Essence
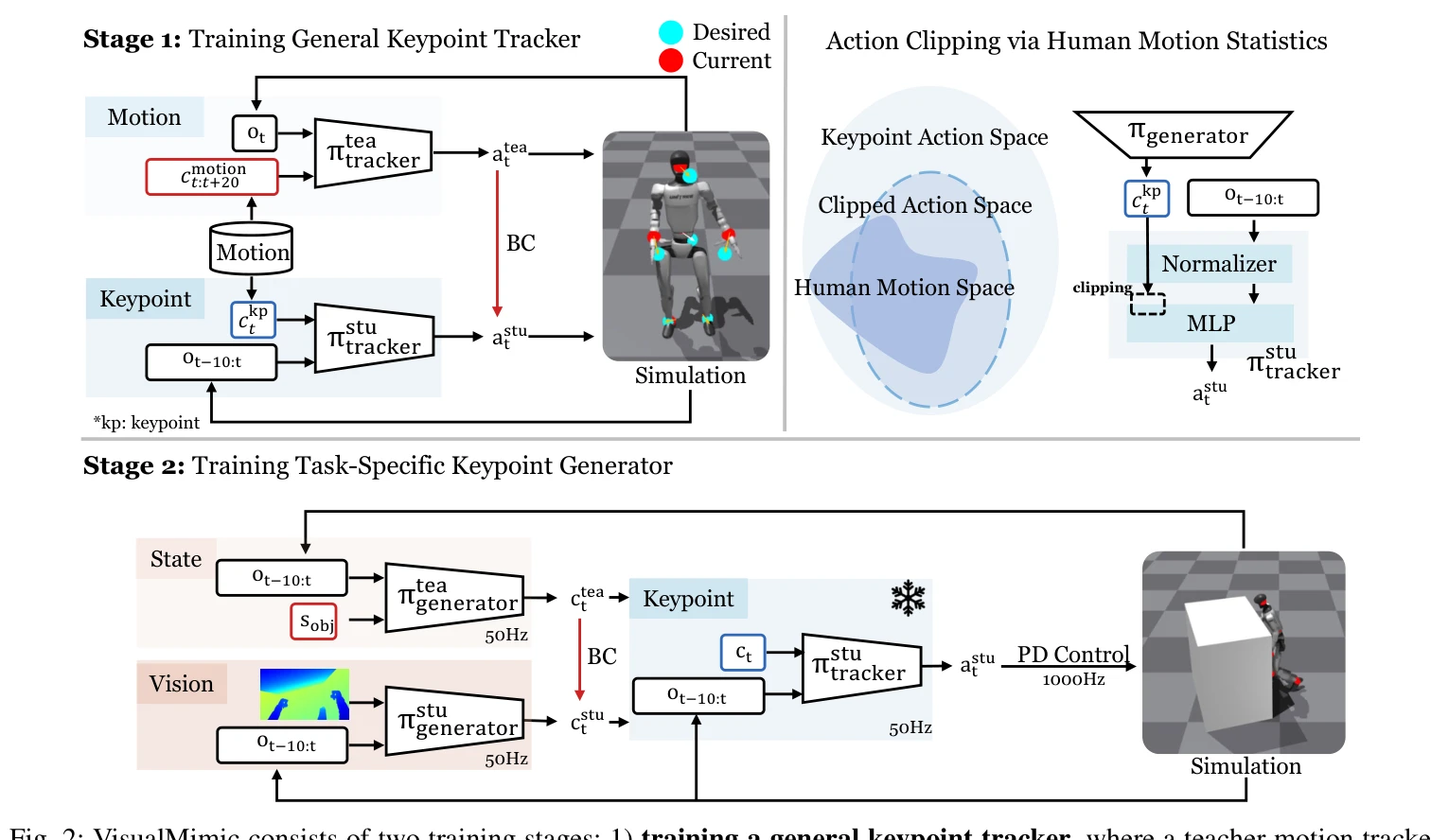
Fig. 2: VisualMimic consists of two training stages: 1) training a general keypoint tracker, where a teacher motion trac
VisualMimic은 egocentric vision과 hierarchical whole-body control을 결합한 sim-to-real 프레임워크로, 인간의 동작 데이터로 학습한 task-agnostic keypoint tracker와 task-specific visuomotor policy를 통해 humanoid robot의 loco-manipulation을 실현한다.
