Essence
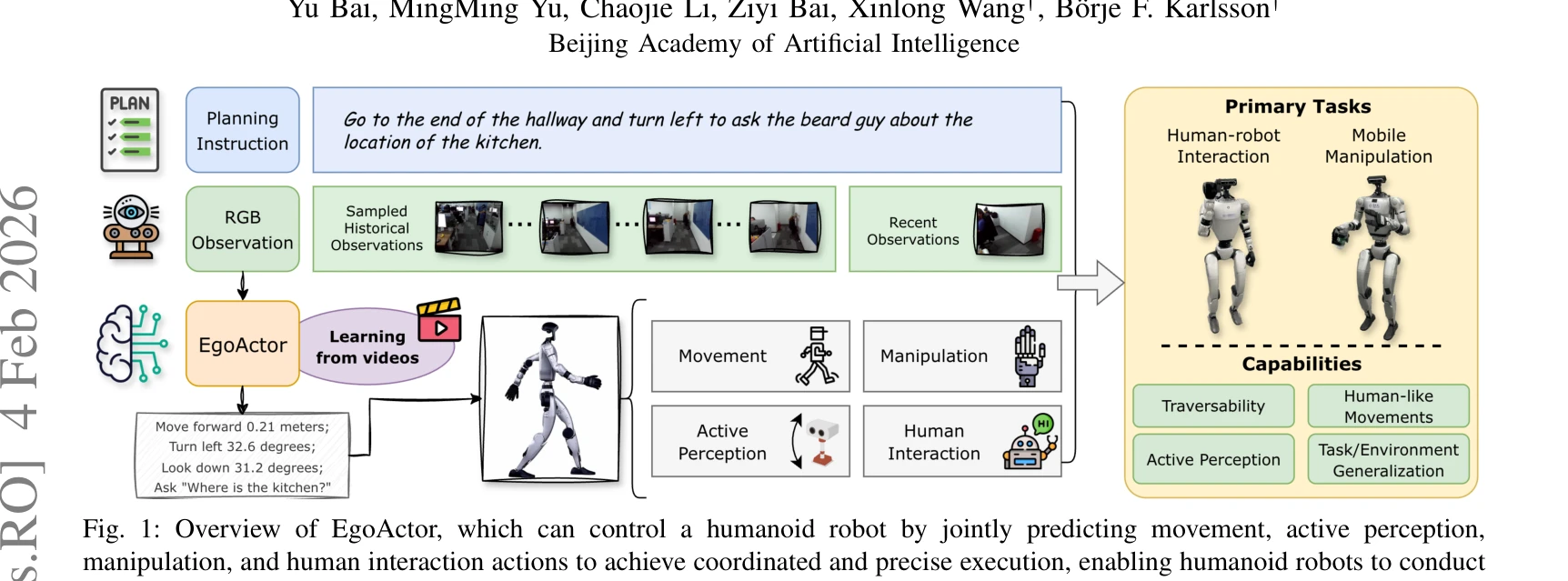
Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,
EgoActor는 VLM 기반의 통합 모델로서 고수준 자연어 명령어를 휴머노이드 로봇의 저수준 공간 인식 동작(보행, 조작, 지각, 인간-로봇 상호작용)으로 직접 변환하는 EgoActing 태스크를 제안한다.
저자: Yu Bai, MingMing Yu, Chaojie Li, Ziyi Bai, Xinlong Wang, Börje F. Karlsson | 날짜: 2026-02-04 | URL: https://arxiv.org/abs/2602.04515 📄 PDF
Fig. 1: Overview of EgoActor, which can control a humanoid robot by jointly predicting movement, active perception,
EgoActor는 VLM 기반의 통합 모델로서 고수준 자연어 명령어를 휴머노이드 로봇의 저수준 공간 인식 동작(보행, 조작, 지각, 인간-로봇 상호작용)으로 직접 변환하는 EgoActing 태스크를 제안한다.
