저자: Haoru Xue, Xiaoyu Huang, Dantong Niu, Qiayuan Liao, Thomas Kragerud, Jan Tommy Gravdahl, Xue Bin Peng, Guanya Shi, Trevor Darrell, Koushil Sreenath, Shankar Sastry | 날짜: 2025-06-16 | URL: https://arxiv.org/abs/2506.13751 📄 PDF
Essence

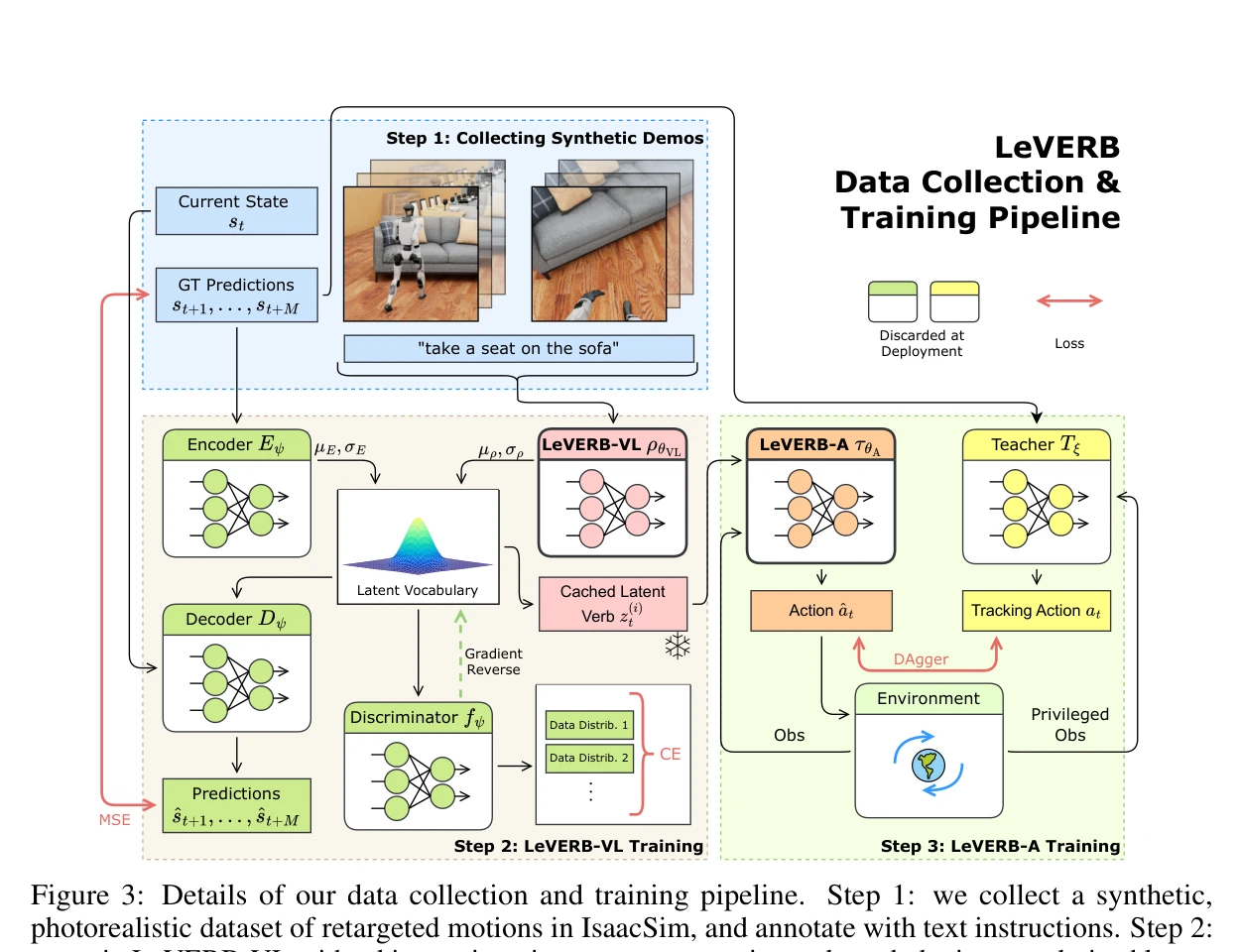
Figure 1: Overview of our contributions. Top: we create a photorealistic and dynamically accurate
LeVERB는 humanoid 로봇의 전신 제어를 위해 vision-language 입력을 latent action 공간으로 인코딩하는 계층적 프레임워크를 제안하며, 150개 이상의 task로 구성된 첫 번째 sim-to-real 준비 벤치마크를 제시한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: LeVERB는 humanoid WBC를 위한 vision-language 제어에서 중요한 진전을 이루었으며, 첫 latent instruction-following framework와 comprehensive sim-to-real 벤치마크를 제시하여 이 분야의 기초를 다졌다. 다만 실제 배포 성능의 추가 개선과 더 광범위한 task 평가를 통한 검증이 필요하다.