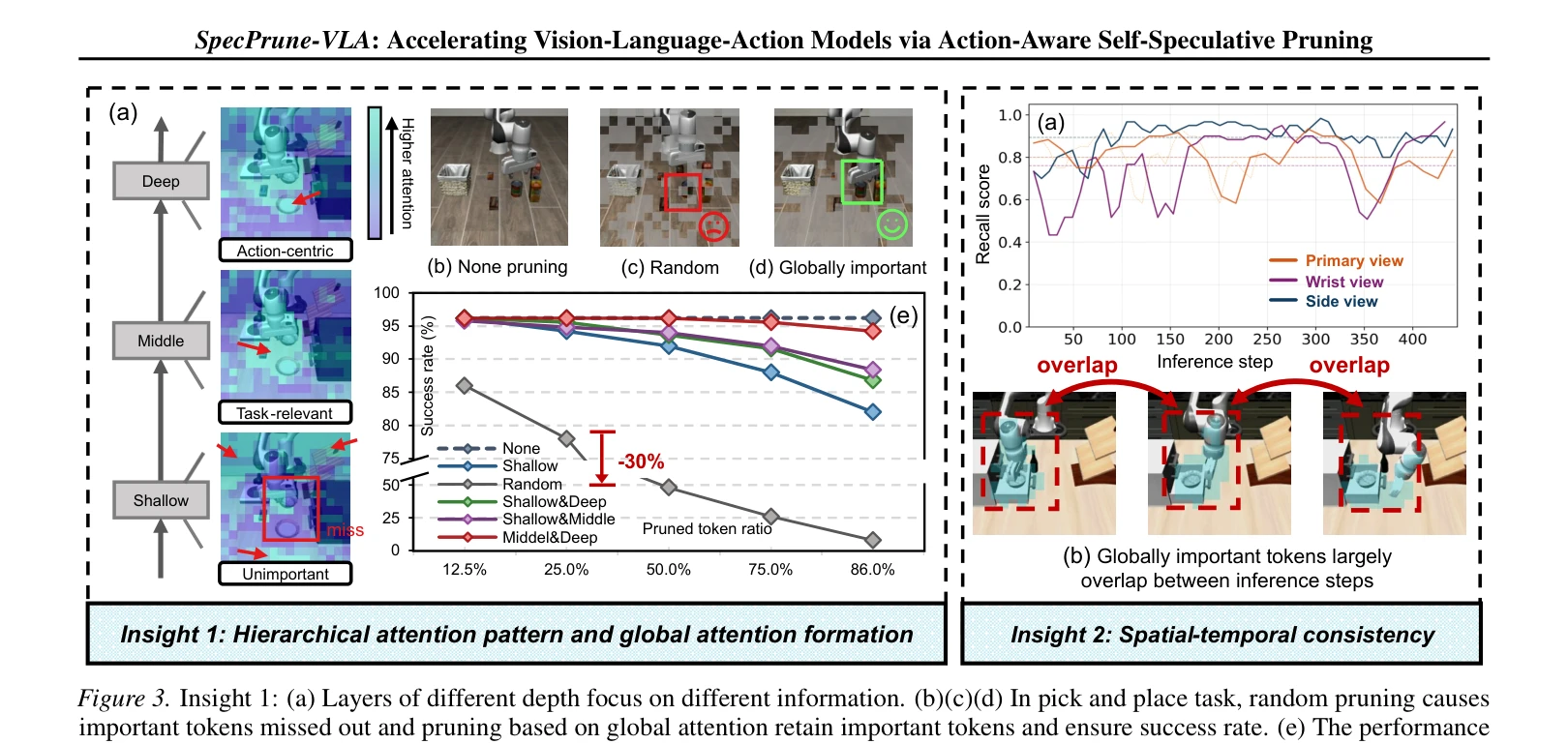
Essence
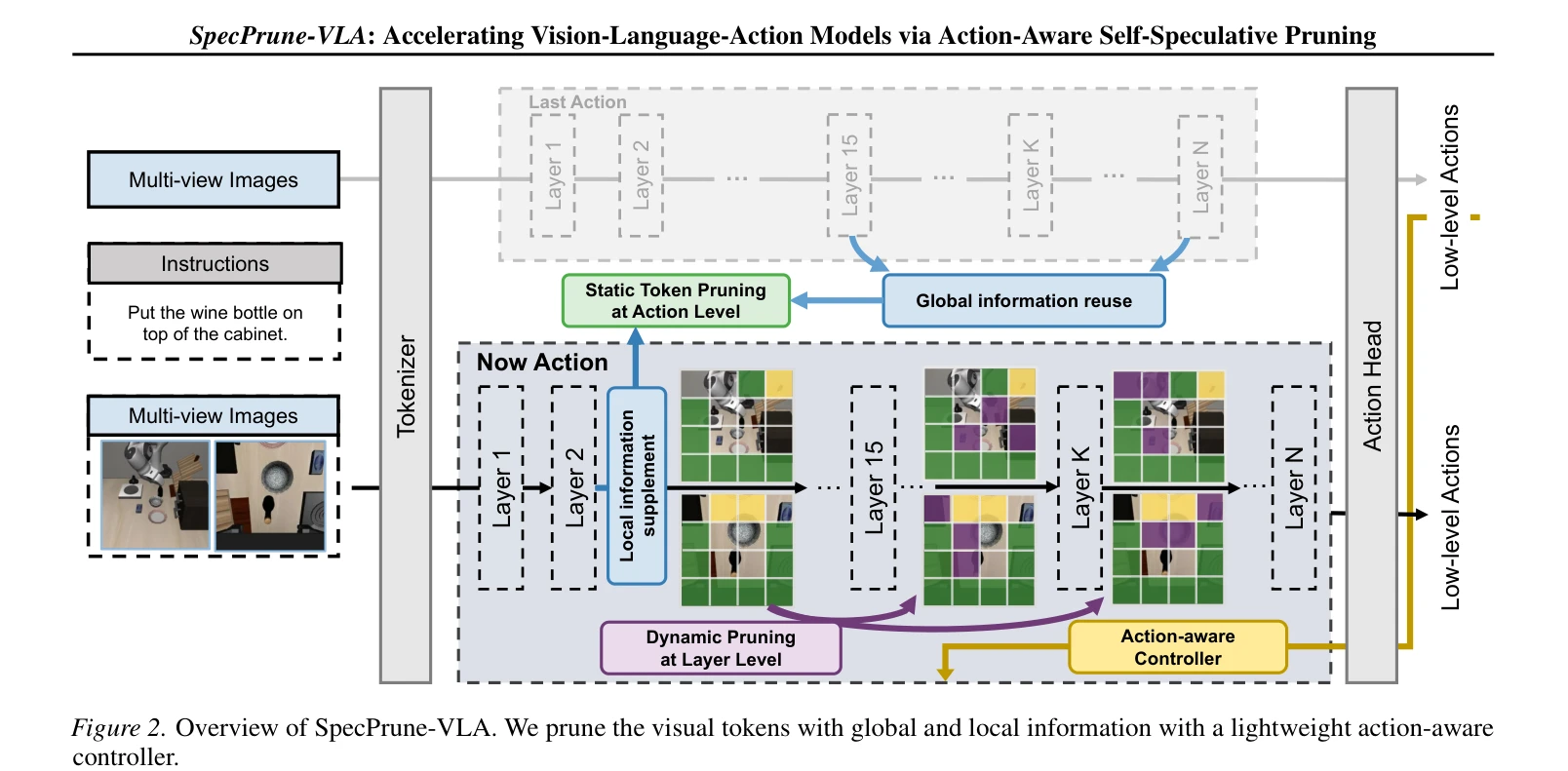
Figure 2. Overview of SpecPrune-VLA. We prune the visual tokens with global and local information with a lightweight act
SpecPrune-VLA는 Vision-Language-Action 모델의 LLM 추론을 가속화하기 위해 시간-공간 일관성을 활용한 액션-인식 자체-추측 토큰 프루닝 기법을 제안한다. 두 단계 프루닝(액션 레벨 정적 프루닝과 레이어 레벨 동적 프루닝)과 액션-인식 컨트롤러를 통해 최대 1.70배 속도 향상을 달성한다.