Essence
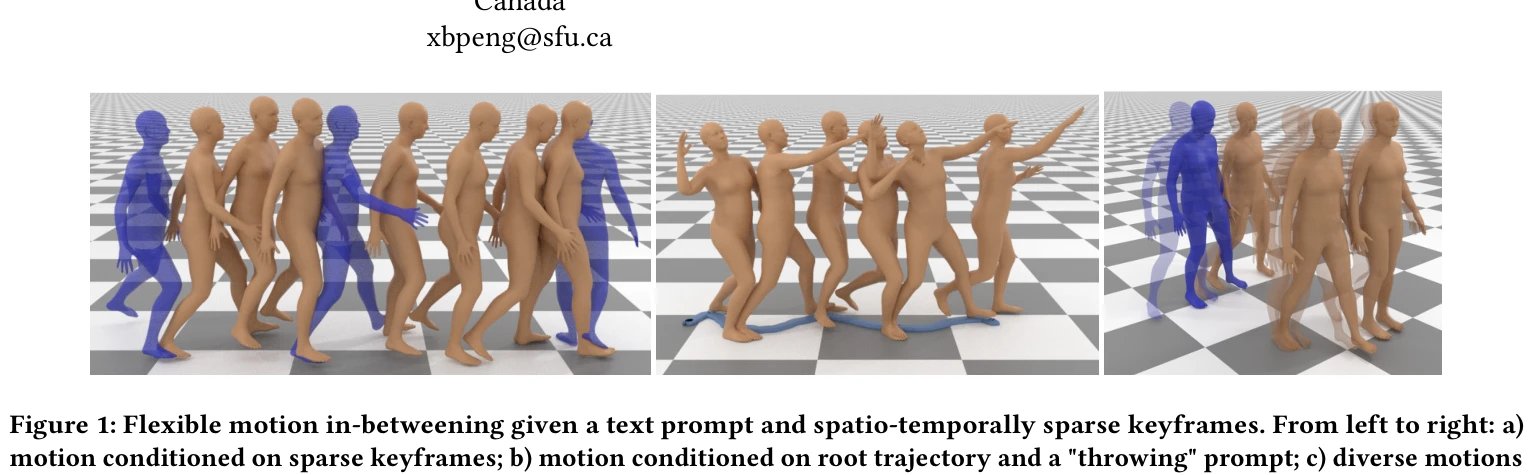
Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right:
CondMDI는 diffusion model 기반의 통합된 모션 인-비트위닝 방법으로, 텍스트 조건과 함께 유연한 keyframe 제약을 받아 다양하고 정밀한 인간 모션을 생성한다.
저자: Setareh Cohan, Guy Tevet, Daniele Reda, Xue Bin Peng, Michiel van de Panne | 날짜: 2024-05-17 | URL: https://arxiv.org/abs/2405.11126 📄 PDF
Figure 1: Flexible motion in-betweening given a text prompt and spatio-temporally sparse keyframes. From left to right:
CondMDI는 diffusion model 기반의 통합된 모션 인-비트위닝 방법으로, 텍스트 조건과 함께 유연한 keyframe 제약을 받아 다양하고 정밀한 인간 모션을 생성한다.
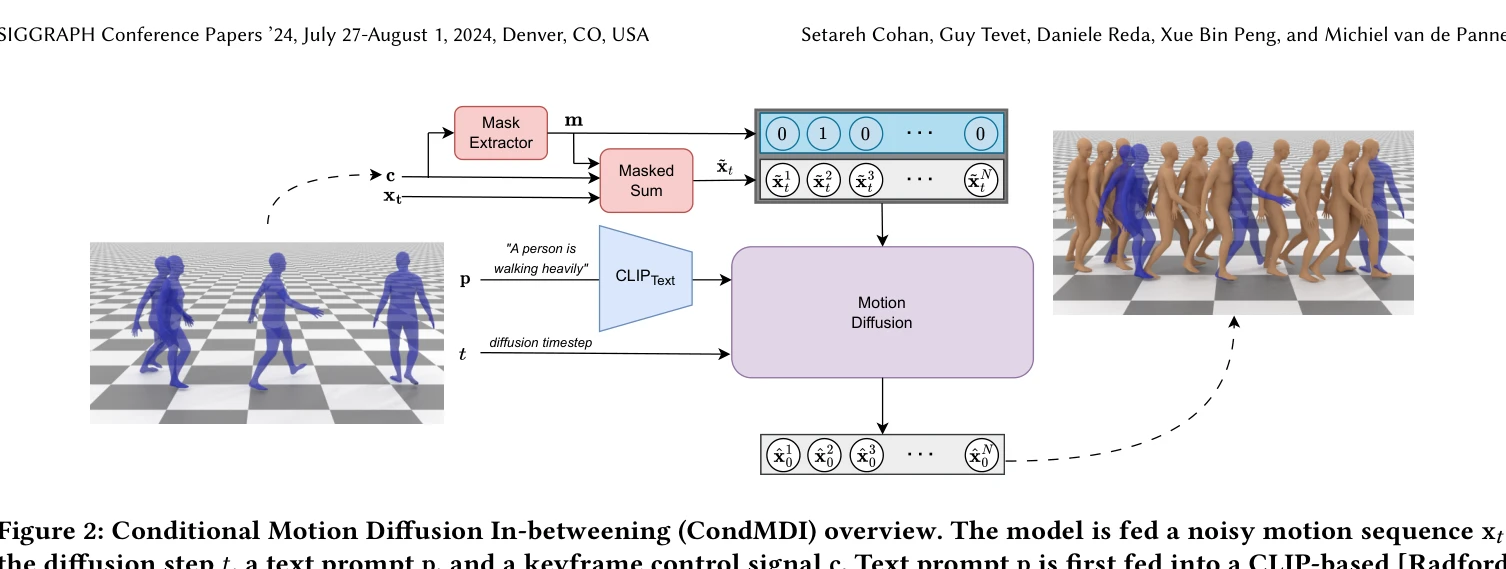
Figure 2: Conditional Motion Diffusion In-betweening (CondMDI) overview. The model is fed a noisy motion sequence x𝑡,
Figure 2: Conditional Motion Diffusion In-betweening (CondMDI) overview. The model is fed a noisy motion sequence x𝑡,
총평: CondMDI는 masked conditional diffusion model을 통해 motion in-betweening의 오랜 한계를 효과적으로 해결하며, 유연한 제약 처리와 텍스트 조건의 통합으로 실무적 가치가 높고 기술적으로도 우수한 기여를 제시한다.