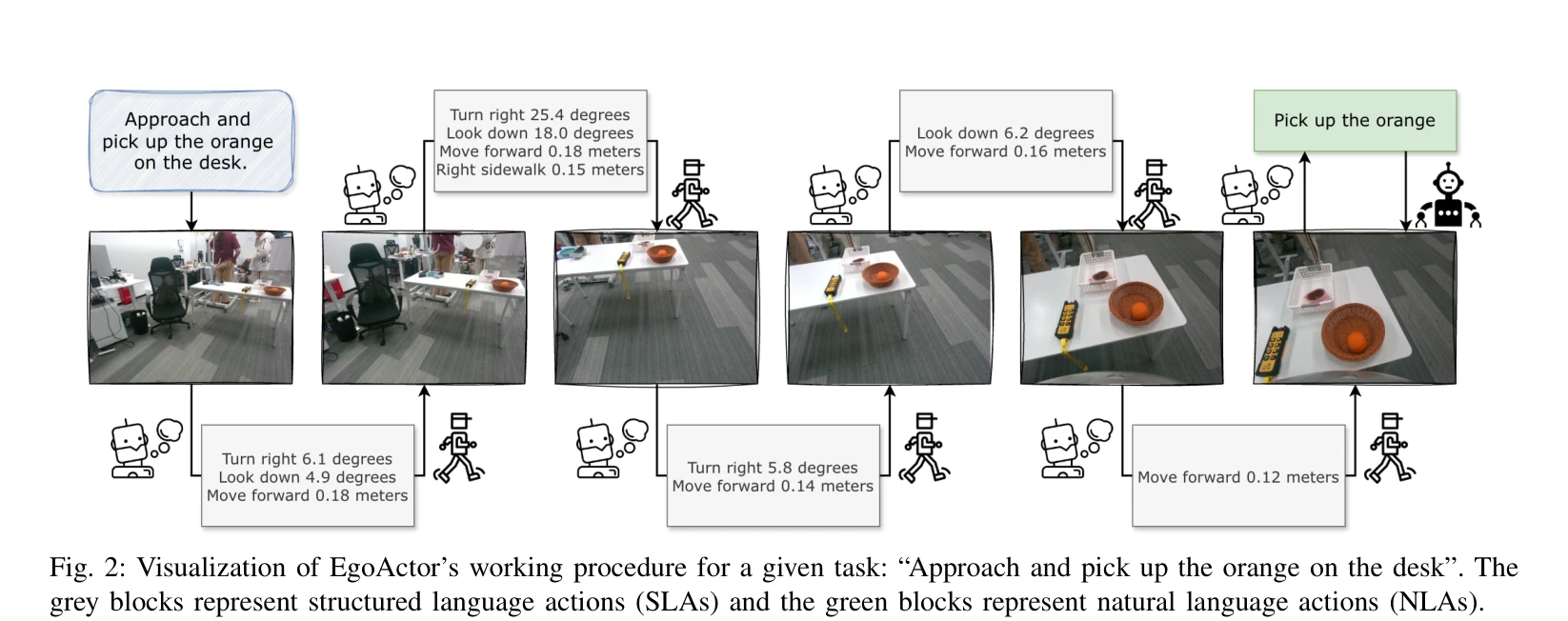
Fig. 2: Visualization of EgoActor’s working procedure for a given task: “Approach and pick up the orange on the desk”. T

Fig. 3: Example natural language actions (NLA) in EgoActing.
총평: EgoActor는 VLM을 활용한 휴머노이드 로봇 제어에서 보행, 조작, 지각, 상호작용을 통합하는 새로운 접근을 제시하며, 광범위한 실제 및 시뮬레이션 검증을 통해 그 가능성을 입증한다. 오픈소스 공개와 함께 휴머노이드 구체화 AI의 실질적 발전에 기여할 것으로 예상된다.