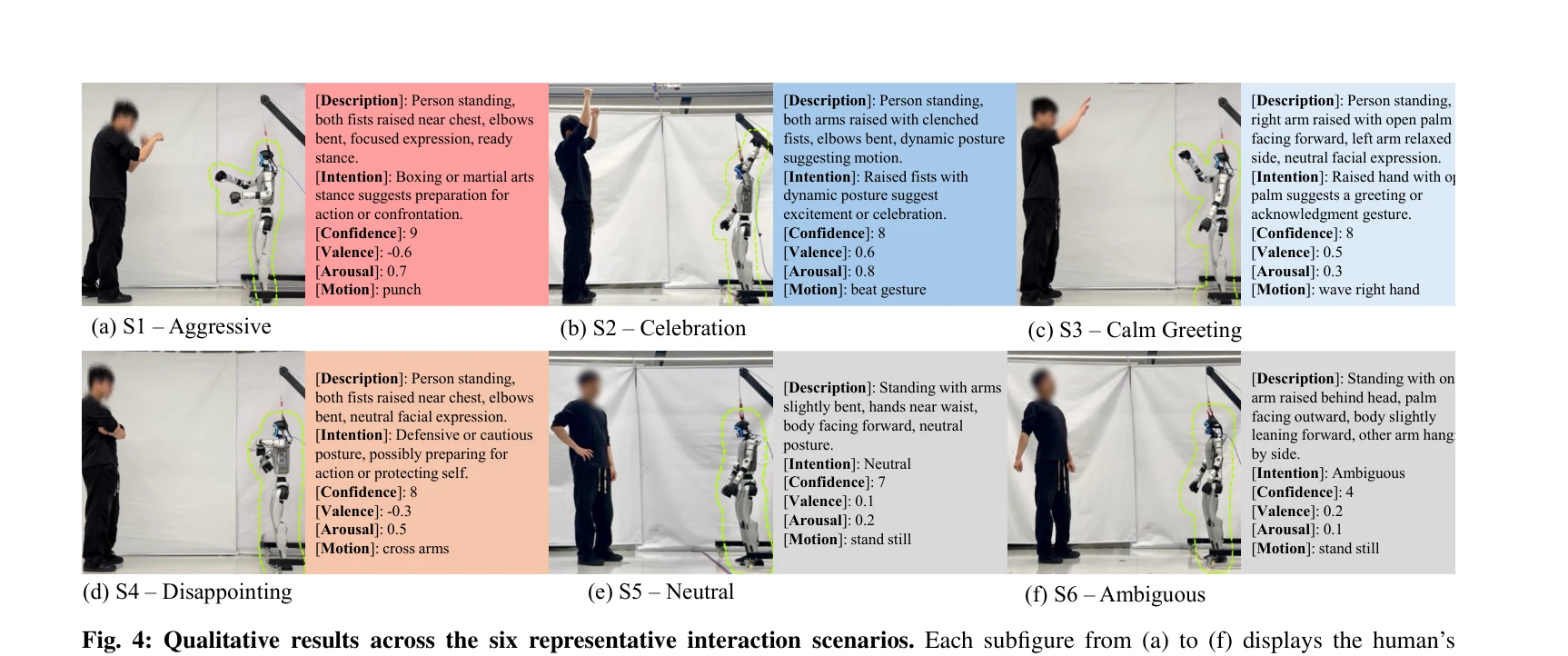
Essence
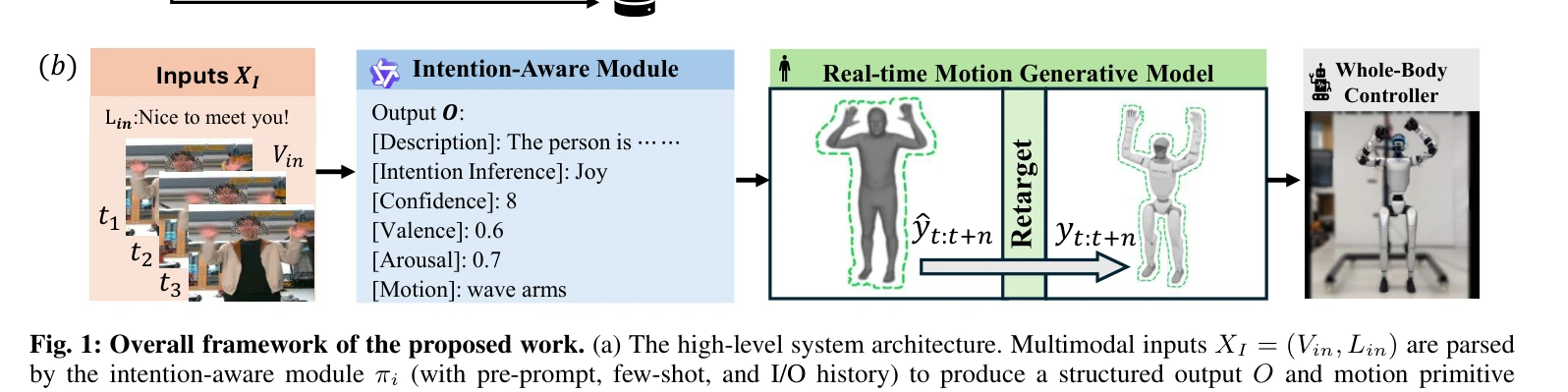
Fig. 1: Overall framework of the proposed work. (a) The high-level system architecture. Multimodal inputs XI = (Vin, Lin
본 논문은 Vision Language Model의 의도 추론과 diffusion 기반 동작 생성을 결합한 계층적 프레임워크 HIAER을 제안하여, 인간의 사회적 의도와 감정 맥락을 파악하고 실시간으로 표현적인 로봇 동작을 생성한다.