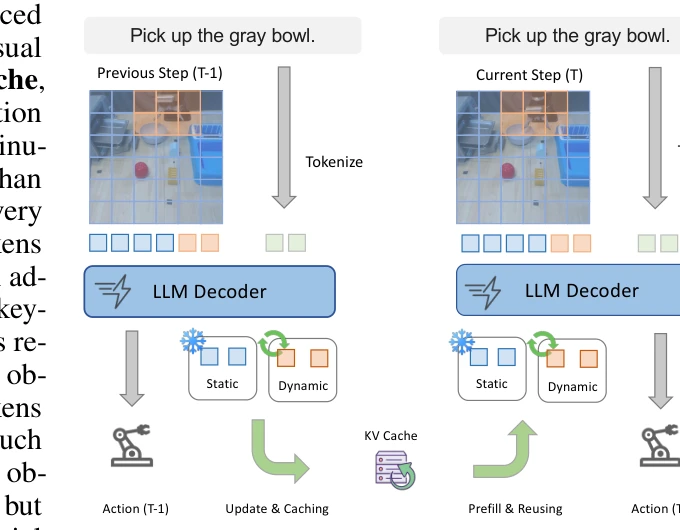
Figure 1: During the inference of the VLA model, static
VLA-Cache는 로봇 조작 작업에서 인접한 프레임 간의 시간적 중복성을 활용하여 정적 시각 토큰의 KV 표현을 캐싱하고 재사용함으로써 Vision-Language-Action 모델의 추론을 가속화하는 학습 불필요 방법이다.
저자: Siyu Xu, Yunke Wang, Chenghao Xia, Dihao Zhu, Tao Huang, Chang Xu | 날짜: 2025-02-04 | URL: https://arxiv.org/abs/2502.02175 📄 PDF
Figure 1: During the inference of the VLA model, static
VLA-Cache는 로봇 조작 작업에서 인접한 프레임 간의 시간적 중복성을 활용하여 정적 시각 토큰의 KV 표현을 캐싱하고 재사용함으로써 Vision-Language-Action 모델의 추론을 가속화하는 학습 불필요 방법이다.

Figure 4: Visualization of VLA-Cache token reuse across settings. (a) LIBERO simulation with
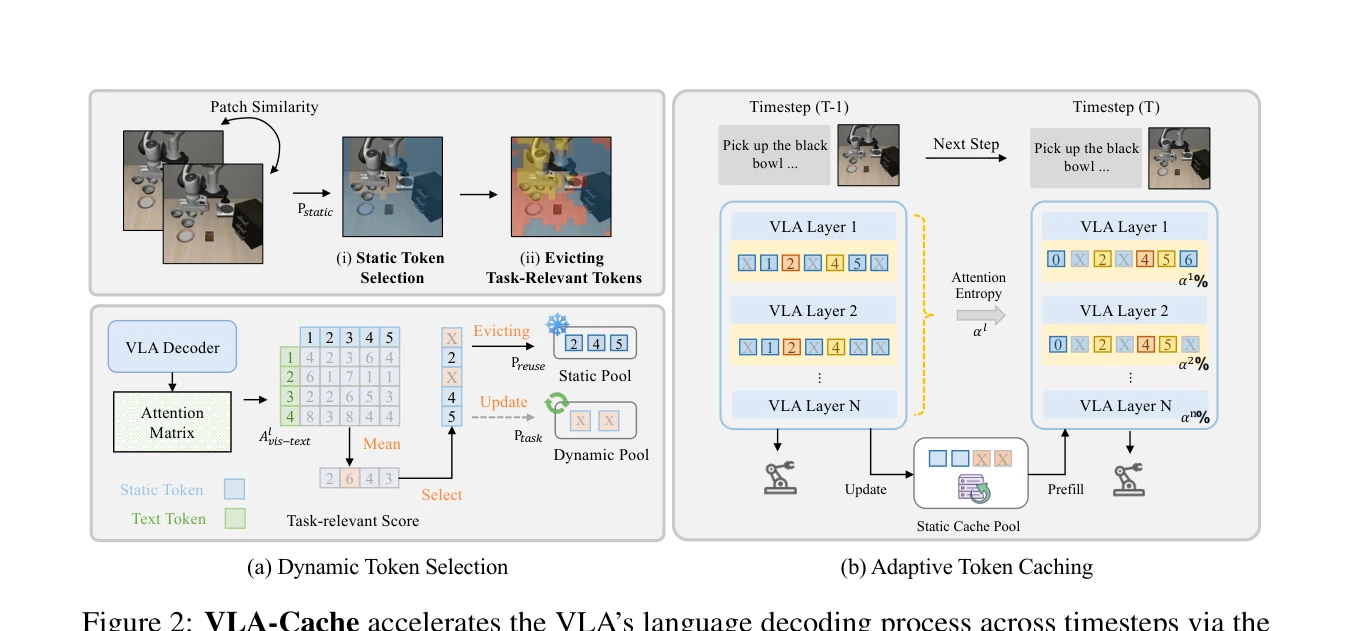
Figure 2: VLA-Cache accelerates the VLA’s language decoding process across timesteps via the
총평: VLA-Cache는 로봇 조작의 시간적 특성을 창의적으로 활용하여 학습 불필요한 상태에서 실질적 추론 가속을 달성한 실용적이고 우수한 연구이다. 작업 관련성 필터링과 layer-adaptive 전략의 정교함과 광범위한 실증이 높은 가치를 제공한다.