Essence

Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from
인간형 로봇의 명령 추적과 외력 순응을 동시에 달성하기 위해 선호도 조건부 MORL 프레임워크를 제안하며, 단일 정책으로 추적-순응 간의 연속적인 trade-off를 구현한다.
저자: Tingxuan Leng, Yushi Wang, Tinglong Zheng, Changsheng Luo, Mingguo Zhao | 날짜: 2025-10-12 | URL: https://arxiv.org/abs/2510.10851 📄 PDF
Fig. 1: Preference-conditioned locomotion: A single policy realizes behaviors from
인간형 로봇의 명령 추적과 외력 순응을 동시에 달성하기 위해 선호도 조건부 MORL 프레임워크를 제안하며, 단일 정책으로 추적-순응 간의 연속적인 trade-off를 구현한다.
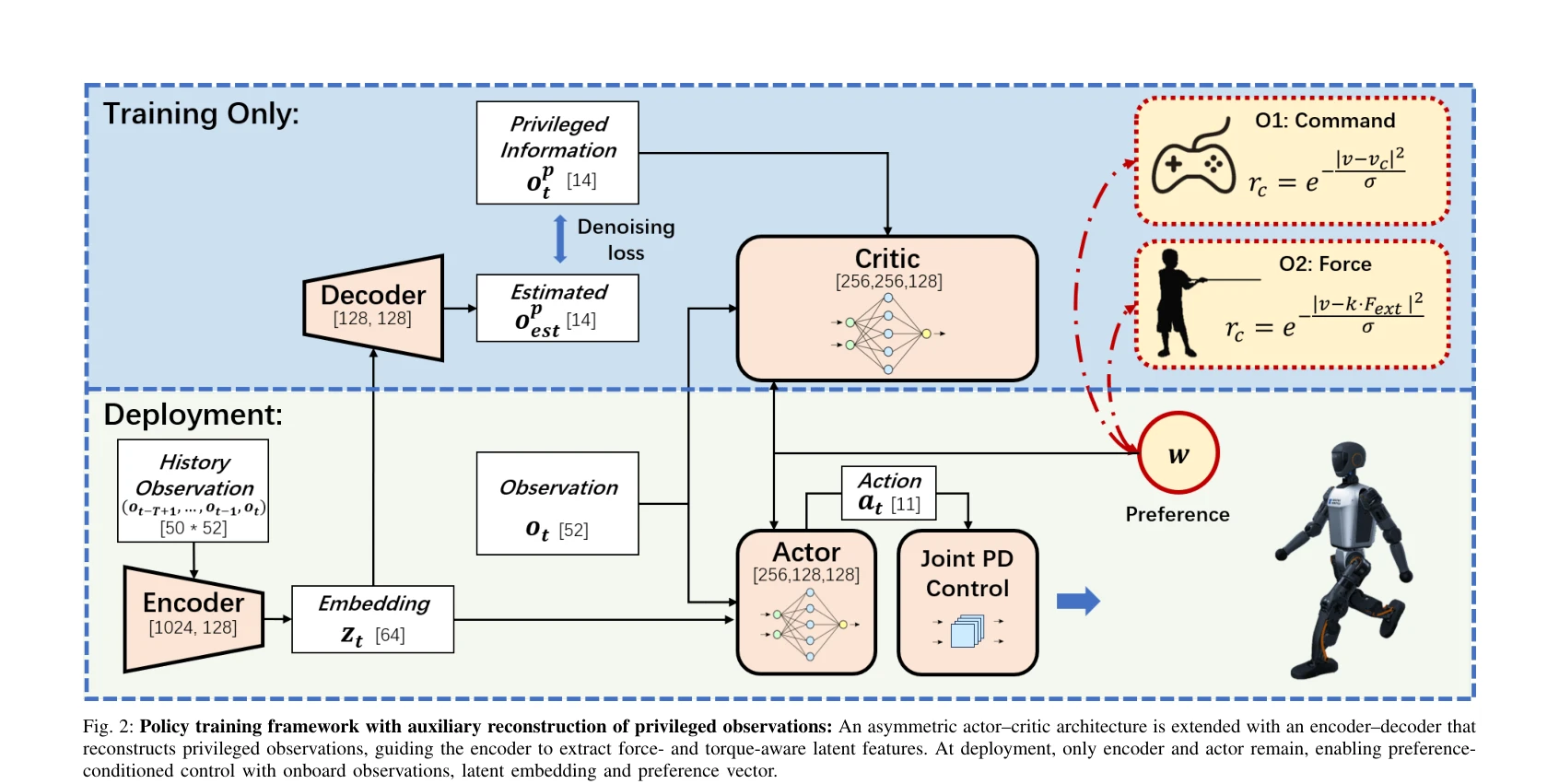
Fig. 2: Policy training framework with auxiliary reconstruction of privileged observations: An asymmetric actor–critic a
Fig. 2: Policy training framework with auxiliary reconstruction of privileged observations: An asymmetric actor–critic a
총평: 본 논문은 선호도 조건부 MORL을 통해 인간형 로봇 보행의 핵심 trade-off를 명시적으로 해결하는 창의적 접근법을 제시하며, velocity-resistance 모델링이라는 우아한 통합 기법과 실세계 검증을 통해 실제 배치 가능성을 입증한다. 다만 범위 제한(수평 평면, 선형 모델)과 단일 플랫폼 실험이 일반화 가능성에 대한 의문을 남긴다.