Essence
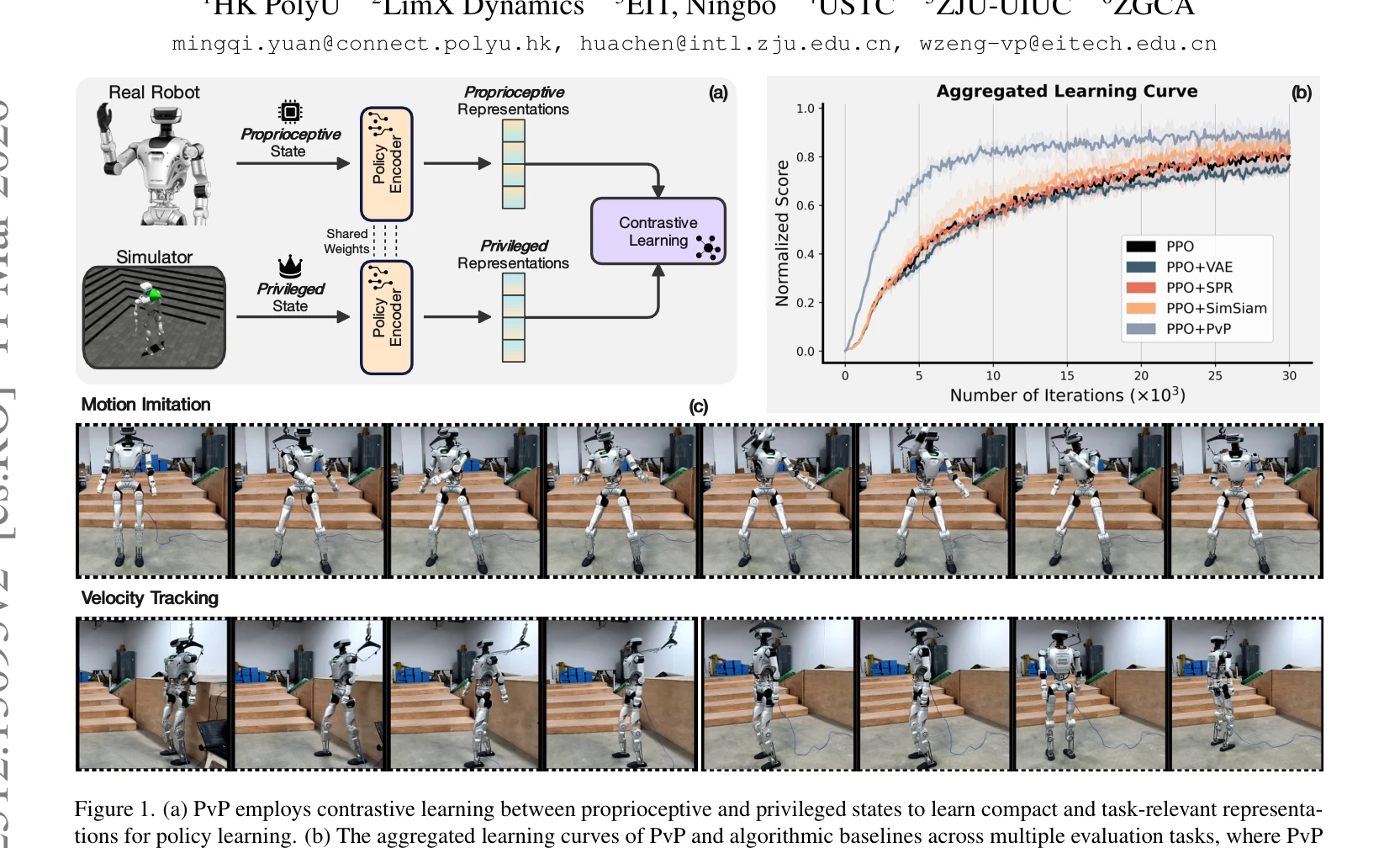
Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re
PvP는 고유 감각(proprioceptive)과 특권 상태(privileged state) 사이의 대조 학습을 활용하여 휴머노이드 로봇의 전신 제어(WBC) 학습의 샘플 효율성을 크게 향상시킨다.
저자: Mingqi Yuan, Tao Yu, Haolin Song, Bo Li, Xin Jin, Hua Chen, Wenjun Zeng | 날짜: 2026-03-11 | DOI: 10.48550/arXiv.2512.13093 📄 PDF
Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re
PvP는 고유 감각(proprioceptive)과 특권 상태(privileged state) 사이의 대조 학습을 활용하여 휴머노이드 로봇의 전신 제어(WBC) 학습의 샘플 효율성을 크게 향상시킨다.
Figure 1. (a) PvP employs contrastive learning between proprioceptive and privileged states to learn compact and task-re
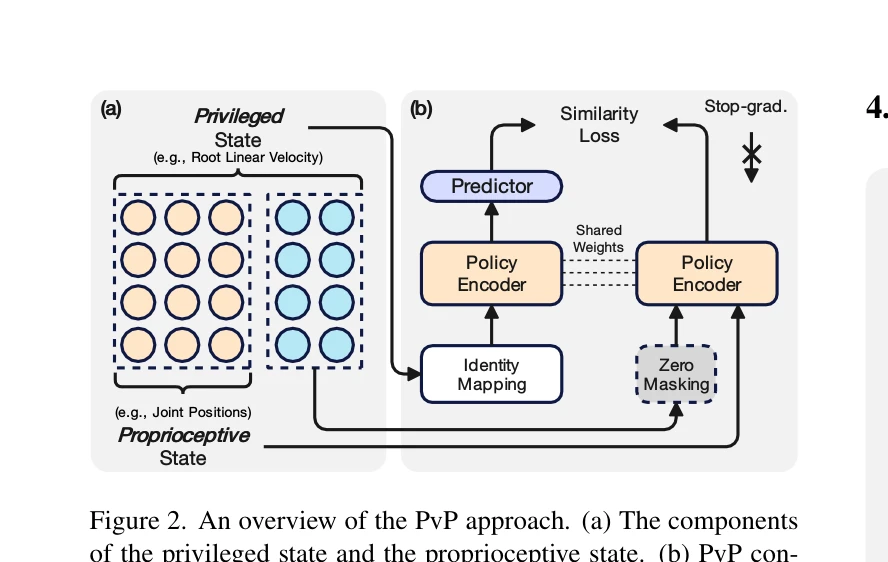
Figure 2. An overview of the PvP approach. (a) The components
총평: PvP는 proprioceptive-privileged 대조 학습이라는 직관적이면서도 효과적인 방법으로 휴머노이드 로봇 학습의 샘플 효율성을 크게 향상시키며, SRL4Humanoid 프레임워크는 해당 분야의 표준 도구로서 상당한 기여를 한다.