Essence
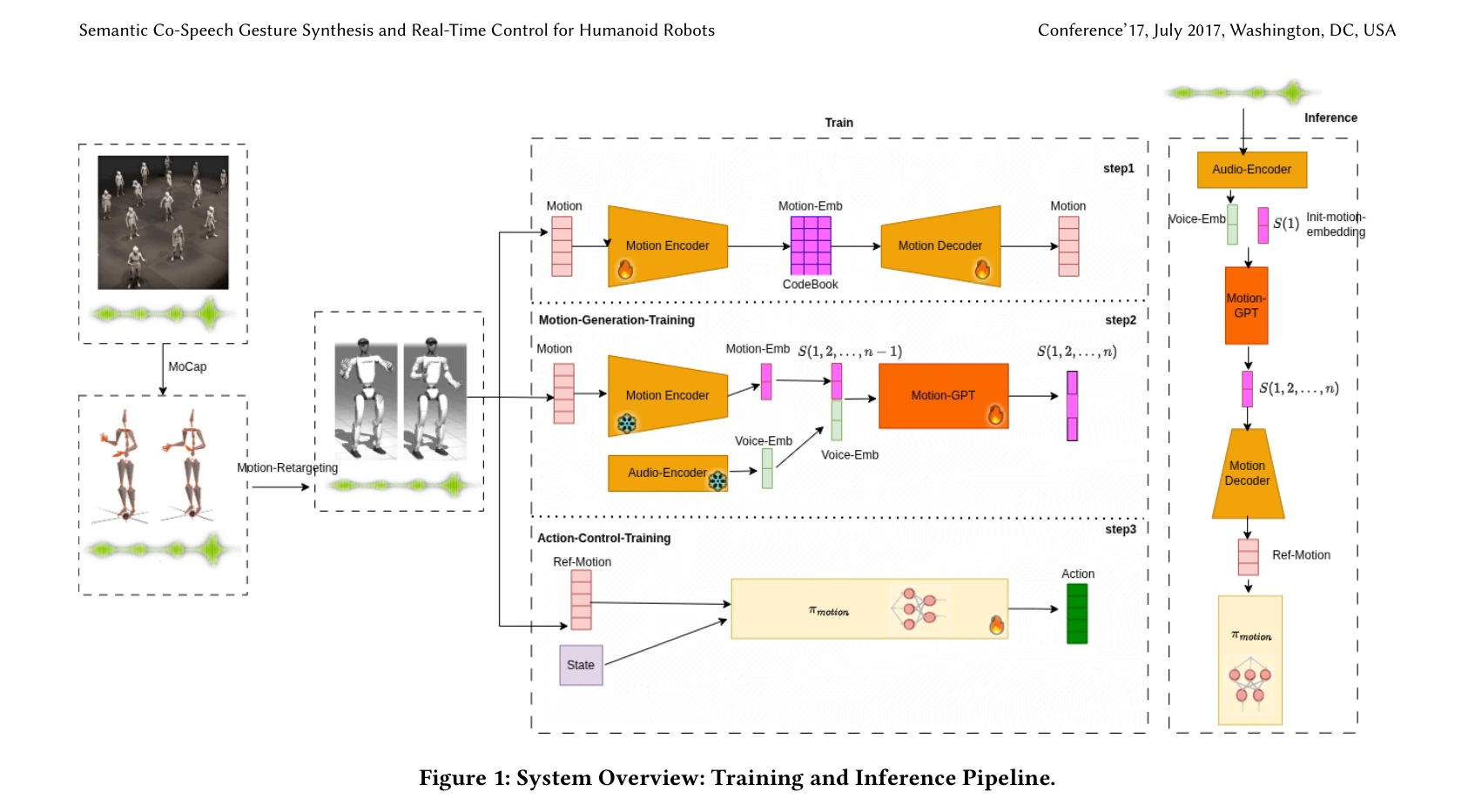
Figure 1: System Overview: Training and Inference Pipeline.
이 연구는 음성 입력으로부터 의미론적으로 적절한 제스처를 생성하고 실시간으로 휴머노이드 로봇에 배포하는 end-to-end 프레임워크를 제시한다. LLM과 Motion-GPT를 활용한 제스처 생성과 imitation learning 기반의 MotionTracker 제어 정책을 통합하여 의미 있는 비언어적 소통을 실현한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 이 논문은 음성 기반 의미론적 제스처 생성과 실시간 로봇 배포를 통합한 의미 있는 연구로, LLM, Motion-GPT, imitation learning을 창의적으로 결합하여 완전한 end-to-end 파이프라인을 실현했다. 다만 평가의 정량성 강화와 다양한 환경에서의 robustness 검증이 필요하다.